【CVPR2020】可微分的NAS方法汇总
关注上方“深度学习技术前沿”,选择“星标公众号”,
资源干货,第一时间送达!

作者:yanwan
知乎链接:https://zhuanlan.zhihu.com/p/145560220
本文仅供学习参考,如有侵权,请联系删除!
深度学习解决了特征工程和权重优化的问题,
而神经网络架构搜索解决另一个问题——网络架构自动化。
NAS在优化的过程中,考量的因素有: mAP,memory,size,flops,lantency,带宽,平台等等。
例如,在一些移动端的硬件设备上面不支持对 depthwise conv的优化,比如说Edge TPU,高通 DSPs,那么实际跑出来的速度会比普通的 conv 要慢。因此需要考虑到了不同的平台(CPU, EdgeTPU, DSP,IPU)的影响。
NAS主要有进化算法、强化学习和微分三种主要的搜索方法。
虽然强化学习、进化算法可以搜索一个好的网络架构,但会耗费大量的计算资源,不经济也不环保。
而可微分的NAS方法能够以更少的成本达到SOTA,因此,获得了很多的关注。
Differentiable NAS
DNAS经典的算法就是大名鼎鼎的DARTS,通常可以描述为一个“双层”优化的问题:
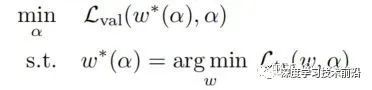
其中,a是架构的参数,w 是 a 对应的模型权重。a利用 validation data 来进行更新,w利用 training data 来进行更新。
DARTS 算法有一个严重的问题,就是当搜索轮数过大时,搜索出的架构中会包含很多的 skip-connect,从而性能会变得很差。我们把这个现象叫做 Collapse of DARTS。
DARTS 发生 Collapse 背后的原因是在两层优化中,a和 w 的更新过程存在先合作(cooperation)后竞争(competition)的问题。
在刚开始更新的时候,alpha 和 w 是一起被优化,从而 alpha 和 w 都是越变越好。
渐渐地,两者开始变成竞争关系,由于 w 在竞争中比 alpha 更有优势(比如,w 的参数量大于 alpha 的参数量),alpha 开始被抑制,因此网络架构出现了先变好后变差的结果。
因此,DARTS+ 提出了early stop的策略:
早停准则1:当一个 normal cell 中出现两个及两个以上的 skip-connect 的时候,停止搜索。
早停准则2:当各个可学习算子的架构排序足够稳定(比如 10 个 epoch 保持不变)的时候,停止搜索过。
#CVPR2020# FBNetV2:Differentiable Neural Architecture Search for Spatial and Channel Dimensions
代码地址: https://github.com/facebookresearch/mobile-vision
论文地址: https://arxiv.org/abs/2004.05565
在几乎不引入显存和计算量代价的情况下,FBNetV2的搜索空间相比于 FBNet 提升了将近10e14 倍,搜到了一个和 EfficientNet B0 精度接近,但是 FLOPs 小了 20% 的网络结构。
本文指出DNAS的方法有两个缺点:
(1)搜索空间比 RL,EAs方法的搜索空间要小。由于DNAS的 super graph 以及 featuremap 存在 GPU 上,显存的限制就使得 DNAS系列方法的搜索空间要小;
(2)搜索代价会随着选择增加而线性增长。增加 super graph一个新的搜索维度,搜索代价都会大幅增长,制约了搜索空间容量。
改进方向就是:使用 Channel Masking 和 Resolution Subsampling 提升搜索空间。
Channel Masking
之前的 DNAS 系列方法就是把不同的选项融进 supergraph,而作者为了减少搜索 channel 时候的计算量,构造了 channel masking的机制,把不同 channel 的最终输出,表征为和一个 mask 相乘的形式。

如上图所示,右边那个灰色的长方体表示一个 shape 为 (c, h, w) 的 tensor,和左边的 mask 向量 M 相乘的结果,M是和对应的 Gumbel Softmax 的系数的乘积和。通过调节左边的 m,就能得到等价的不同 channel 的结果。掩码乘法使用权重共享近似,可加快channel搜索速度。
Resolution Subsampling

X是网络的中间输出特征映射。使用最近邻从X进行子采样,再将A列中蓝色像素处的值组合为特征映射B。接下来运行F操作。最后,C中的每个值都放回D中的一个更大的特征映射。
通过上述的Channel masking 和 Resolution subsampling 机制,FBNet V2的搜索空间就可以在 channel 和 spatial 维度搜索了。最后的实验结果如下

#CVPR2020# MiLeNAS: Efficient Neural Architecture Search via Mixed-Level Reformulation
论文地址:https://arxiv.org/abs/2003.12238
代码地址:https://github.com/chaoyanghe/MiLeNAS
针对神经结构方法搜索的双层优化,未能收敛到最优解这一问题,本文提出了一个混合级别的有效的优化方法MiLeNAS。结果表明,即使在Mixed-Level Reformulation上使用简单的一阶方法,MiLeNAS也可以为NAS问题实现更低的验证错误。
此外,MiLeNAS提出了一个框架超过了DARTS,它通过基于模型大小的搜索和early stop策略仅需5h完成网络的搜索。
Mixed level Reformulation
单层优化,可能导致对a的过度拟合。因为α完全取决于训练数据,而训练集合测试集之间是存在差异的。
因此在综合了单层和双层优化后,选取一个折中方案,最终mixed-level优化变公式:

Beyond the DARTS Framework

Gradient-based Search Spaces
MiLeNAS分别对mixed-operation search space和sampling search space进行了评估,证明了MiLeNAS的适应性。

Model Size-based Searching
在一次运行中搜索不同模型大小的最优结构。具体地说,在搜索过程中,每一个epoch,我们跟踪模型大小和它的最佳验证精度,然后评估每一个epoch中最优架构的模型。
其优点是只需一个运行就可以得到多个不同参数大小的体系结构。
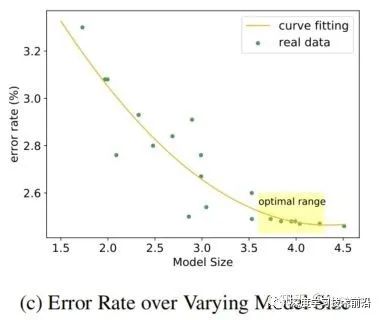
实验结果如下,可见精度和速度都有提升。

推荐阅读
(点击标题可跳转阅读)
Yolov3&Yolov4核心基础知识完整讲解
【目标检测基础积累】常用的评价指标
超越MobileNetV3!Facebook提出更轻更快的FBNetV2
【AAAI 2020】NAS+目标检测:SM-NAS 论文解读
谷歌 NAS + 目标检测:SpineNet论文详解
【汇总】一大波CVPR2020开源项目重磅来袭!
重磅!DLer-NAS交流群已成立!
欢迎各位Cver加入NAS微信交流群,本群旨在交流模型压缩/量化/剪枝、NAS、迁移学习、自监督学习、无监督学习、元学习等内容。欢迎对这些研究方向感兴趣的小伙伴加群一起交流学习!
加群请备注:研究方向+学校/公司+昵称(如NAS+上交+小明)

???? 长按识别添加,邀请您进群!