刚发布的 Alink 1.1.0 版本,支持发布到 Maven Central,Java 开发者通过 Maven 可以快速搭建 Alink 机器学习项目。本文将演示一个简单的构建方案,便于爱好者快速入门。
先说一下相关的环境,Windows 系统,使用的 Jave 编辑器是 InterlliJ IDEA(Version 2019.3.2),Java SDK 的版本为 1.8。
第一步,创建项目
在 InterlliJ IDEA 中选择创建新项目,并选择 Maven,如下图所示:
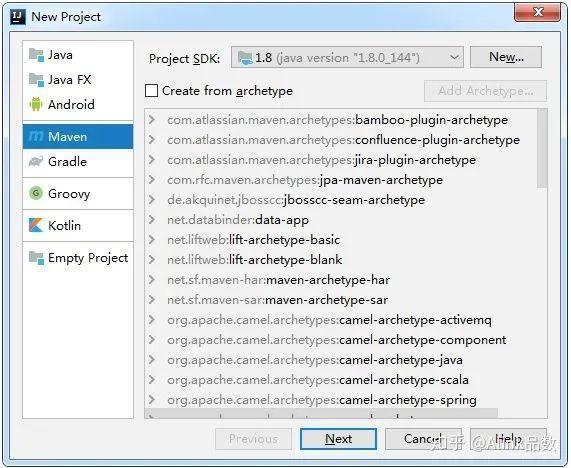
使用默认选项,不用勾选"Create from archetype",点击"Next"按钮,进入下图所示页面,这里只需填写 Name 项,其它内容会自动关联生成。

最后,点击"Finish"按钮,就完成了 Maven 工程的创建。
我们在 InterlliJ IDEA 编辑器中可以看到整个项目的结构如下:
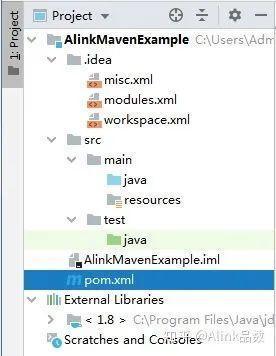
我们查看 pom.xml,内容如下:
4.0.0
org.example
AlinkMavenExample
1.0-SNAPSHOT
第二步,HelloAlink
在开始引入 Alink 相关 jar 包前,我们先进行一个小实验,运行简单的打印输出。在 src -> main -> java 下新建一个 package: "org.example",再新建一个 Java Class:
"HelloAlink.java"
package org.example;
public class HelloAlink {
public static void main(String[] args) {
System.out.println("Hello Alink!");
}
}运行该代码,结果正常打印。
然后,我们在看一下 maven 打包的情况,进入 IDEA 的 Maven 窗口,如下图所示:
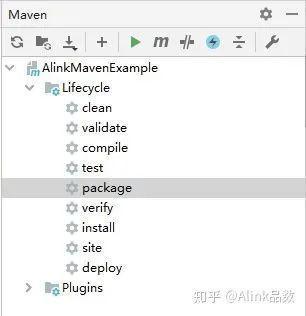
在 Maven 窗口中点击执行"package"操作,操作正常执行完成。在该项目文件夹的 target 子文件夹下可以看到打包出来的 AlinkMavenExample-1.0-SNAPSHOT.jar。
第三步,修改 POM 文件,导入 Alink 相关 jar 包
这是本文中最重要的环节,在 POM 文件中设置 Alink 相关的 dependency,从而在项目中可以使用 Alink 库函数。
可以从如下两个地址中找到 Alink1.1.0 的 dependency 设置:
[1]https://github.com/alibaba/Al...
[2]https://zhuanlan.zhihu.com/p/...
其实,Alink 提供了两个设置方案,分别针对 Flink 1.10 和 Flink 1.9 版本,这里我们选择针对 Flink 最新版本的方案。复制 dependency 项,并粘贴到 POM 的
4.0.0
org.example
AlinkMavenExample
1.0-SNAPSHOT
com.alibaba.alink
alink_core_flink-1.10_2.11
1.1.0
org.apache.flink
flink-streaming-scala_2.11
1.10.0
org.apache.flink
flink-table-planner_2.11
1.10.0
这是 IDEA 会弹出小窗如下:

选择"Import Changes",需要等待一段时间,将所需的 jar 包下载到本地 maven 仓库。
第四步,构建运行
参考 Alink 的 Java 例子:
[3]https://github.com/alibaba/Al...
在当前项目中新建 KMeansExample.java,保留当前的 package 路径package org.example;,将 Alink 例子中的其它代码直接复制过来。代码如下:
package org.example;
import com.alibaba.alink.operator.batch.BatchOperator;
import com.alibaba.alink.operator.batch.source.CsvSourceBatchOp;
import com.alibaba.alink.pipeline.Pipeline;
import com.alibaba.alink.pipeline.clustering.KMeans;
import com.alibaba.alink.pipeline.dataproc.vector.VectorAssembler;
/**
* Example for KMeans.
*/
public class KMeansExample {
public static void main(String[] args) throws Exception {
String URL = "https://alink-release.oss-cn-beijing.aliyuncs.com/data-files/iris.csv";
String SCHEMA_STR = "sepal_length double, sepal_width double, petal_length double, petal_width double, category string";
BatchOperator data = new CsvSourceBatchOp().setFilePath(URL).setSchemaStr(SCHEMA_STR);
VectorAssembler va = new VectorAssembler()
.setSelectedCols(new String[]{"sepal_length", "sepal_width", "petal_length", "petal_width"})
.setOutputCol("features");
KMeans kMeans = new KMeans().setVectorCol("features").setK(3)
.setPredictionCol("prediction_result")
.setPredictionDetailCol("prediction_detail")
.setReservedCols("category")
.setMaxIter(100);
Pipeline pipeline = new Pipeline().add(va).add(kMeans);
pipeline.fit(data).transform(data).print();
}
}然后,选择运行 KMeansExample.main(),可看到正常的输出结果如下(显示篇幅关系,只保留了头两条和末尾 2 条数据):
category|prediction_result|prediction_detail
--------|-----------------|-----------------
Iris-setosa|0|0.49148233882941467 0.3017994492572307 0.2067182119133547
Iris-versicolor|1|0.3249474882831926 0.396327539544579 0.2787249721722284
......
Iris-virginica|2|0.13906038938197507 0.38042216584746935 0.4805174447705556
Iris-virginica|1|0.18304443868954268 0.43146730855314785 0.38548825275730947以上,即可完成 Alink 项目的创建。