2018年安徽省大数据网络赛数据分析(三)
数据
36.63.116.201|sdk.conf.igexin.com|20170207161935|61.147.218.24;222.186.20.109;222.186.20.123|0
36.63.123.215|cm052.getui.igexin.com|20170207161935|183.131.1.82|0
36.63.132.38|mmbiz.qpic.cn|20170207161935|122.228.72.152;115.231.191.141;122.228.72.165;122.228.72.151;122.228.72.147;115.231.191.143;122.228.72.163;122.228.72.159;115.231.191.144;122.228.56.
157;122.228.72.166;122.228.56.155;122.228.72.164;122.228.56.156;115.231.191.142;122.228.72.148|0117.70.249.121|punch.p2p.qq.com|20170207161935|14.17.43.40|0
114.102.113.19|omgmta.play.t002.ottcn.com|20170207161935|123.151.179.173|0
36.63.40.131|pop.sjk.ijinshan.com|20170207161935|60.169.76.70;61.132.239.147;61.132.239.146|0
36.5.84.35|bird.sns.iqiyi.com|20170207161935|106.38.219.54;106.38.219.34|0
36.4.13.244|tx2.a.yximgs.com|20170207161935|61.191.60.17;61.191.60.16;61.191.60.19;61.191.60.18|0
36.4.151.103|r.vip.qq.com|20170207161935|14.215.138.24|0
223.244.111.107|supportcmsecurity1.ksmobile.com|20170207161935|221.228.204.21;119.147.146.70|0
数据说明:第二个字段为访问的网站地址,分隔符为‘|’
题目
统计该原始数据集中网站被访问次数最多的前5名的网站地址和次数
思路
在这里我想的是采用两个job,编写两个Mapper和两个Reducer,它们各自要实现以下功能:
第一个job:
- map():记录原始数据每行的网站地址如:sdk.conf.igexin.com,并将其出现次数标记为1。输出sdk.conf.igexin.com 1
- reduce():将map端传来的数据,进行次数的累加。输出sdk.conf.igexin.com 9.这里的次数只是为了说明思路,实际上有可能并不是这些。
第二个job:
- map():将第一个job的reduce端传来的数据交换key与value,并按照key次数进行倒序排序。输出: 9 sdk.conf.igexin.com
- reduce(): 将所有具有相同访问次数的网站地址进行连接。如{9,{sdk.conf.igexin.com,cm052.getui.igexin.com}这样的形式。
实际上我们这里采用了MapReduce组合式计算作业中的迭代式计算
MapReduce迭代式计算的中心思想就是前一个MapReduce的输出结果将作为下一个MapReduce的输入,任务完成后中间结果都可以删除。例如,现在有3个MapReduce子任务,其中子任务1的输出目录Outpath1将作为子任务2的输入目录,而子目录2的输出目录Outpath2又将作为子任务3的输入目录。设置代码如下:
Configuration conf = new Configuration();
//子任务1配置代码
Job job1 = Job.getInstance(conf, "job1");
......
FileInputFormat.addInputPath(job1,new Path(args[0]));
FileOutputFormat.setOutputPath(job1,new Path(args[1]));
job1.waitForCompletion(true);
//子任务2配置代码
Job job2 = Job.getInstance(conf, "job2");
......
FileInputFormat.addInputPath(job2,new Path(args[1]));
FileOutputFormat.setOutputPath(job2,new Path(args[2]));
job2.waitForCompletion(true);
//子任务3配置代码
Job job2 = Job.getInstance(conf, "job3");
......
FileInputFormat.addInputPath(job3,new Path(args[2]));
FileOutputFormat.setOutputPath(job3,new Path(args[3]));
job3.waitForCompletion(true);
子任务作业配置代码运行后,会按顺序执行每个子作业,由于后一个子任务需要使用前一个子任务的输出结果,因此,每一个子任务需要等到前一个子任务执行完成后才能执行,这是通过job.waitForCompletion(true)方法实现的。
代码
package com.mr2;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class FenTwo
{
/*数据:
36.63.116.201|sdk.conf.igexin.com|20170207161935|61.147.218.24;222.186.20.109;222.186.20.123|0
36.63.123.215|cm052.getui.igexin.com|20170207161935|183.131.1.82|0
*/
//第一个map()方法将数据处理为<网站地址,出现1次>
public static class MyMapperOne extends Mapper<LongWritable,Text,Text,IntWritable>
{
protected void map(LongWritable k1,Text v1,Context context) throws IOException, InterruptedException
{
IntWritable one = new IntWritable(1);
String s = v1.toString();
String[] split = s.split("\\|");
context.write(new Text(split[1]), one);
}
}
//第一个reduce()方法将传来的数据处理为<网站地址,出现总次数>
public static class MyReduceOne extends Reducer<Text,IntWritable,Text,IntWritable>
{
protected void reduce(Text k2, Iterable<IntWritable> v2,Context context) throws IOException, InterruptedException
{
int sum = 0;
for(IntWritable val : v2)
{
sum += val.get();
}
context.write(k2, new IntWritable(sum));
}
}
//第二个map()方法将第一个Reduce传来的数据处理为<出现总次数,网站地址>这样最终的输出结果就可以按照次数排序
public static class MyMapperTwo extends Mapper<LongWritable,Text,IntWritable,Text>
{
protected void map(LongWritable k3, Text v3,Context context) throws IOException, InterruptedException
{
String s = v3.toString();
String[] split = s.split("\t");
int m = Integer.parseInt(split[1]);
context.write(new IntWritable(m),new Text(split[0]));
}
}
//利用这个类实现出现次数的倒序排序
public static class MyNumberComparator extends IntWritable.Comparator
{
@Override
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2)
{
// TODO Auto-generated method stub
return -super.compare(b1, s1, l1, b2, s2, l2);
}
}
//第二个reduce()方法将数据处理为<出现总次数,{网站地址1,网站地址2,,,,,,}>
public static class MyReduceTwo extends Reducer<IntWritable,Text,IntWritable,Text>
{
protected void reduce(IntWritable k4, Iterable<Text> v4,Context context) throws IOException, InterruptedException
{
StringBuffer s = new StringBuffer();
for(Text val : v4)
{
String m = val.toString();
s.append(m+",");
}
//利用substring()将value后面的","给去了
String s1 = s.substring(0, s.length()-1);
context.write(k4, new Text(s1));
}
}
public static void main(String args[]) throws IOException,ClassNotFoundException,InterruptedException
{
Configuration conf = new Configuration();
Job job1 = Job.getInstance(conf, "job1");
job1.setJarByClass(FenTwo.class);
job1.setMapperClass(MyMapperOne.class);
job1.setReducerClass(MyReduceOne.class);
job1.setMapOutputKeyClass(Text.class);
job1.setMapOutputValueClass(IntWritable.class);
job1.setOutputKeyClass(Text.class);
job1.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job1,new Path(args[0]));
FileOutputFormat.setOutputPath(job1,new Path(args[1]));
job1.waitForCompletion(true);
Job job2= Job.getInstance(conf, "job2");
job2.setJarByClass(FenTwo.class);
job2.setMapperClass(MyMapperTwo.class);
job2.setSortComparatorClass(MyNumberComparator.class);
job2.setReducerClass(MyReduceTwo.class);
job2.setMapOutputKeyClass(IntWritable.class);
job2.setMapOutputValueClass(Text.class);
job2.setOutputKeyClass(IntWritable.class);
job2.setOutputValueClass(Text.class);
//将第一输出文件的路径作为第二个的文件输入路径
FileInputFormat.addInputPath(job2 ,new Path(args[1]));
FileOutputFormat.setOutputPath(job2,new Path(args[2]));
job2.waitForCompletion(true);
}
}
执行命令
因为从来没有使用过这个方法,所以第一开始时我使用了命令hadoop jar jar包名 所运行的类 /输入路径 /输出路径运行jar包,运行后出现了Exception in thread “main” java.lang.ArrayIndexOutOfBoundsException: 2的错误,后来经百度是因为在执行的过程中需要3个输入,而在初始化时只申请了2个位置。
后来在无意中使用了hadoop jar jar包名 所运行的类 /输入路径1 /输出路径1(输入路径2) /输出路径2 这样的方法最后运行成功。
hadoop jar three.jar com/mr2/FenTwo /Mrone/dns_log.txt /tmp/20 /tmp/21
结果
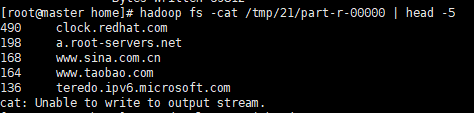 因为题目要求是排名前五的,所以这里直接使用了| head -5命令这样就可以不用在程序中对其进行处理了。
因为题目要求是排名前五的,所以这里直接使用了| head -5命令这样就可以不用在程序中对其进行处理了。