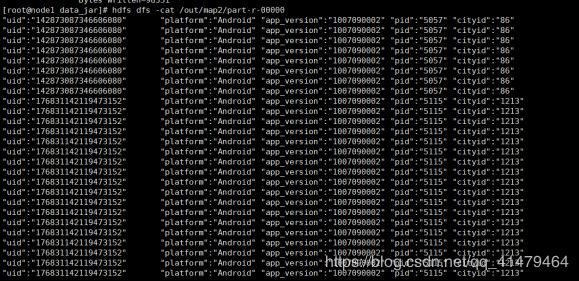
安徽省大数据网络赛大数据分析第二小题
具体数据和字段介绍在此篇博客中:
安徽省大数据分析第一小题
请你将原始数据中用户的"uid","platform","app_version","pid","cityid" 五个字段和期对应的值提取出来。(编写相关代码及部分结果截图7分)
解题思路:
首先我们观察数据的格式,按照什么切分,最终确定按照逗号切分效果最好。
第一步:map阶段进行过滤,只要包含这五个字段就进行写进reduce
核心算法我提取出来:来了一个value我们需要进行字符串转换,并且切割,然后对应的字段的位置是否包含我们想要的数据。
String line = value.toString();
//{"common":{"locationcity":0,"uid":"188495963831271424","uaid":"0","platform":"Android","app_version":"1007090002","net":"WIFI","pid":"5057","identifier":"869121033612809","cityid":"2503","iccid":"89860077221897301901","snsid":"","ts":"1557276436920","versionType":"1","pkg":"com.moji.mjweather"}
//,"event":{"key":"NEWLIVEVIEW_QUIT_TAB","value":"0","du":""}}
//原始数据中用户的"uid","platform","app_version","pid","cityid" 五个字段和期对应的值提取出来。
String split[] = line.split(",");
if(split[1].contains("uid")&&split[3].contains("platform")&&split[4].contains("app_version")&&split[6].contains("pid")&&split[8].contains("cityid")){
String val = " "+split[3]+" "+split[4]+" "+split[6]+" "+split[8];
String keys = split[1];
context.write(new Text(keys),new Text(val));
}
package jinsai2;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MapRe {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf,MapRe.class.getSimpleName());
job.setJarByClass(MapRe.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
job.setMapperClass(MAp.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setReducerClass(Red.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}
Map函数:
package jinsai2;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class MAp extends Mapper{
@Override
protected void map(LongWritable key, Text value, Mapper.Context context)
throws IOException, InterruptedException {
//对进来的数据进行切分 hello sxt you very good 2
String line = value.toString();
//{"common":{"locationcity":0,"uid":"188495963831271424","uaid":"0","platform":"Android","app_version":"1007090002","net":"WIFI","pid":"5057","identifier":"869121033612809","cityid":"2503","iccid":"89860077221897301901","snsid":"","ts":"1557276436920","versionType":"1","pkg":"com.moji.mjweather"}
//,"event":{"key":"NEWLIVEVIEW_QUIT_TAB","value":"0","du":""}}
//原始数据中用户的"uid","platform","app_version","pid","cityid" 五个字段和期对应的值提取出来。
String split[] = line.split(",");
if(split[1].contains("uid")&&split[3].contains("platform")&&split[4].contains("app_version")&&split[6].contains("pid")&&split[8].contains("cityid")){
String val = " "+split[3]+" "+split[4]+" "+split[6]+" "+split[8];
String keys = split[1];
context.write(new Text(keys),new Text(val));
}
}
}Reduce函数:
package jinsai2;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class Red extends Reducer{
@Override
protected void reduce(Text key, Iterable values,
Reducer.Context context) throws IOException, InterruptedException {
for (Text text : values) {
context.write(new Text(key),new Text(text));
}
}
} 结果截图: