TensorFlow Object Detection API 技术手册(4)——使用摄像头进行实时目标检测
TensorFlow Object Detection API 技术手册(4)——使用摄像头进行实时目标检测
- (一)使用opencv开启摄像头
- (二)修改Demo代码
- (三)实时检测
- (四)完整代码
- (五)错误提示
(一)使用opencv开启摄像头
使用OpenCV打开摄像头并实时显示的代码如下:
import cv2
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
cv2.imshow('object detection', frame)
if cv2.waitKey(25) & 0xFF == ord('q'):
cv2.destroyAllWindows()
break
cap.release()
cv2.destroyAllWindows()
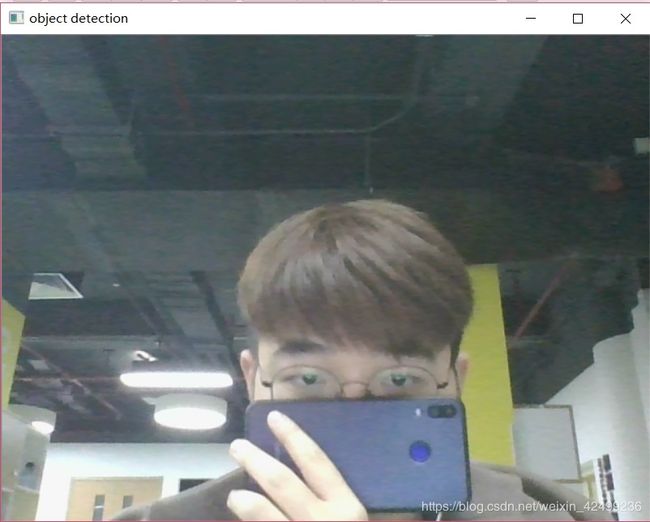
运行显示:
(二)修改Demo代码
要实现对场景的实时检测,我们只需要对Demo代码稍做修改即可
- 导入包
from object_detection.utils import visualization_utils as vis_util
from object_detection.utils import label_map_util
from distutils.version import StrictVersion
import tensorflow as tf
import numpy as np
import cv2
if StrictVersion(tf.__version__) < StrictVersion('1.9.0'):
raise ImportError('Please upgrade your TensorFlow installation to v1.9.* or later!')
- 开启摄像头
cap = cv2.VideoCapture(0)
- 添加模型位置和标签配置文件位置(使用COCO数据集训练的预训练模型)
PATH_TO_FROZEN_GRAPH = ''
PATH_TO_LABELS = ''
- 载入模型
detection_graph = tf.Graph()
with detection_graph.as_default():
od_graph_def = tf.GraphDef()
with tf.gfile.GFile(PATH_TO_FROZEN_GRAPH, 'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def, name='')
category_index = label_map_util.create_category_index_from_labelmap(PATH_TO_LABELS, use_display_name=True)
- 进行检测
with detection_graph.as_default():
with tf.Session(graph=detection_graph) as sess:
while True:
ret, image_np = cap.read()
# Expand dimensions since the model expects images to have shape: [1, None, None, 3]
image_np_expanded = np.expand_dims(image_np, axis=0)
image_tensor = detection_graph.get_tensor_by_name('image_tensor:0')
# Each box represents a part of the image where a particular object was detected.
boxes = detection_graph.get_tensor_by_name('detection_boxes:0')
# Each score represent how level of confidence for each of the objects.
# Score is shown on the result image, together with the class label.
scores = detection_graph.get_tensor_by_name('detection_scores:0')
classes = detection_graph.get_tensor_by_name('detection_classes:0')
num_detections = detection_graph.get_tensor_by_name('num_detections:0')
# Actual detection.
(boxes, scores, classes, num_detections) = sess.run(
[boxes, scores, classes, num_detections],
feed_dict={image_tensor: image_np_expanded})
# Visualization of the results of a detection.
vis_util.visualize_boxes_and_labels_on_image_array(
image_np, np.squeeze(boxes),
np.squeeze(classes).astype(np.int32),
np.squeeze(scores), category_index,
use_normalized_coordinates=True,
line_thickness=8)
cv2.imshow('object detection', image_np)
if cv2.waitKey(25) & 0xFF == ord('q'):
cv2.destroyAllWindows()
break
cap.release()
cv2.destroyAllWindows()
(三)实时检测
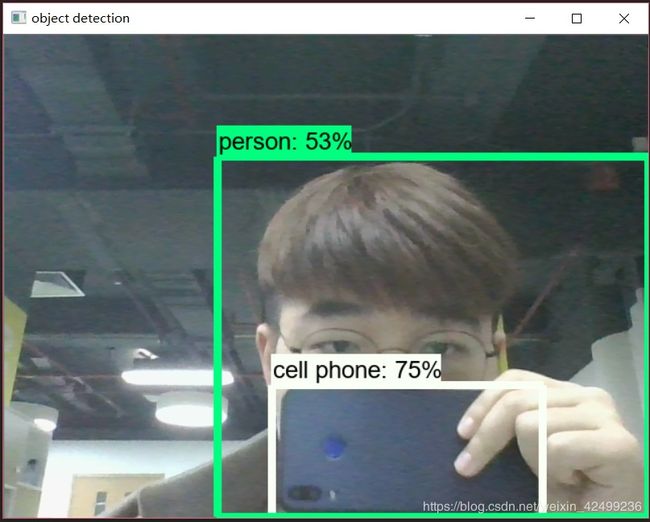
运行上述代码,如下图所示:
(四)完整代码
from object_detection.utils import visualization_utils as vis_util
from object_detection.utils import label_map_util
from distutils.version import StrictVersion
import tensorflow as tf
import numpy as np
import cv2
if StrictVersion(tf.__version__) < StrictVersion('1.9.0'):
raise ImportError('Please upgrade your TensorFlow installation to v1.9.* or later!')
# 开启摄像头
cap = cv2.VideoCapture(0)
# 添加模型位置和标签配置文件位置
PATH_TO_FROZEN_GRAPH = ''
PATH_TO_LABELS = ''
# 载入模型
detection_graph = tf.Graph()
with detection_graph.as_default():
od_graph_def = tf.GraphDef()
with tf.gfile.GFile(PATH_TO_FROZEN_GRAPH, 'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def, name='')
category_index = label_map_util.create_category_index_from_labelmap(PATH_TO_LABELS, use_display_name=True)
with detection_graph.as_default():
with tf.Session(graph=detection_graph) as sess:
while True:
ret, image_np = cap.read()
# Expand dimensions since the model expects images to have shape: [1, None, None, 3]
image_np_expanded = np.expand_dims(image_np, axis=0)
image_tensor = detection_graph.get_tensor_by_name('image_tensor:0')
# Each box represents a part of the image where a particular object was detected.
boxes = detection_graph.get_tensor_by_name('detection_boxes:0')
# Each score represent how level of confidence for each of the objects.
# Score is shown on the result image, together with the class label.
scores = detection_graph.get_tensor_by_name('detection_scores:0')
classes = detection_graph.get_tensor_by_name('detection_classes:0')
num_detections = detection_graph.get_tensor_by_name('num_detections:0')
# Actual detection.
(boxes, scores, classes, num_detections) = sess.run(
[boxes, scores, classes, num_detections],
feed_dict={image_tensor: image_np_expanded})
# Visualization of the results of a detection.
vis_util.visualize_boxes_and_labels_on_image_array(
image_np, np.squeeze(boxes),
np.squeeze(classes).astype(np.int32),
np.squeeze(scores), category_index,
use_normalized_coordinates=True,
line_thickness=8)
cv2.imshow('object detection', image_np)
if cv2.waitKey(25) & 0xFF == ord('q'):
cv2.destroyAllWindows()
break
cap.release()
cv2.destroyAllWindows()
(五)错误提示
使用jupyter运行时可能会报告以下错误,说feed_dict没有获取到数据:
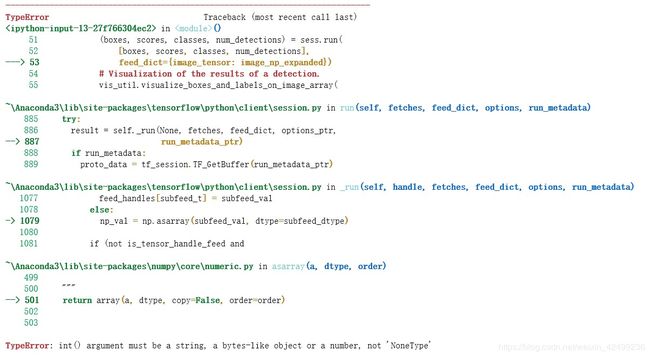
这是由于摄像头没有成功获取到图像的缘故,读者可以使用PyCharm运行完整代码,错误应该会消除。
下一节:TensorFlow Object Detection API 技术手册(5)——制作自己的目标检测数据集