Kafka(分布式发布订阅消息系统) 简介
原文链接:https://mp.toutiao.com/profile_v3/graphic/preview?pgc_id=6854137793556251147
本文主要从以下几个方面介绍分布式发布订阅消息系统
一、什么是Kafka
二、kafka的特性
三、kafka的使用场景
四、kafka中相关术语介绍
五、kafka相关机制
六、kafka的Demo
一、什么是kafka
Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop的批处理系统、低延迟的实时系统、storm/Spark流式处理引擎,web/nginx日志、访问日志,消息服务等等,用scala语言编写,Linkedin于2010年贡献给了Apache基金会并成为顶级开源 项目。
二、kafka的特性
1、通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
2、高吞吐量 :即使是非常普通的硬件Kafka也可以支持每秒数百万的消息。
3、支持通过Kafka服务器和消费机集群来分区消息。
4、支持Hadoop并行数据加载
三、Kafka使用场景
1、缓冲和削峰:在实时数据处理时,可以使用kafka作为一个数据缓冲存储单元。当上游数据时有突发流量,下游可能扛不住,或者下游没有足够多的机器来保证冗余,kafka在中间可以起到一个缓冲的作用,把消息暂存在kafka中,下游服务就可以按照自己的节奏进行慢慢处理。
2、解耦和扩展性:项目开始的时候,并不能确定具体需求。消息队列可以作为一个接口层,解耦重要的业务流程。只需要遵守约定,针对数据编程即可获取扩展能力。
3、冗余:可以采用一对多的方式,一个生产者发布消息,可以被多个订阅topic的服务消费到,供多个毫无关联的业务使用。即一个数据可以供不同分组内的消费者读取n份,但是同一分组内的消费者只会读取1次。
4、健壮性:消息队列可以堆积请求,所以消费端业务即使短时间死掉,也不会影响主要业务的正常进行。当处理数据的业务挂了之后,再次恢复之后可以从上次未处理的数据开始继续处理。
5、异步通信:很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
四、kafka相关术语
- Broker Kafka集群包含一个或多个服务器,这种服务器被称为broker。
- Topic 每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可,生产或消费数据而不必关心数据存于何处)
- Partition Partition是物理上的概念,每个Topic包含一个或多个Partition.
- Producer 消息生产者,负责发布消息到Kafka broker
- Consumer 消息消费者,向Kafka broker读取消息的客户端。
- Consumer Group 每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)
- Offset, 消息存储在Kafka的Broker上,消费者拉取消息数据的过程中需要知道消息在文件中的偏移量,这个偏移量就是所谓的Offset
五、kafka相关机制
1 、消息传输流程
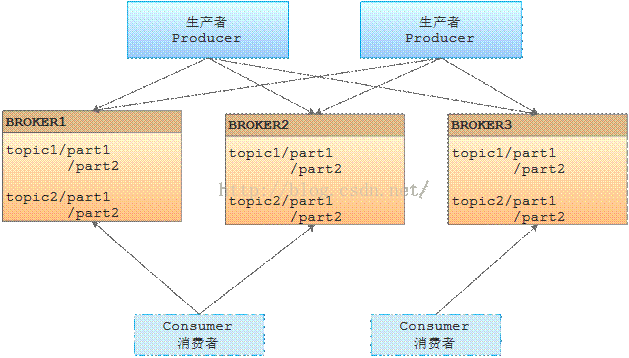
Kafka消息系统生产者和消费者部署关系图1
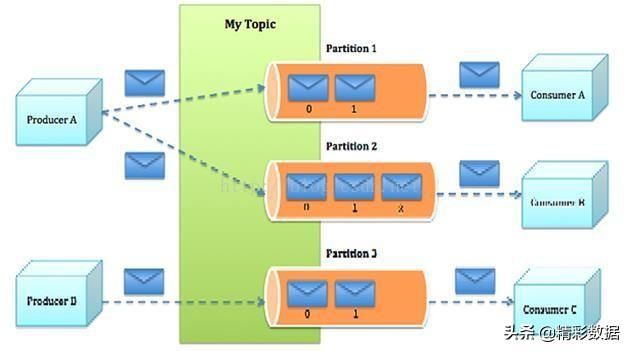
Kafka消息系统架构图2
Producer即生产者,向Kafka集群发送消息,在发送消息之前,会对消息进行分类,即Topic。上图1展示了两个生产者向3个broker的kafka集群产生两个topic数据,两个消费者消费数据的示意图。
图2是两个生产者向一个topic的三个不同分区写数据,三个消费者读取数据的示意图。
Topic即主题,通过对消息指定主题可以将消息分类,消费者可以只关注自己需要的Topic中的消息。
消费者通过与kafka集群建立长连接的方式,不断地从集群中拉取消息,然后可以对这些消息进行处理。
同一个Topic下的消费者和生产者的数量并不是对应的。
2、 kafka服务器消息存储策略
谈到kafka的存储,就不得不提到分区,即partitions,创建一个topic时,同时可以指定分区数目,分区数越多,其吞吐量也越大,但是需要的资源也越多,同时也会导致更高的不可用性,kafka在接收到生产者发送的消息之后,会根据均衡策略将消息存储到不同的分区中。
在每个分区中,消息以顺序存储,最晚接收的的消息会最后被消费。
3、 与生产者的交互
生产者在向kafka集群发送消息的时候,可以通过指定分区来发送到指定的分区中
也可以通过指定均衡策略来将消息发送到不同的分区中
如果不指定,就会采用默认的随机均衡策略,将消息随机的存储到不同的分区中
4、 与消费者的交互
在消费者消费消息时,kafka使用offset来记录当前消费的位置
在kafka的设计中,可以有多个不同的group来同时消费同一个topic下的消息,当不同的group同时消费,他们的的消费的记录位置offset各不相同,不互相干扰。
对于一个group而言,消费者的数量不应该多与分区的数量,因为在一个group中,每个分区至多只能绑定到一个消费者上,即一个消费者可以消费多个分区,一个分区只能给一个消费者消费。因此,若一个group中的消费者数量大于分区数量的话,多余的消费者将不会收到任何消息。
六、kafka的Demo
生产者:
import java.util.Properties;
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
/**
* 生产者
*/
public class KafkaProducerDemo {
public static void main(String[] args) {
Properties props = new Properties();
props.put("metadata.broker.list", "slave1:9092,slave2:9092,slave3:9092"); // kafka集群
props.put("serializer.class", "kafka.serializer.StringEncoder");
ProducerConfig config = new ProducerConfig(props);
Producer producer = new Producer(config);
for (int i = 1001; i <= 1100; i++)
// 生产数据
producer.send(new KeyedMessage("test1", "xiaoniu-msg" + i));
producer.close();
}
} 消费者:
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import kafka.consumer.Consumer;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector;
import kafka.message.MessageAndMetadata;
/**
* 消费者
*/
public class KafkaConsumerDemo {
private static final String topic = "test1";
private static final Integer threads = 2;
public static void main(String[] args) {
Properties props = new Properties();
props.put("zookeeper.connect", "slave2:2181,slave3:2181,slave4:2181"); // zookeeper集群
props.put("group.id", "vvvvv");
//smallest重最开始消费,largest代表从消费者启动后产生的数据才消费
//--from-beginning
props.put("auto.offset.reset", "smallest");
ConsumerConfig config = new ConsumerConfig(props);
ConsumerConnector consumer =Consumer.createJavaConsumerConnector(config);
Map topicCountMap = new HashMap();
topicCountMap.put(topic, threads);
Map>> consumerMap = consumer.createMessageStreams(topicCountMap);
// 读取数据
List> streams = consumerMap.get(topic);
for(final KafkaStream kafkaStream : streams){
new Thread(new Runnable() {
public void run() {
for(MessageAndMetadata mm : kafkaStream){
String msg = new String(mm.message());
System.out.println(msg);
}
}
}).start();
}
}
}