【论文翻译】PSENet:Shape Robust Text Detection with Progressive Scale Expansion Network
手动翻译仅供参考。
原文地址: https://arxiv.org/pdf/1806.02559.pdf
论文代码的开源地址:https://github.com/whai362/PSENet
Shape Robust Text Detection with Progressive Scale Expansion Network
0 摘要
目前文本框检测的鲁棒性面临两个挑战:一是大多数基于四边形边界的检测器很难将任意形状的文本包围在矩形中;二是大多数基于语义分割的检测器可能不会分离彼此非常接近的文本实例。为了解决这两者问题,我们提出了一种新颖的网络架构——渐进式规模扩展网络(progressive scale expansion network, psenet)。Psenet也是一种基于语义分割的检测器,但它对每个文本实例有多个不同尺度的预测。这些预测相当于通过将原始文本实例缩小为各种比例而产生的不同“内核”。由于这些最小内核之间存在很大的几何边缘,因此我们的方法可有效区分相邻的文本实例,并且对任意形状均具有鲁棒性。PseNet在ICDAR2015与ICDAR2017数据集中取得了目前最好的结果。值得注意的是,PSENet在曲线文本数据集(SCURT-CTW-1500)上的表现比之前的最佳记录高出绝对6.37%。
1 引言
近年来,自然场景文本检测因其具有大量的应用场景(场景理解、产品识别、自动驾驶、目标地理位置)得到了广泛的关注。然而由于自然场景的文本情况非常复杂,如光照、腐蚀、背景不同、角度差异、尺度不同,这些因素导致了自然场景下的文本识别面临着非常大的挑战。
随着卷积神经网络的发展,目前自然场景下的文本识别取得了长足的进步。目前基于边界框回归的一系列方法(如fast rcnn, faster rcnn, ssd等)虽然能够通过特定方向的矩形与四边形来定位文本目标,但它们对任意形状的文本实例检测能力较差,而然场景下的本文往往是不规则的(fig.b)。自然而然的,考虑将语义分割的方法用于曲线文本实例的检测问题中。虽然基于像素级分割的语义分割方法能够提取任意形状的文本实例边界,但它无法分离两个相距很近的文本实例(fig1.c)。为了解决这些问题,本文提出了一种渐进式规模扩展网络PSE-net.该网络有以下两个优势:

- 首先,Pse-net作为一种基于语义分割的算法是能够对任意形状的文本进行检测。
- 其次,我们提出了一种基于渐进式尺度扩展算法来解决临近文本实例的识别问题。(fig1.d)。具体来说,我们分配每个文本实例具有多个预测的分割区域。为了方便起见,我们在本文中将这些分割区域称为“内核”(kernel),对于一个文本实例,有几个对应的内核。每个内核与原始整个文本实例具有同样的尺寸,且位于同一中心点,但是尺度不同。(这部分具体可见标签生成部分)。为了获得最终的检测,我们采用渐进式尺度扩展算法,主要有以下三个步骤:
- 从最小尺度的kernel开始
- 逐步在更大的kernel中包含的像素来扩展其区域
- 直至扩展到最大尺度的kernel
采用这种渐进式尺度扩展主要基于以下四个方面的考虑:
- 最小尺度的kernel非常容易分离不同文本实例的边界,因此能够克服之前基于语义分割实现目标检测的无法分离相邻两个文本实例的弊端;
- 最大尺度的kernel能够提高检测的精度;
- kernel的尺度从小到大平滑增大,能够让网络更容易学习;
- 渐进式尺度扩展算法可确保文本实例的边界以仔细且渐进的方式扩展时准确定位。
为了量化PSE-net的检测效果,我们采用了3个基准数据集: ICDAR 2015 , ICDAR 2017 MLT 和 SCUTCTW1500。
这篇文章的主要贡献:
-
提出了PSE-net,基于这个算法能够对于任意边界的文本实例进行有效分割;
-
基于渐进式尺度扩展算法能够准确的对临近文本实例的分别分割;
-
提出的PSE-net在SCUTCTW1500数据集上取得了最好的预测效果,同时在 ICDAR 2015 ,和ICDAR 2017 MLT数据集上也取得了不错的效果。
2 相关工作(related work)
文本检测在计算机视觉领域很长时间都是一个研究的热点方向。…。稍微简要讲了目前的研究现状。
3 提出方法
在这个部分,我们首先介绍PSE-net整体的架构。随后我们详细论述了渐进式尺度扩展算法的实施细节,并且展示它是如何有效的区分非常临近的文本实例。随后我们介绍了标签数据的生成方法和损失函数的构建。最后我们对PSE-net的实施细节进行了阐述。
3.1 整体架构(overall pileline)
PSE-net的总体架构如图fig2所示。基于FPN网络的启发,我们将低水平的特征与高水平的特征合并到一起,从而得到四个不同水平的特征映射。这些蕴含不同感受野的特征映射(feature map)通过F进一步融合。直觉来看,这些特征融合和不同尺度kernel的形成非常类似。随后从特征映射F出发展开多个分支(S1,S2,…,Sn),每个分支都是一个语义分割的结果。分支选取的数量是超参数,将在3,3节中详细讨论。在这么多的分割结果中,S1是文本实例最小尺度的预测结果,Sn是最大尺度(没有缩放)的预测结果。在获得这些预测结果后,我们采用渐进式尺度扩展算法来获得最终的预测结果。
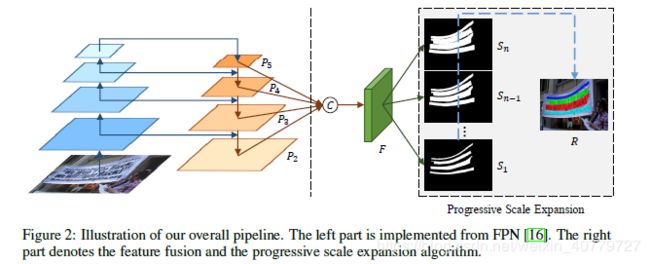
3.2 渐进尺度扩展算法
正如图fig1.c中所示,基于语义分割的文本检测算法很难分离相距非常近的文本实例。为了解决这个问题,我们提出了渐进式尺度拓展算法。
fig3是一个形象的例子来解释这个算法是如何工作的,它的核心思想是广度优先算法(breadth first search)。在这个例子中我们有三个分割的结果S={S1,S2, S3}。首先从最小尺度kernel的映射结果S1(fig3.a)开始,伴随四个不同的连接组件 C={c1,c2,c3,c4}。fig3.(b)中不同颜色的区域各自代表了这些不同的连接组件。现在我们可以看到所有文本实例的中心部分。随后我们采用渐进式尺度扩展算法来合并周围的像素到S2最后到S3。最终我们将用不同颜色标注本文实例的连接组件提取出来作为对文本实例最终的预测结果。
尺度扩展的过程在图fig.3(g)中有阐明。这个方法基于广度优先搜索算法,从不同尺度kernel像素开始逐步合并相邻的文本像素。可以预见的是,这样合并会发生像素分类的冲突(如fig3.g中红色框中所示),我们实际的解决方案是“先到先得”原则,即谁先合并到该像素就归谁所有。得益于渐进式尺度扩展的优势,这些边界上的冲突(conflict)并不会影响最终的检测效果。这个算法的细节实现方案见Algorithm1。


Algorithm符号说明:
- T,P: 中间结果(相对最终结果)即 intermediate results
- Q: 是一个队列
- Neighbor(·): 代表p的邻接像素
- GroupByLabel(·): 基于标签grouping中间结果
- Si[q] = True: 表示Si中的像素q属于文本实例
3.3 标签生成
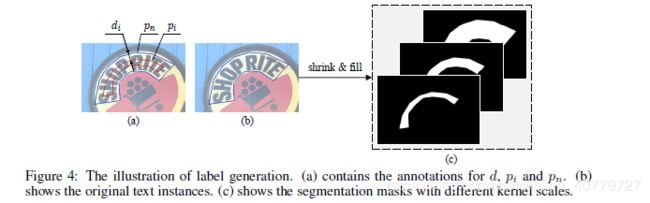
如Fig.2中的说明,PSE-net基于不同尺度的kernel产生了一系列的分割结果(S1,S2,…,Sn)。因此在数据集上也需要不同尺度的label对应(S1,S2,…,Sn)。通过实践我们发现,这些不同尺度的label可以通过缩小初始的文本实例来生成。fig4.b中的蓝色多边形代表初始的文本实例,它对应最大尺度的label(fig4.c中最里面的一张)。基于Vatti裁剪算法(Vatti clipping algorithm)生成不同尺度的label,最后进行二值化处理。将这一系列不同尺度的label用(G1,G2,…,Gn)表示。数值上,我如果要计算放缩比ri或pn到pi边缘之间的距离可以通过下式进行:
![]()
式中:
- Area(·): 表示多边形的面积
- Perimeter(·):表示多边形的参数(is the function of computing the polygon perimeter)
![]()
式中:
- m:表示最小尺度的放缩比,【0,1】
- n:选用多少个不同的尺度
放缩率(r1,r2,…,rn)由m,n两个超参数决定,线性m到1增加。
3.4 损失函数设置
为了学习PSE-net网络,损失函数设置如下:
![]()
可以看到损失函数由完整文本实例和放缩文本实例两部分组成,λ是超参数,用于平衡这两个损失。
我们知道,在自然图片中文本实例往往只占很小的区域(小目标检测),因此当使用交叉熵损失时,网络往往更加偏向非目标区域。因此我们采用dice系数,他的计算式如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ydnokral-1592011441911)(C:\Users\13068\AppData\Roaming\Typora\typora-user-images\1592008913194.png)]](http://img.e-com-net.com/image/info8/114bfbf87a2c411ea7e56d8af3076259.jpg)
此外自然图像中也有很多类似文字笔画的图案会带来干扰,如栅栏、格子等。因此我们对Lc损失中采用Online Hard Example Mining(OHEM)来更好的区分两者。
Lc损失关注分割结果中的文本和非文本区域,,我们将训练过程中基于OHEM得到的样本记为M,则Lc损失可以表述为:
![]()
Ls是压缩文本实例的损失。 由于压缩文本实例被完整文本实例的原始区域包围,因此我们忽略了分割结果Sn中非文本区域的像素,以避免了某些冗余。 因此,Ls可以表示如下:
![]()
式中:
- W:是一个标签,用于忽略Sn中非文本区域的像素
- S(n,x,y)指的是Sn中在(x,y)位置的像素值。
3.5 实现细节
PSENet的主干是从FPN [16]实现的。 我们首先从主干(backbone)中获得四个256通道特征图(P2,P3, P4, P5)(参考fig2)。 将P3,P4,P5上采样到P2的尺寸,然后基于深度方向拼接。随后将拼接得到的feature map送入到conv(3,3)+BN+RELU的卷积层中(通道256).最终输入到conv(1,1)+sigmoid(通道数是超参数,却决于采用多少个尺度)卷积层中作为最后的预测结果。
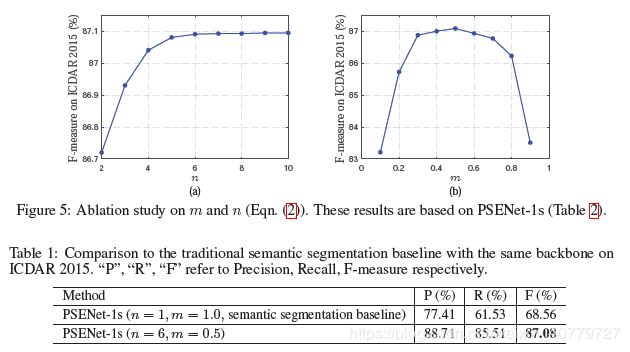
我们将n(采用尺度的个数)设置为6,将m(最小的放缩比例)设置为0:5,以生成标签。 在训练期间,我们将忽略所有数据集中标记为“请勿关注”的模糊文本区域。 损失函数的λ设置为0:7。 OHEM的负正比设置为3。
训练数据的数据增强如下:1)以(0.5,1,2,3)比例随机缩放图像;2)图像水平翻转并在(-10°,10°)范围内随机旋转;; 3)从变换后的图片随机裁剪640×640; 4)图片使用通道均值和标准差进行标准化。
对于四边形文本数据集,我们计算最小面积矩形以提取边界框作为最终预测。 对于曲线文本数据集,应用Ramer-Douglas-Peucker算法生成具有任意形状的边界框。
4 试验
在本节中,我们首先对PSE-Net进行消融研究。 然后,基于三个公开基准:ICDAR 2015,ICDAR 2017 MLT和SCUT-CTW1500将PSE-Net与许多最新方法进行比较。
4.1 基准数据集
介绍了下数据集的情况(有多少训练数据,测试数据之类)
4.2 训练
我们使用在ImageNet数据集上预先训练过的带有ResNet 的FPN作为我们的主干。通过使用随机梯度下降(SGD)训练所有网络。在ICDAR数据集的实验中,我们使用1000张IC15训练图像,7200张IC17-MLT训练图像和1800张IC17-MLT验证图像来训练模型,并在这两个数据集的测试集上计算精度,召回率和F指标。训练结束。我们使用批处理大小16,并训练模型300个epochs。初始学习率设置为10×(-3),并每100个epochs除以10。在SCUTCTW1500上,我们使用1000个训练图像从训练后的模型中微调模型训练400个epoch。批量大小设置为16。初始学习率设置为10-4,然后在200个epoch除以10。在微调结束后,我们在测试集上计算精度,召回率和F指标。我们使用5×10×(-4)的权重衰减和0.99的Nesterov动量。我们采用[5]引入的权重初始化。
4.3 消融研究
( 去掉提出的结构的网络与加上该结构的网络所得到的结果进行对比 )
-
Why are the multiple kernel scales necessary?
对比单核和多核的结果说明多核好。
-
How minimal can these kernels be?
基于跑的结果。
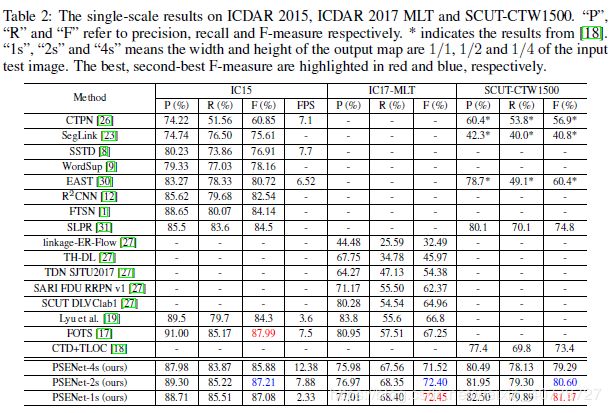
4.4 与最先进方法的对比
4.5 在SCUT-CTW1500数据集的对比


4.6 在ICDAR 2015 and ICDAR 2017 MLT更多的检测例子




5 结论与展望
我们提出了一种新颖的渐进式尺度扩展网络(PSE-net),以成功检测文本自然场景图像中具有任意形状的实例。 通过逐渐扩大检测范围通过多个语义分割图,从小内核到大内核实现文本实例的分割。我们的该方法对形状具有鲁棒性,可以轻松地区分非常接近或部分相交的文本实例。
未来有多个方向可以探索。 首先,我们将研究尺度扩展算法是否可以端到端地与网络一起训练。 其次,可以将渐进式尺度扩展算法引入一般的实例分割任务中,尤其是在那些拥挤的对象实例众多的标记中。