前面发表了一系列文章介绍如何使用Python进行Alink在线学习(Online Learning),有读者反馈需要Java版本的,虽然这两个版本在算法原理上是一样的,但是在使用的过程中还有很多差异,为了便于读者快速使用Java上手Alink在线学习,本文将以6个示例从Java的角度重写这一文章,希望对大家有所帮助。
大家在使用 Alink 过程中有任何问题可钉钉扫描下方二维码进群交流~

示例一
在线学习(Online Learning)是机器学习的一种模型训练方法,可以根据线上数据的变化,实时调整模型,是模型能够反映线上的变化,从而提高线上预测的准确率。
为了更好的理解在线学习(Online Learning)的概念,我们先介绍与之相对应的概念:批量训练(Batch Learning),先确定一个样本训练集,针对训练集的全体数据进行训练,一般需要使用迭代过程,重复使用数据集,不断调整参数。在线学习不需要要事先确定训练数据集,训练数据在训练过程中逐条到达的,每来一个训练样本,就会根据该样本产生的损失函数值、目标函数值及梯度,对模型进行一次迭代。
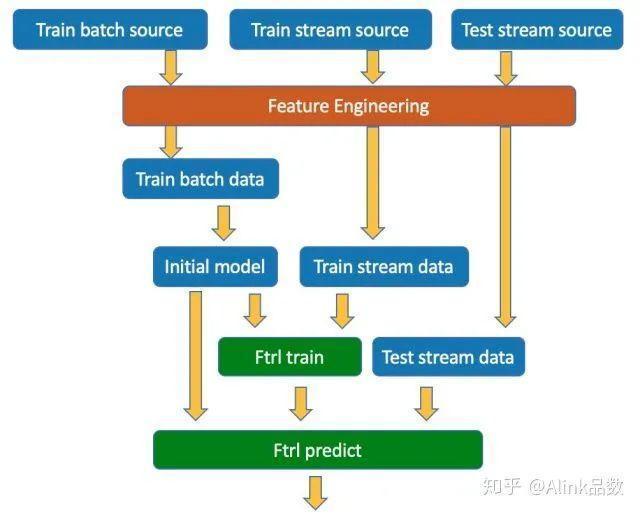
我们先关注FTRL在线预测组件及FTRL流式预测组件,如下图所示,它们之间通过模型数据流链接,即FtrlTrain不断产生新的模型,流式的传给FtrlPredict组件,每次当FtrlPredict组件接收到一个完整的模型,便会替换其旧的模型,切换成新的模型。对于在线学习FtrlTrain,需要两个输入,一个是初始的模型,避免系统冷启动;另一个便是流式的训练数据。FtrlTrain输出就是模型数据流。FtrlPredict组件同样需要初始模型,可以在FtrlTrain输出模型前,对已来到的数据进行预测。

介绍完核心的两个组件,我们再看看所需的初始模型、训练数据流和预测数据流是如何准备的。如下图所示,初始模型,是采用传统的离线训练方式,对批式的训练数据进行训练得到的。

FTRL算法是线性算法,其输入的数据必须都是数值型的,而原始的数据既有数值型的,也有离散型的,我们需要进行相应的特征工程操作,将原始特征数据变换为向量形式。
我们这里需要使用特征工程的组件,将批式原始训练数据转化为批式向量训练数据;将流式原始训练数据转化为流式向量训练数据;将流式原始预测数据转化为流式向量预测数据。
示例二
首先,我们需要一个Java的工程,配置好相关环境。最简单的办法是使用Alink的example工程,下载Alink git的代码,并用Jave IDE打开项目,如下图所示,可以看到三个已经写好的示例:ALSExample, GBDTExample, KMeansExample.

我们在com.alibaba.alink package下新建一个Java文件:
package com.alibaba.alink;
public class FTRLExample {
public static void main(String[] args) throws Exception {
}
}本文的示例参考Alink的Python demo:
https://github.com/alibaba/Al...
在网络广告中,点击率(CTR)是衡量广告效果的一个非常重要的指标。因此,点击预测系统在赞助搜索和实时竞价中具有重要的应用价值。该 Demo 使用 Ftrl 方法实时训练分类模型,并使用模型进行实时预测评估。
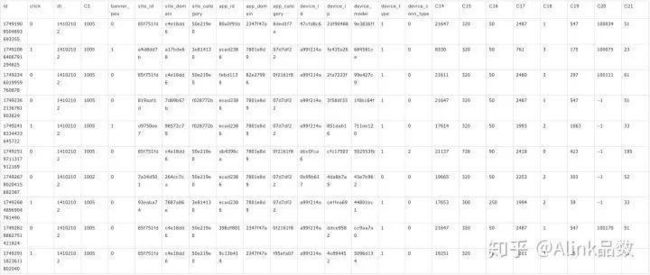
这里使用Kaggle比赛的CTR数据,链接为:https://www.kaggle.com/c/avaz... 。由于是压缩数据,需要下载到本地,为了演示方便,我们直接使用oss上存储的一份采样数据。使用TextSourceBatchOp整行读取打印部分数据,脚本如下:
new TextSourceBatchOp()
.setFilePath("http://alink-release.oss-cn-beijing.aliyuncs.com/data-files/avazu-small.csv")
.firstN(10)
.print();运行结果为:
我们看到每条数据包含多个数据项,是以逗号分隔。下面是各数据列的定义如下:
- id: ad identifier
- click: 0/1 for non-click/click
- hour: format is YYMMDDHH, so 14091123 means 23:00 on Sept. 11, 2014 UTC.
- C1 -- anonymized categorical variable
- banner_pos
- site_id
- site_domain
- site_category
- app_id
- app_domain
- app_category
- device_id
- device_ip
- device_model
- device_type
- device_conn_type
- C14-C21 -- anonymized categorical variables
我们根据各列的定义,组装schemaStr如下:
String schemaStr
= "id string, click string, dt string, C1 string, banner_pos int, site_id string, site_domain string, "
+ "site_category string, app_id string, app_domain string, app_category string, device_id string, "
+ "device_ip string, device_model string, device_type string, device_conn_type string, C14 int, C15 int, "
+ "C16 int, C17 int, C18 int, C19 int, C20 int, C21 int";有了schema的定义,我们可以通过CsvSourceBatchOp读取显示数据,脚本如下:
CsvSourceBatchOp trainBatchData = new CsvSourceBatchOp()
.setFilePath("http://alink-release.oss-cn-beijing.aliyuncs.com/data-files/avazu-small.csv")
.setSchemaStr(schemaStr);
trainBatchData.firstN(10).print();结果显示如下:

由于列数较多,我们不容易将数据与列名对应起来。为了更好的看数据,这里有一个小技巧,打印出来的文本数据及分隔换行符号,正好是MarkDown格式,可以将其复制粘贴到MarkDown编辑器,即可看到整齐的图片显示,如下图所示:
示例三
上一篇展示了数据,这里会继续深入了解数据,由数据列的描述信息,知道里面含有哪些数值型特征,哪些为枚举型特征。具体内容如下面脚本所示:
String labelColName = "click";
String[] selectedColNames = new String[] {
"C1", "banner_pos", "site_category", "app_domain",
"app_category", "device_type", "device_conn_type",
"C14", "C15", "C16", "C17", "C18", "C19", "C20", "C21",
"site_id", "site_domain", "device_id", "device_model"};
String[] categoryColNames = new String[] {
"C1", "banner_pos", "site_category", "app_domain",
"app_category", "device_type", "device_conn_type",
"site_id", "site_domain", "device_id", "device_model"};
String[] numericalColNames = new String[] {
"C14", "C15", "C16", "C17", "C18", "C19", "C20", "C21"};“click“列标明了是否被点击,是分类问题的标签列。对于数值型特征,各特征的取值范围差异很大,一般需要进行标准化、归一化等操作;枚举类型的特征不能直接应用到FTRL模型,需要进行枚举值到向量值的映射,后面还需将各列的变换结果合成到一个向量,即是后面模型训练的特征向量。
我们的示例里,选择对数值类型进行标准化操作,并使用了FeatureHash算法组件,在其参数设置中,需要指定处理的各列名称,并需要标明,哪些是枚举类型,那么没被标明的列就是数值类型。FeatureHash操作会将这些特征通过hasn的方式,映射到一个稀疏向量中,向量的维度可以设置,我们这里设置为30000。每个数值列都会被hash到一个向量项,该列的数值就会付给对应的向量项;而对每个枚举特征的不同枚举值,也会被hash到向量项,并被赋值为1。
其实,FeatureHash同时完成了枚举类型的映射及汇总为特征向量的工作。因为使用了hash的方式,会存在不同内容hash到同一项的风险,但是由于该组件使用起来比较简便 ,在示例中使用,或者作为实验开始时的组件,快速得到baseline指标,FeatureHash还是很适合的。相关脚本如下所示:
// result column name of feature enginerring
String vecColName = "vec";
int numHashFeatures = 30000;
// setup feature enginerring pipeline
Pipeline feature_pipeline = new Pipeline()
.add(
new StandardScaler()
.setSelectedCols(numericalColNames)
)
.add(
new FeatureHasher()
.setSelectedCols(selectedColNames)
.setCategoricalCols(categoryColNames)
.setOutputCol(vecColName)
.setNumFeatures(numHashFeatures)
);我们定义特征工程处理pipeline(管道),其中包括了StandardScaler和FeatureHasher,对批式训练数据trainBatchData执行fit方法,及进行训练,得到PipelineModel(管道模型)。该管道模型可以作用在批式数据,也可以应用在流式数据,生成特征向量。我们先把这个特征工程处理模型保存到本地,设置文件路径为:/Users/yangxu/alink/data/temp/feature_pipe_model.csv。
// fit and save feature pipeline model
String FEATURE_PIPELINE_MODEL_FILE = "/Users/yangxu/alink/data/temp/feature_pipe_model.csv";
feature_pipeline.fit(trainBatchData).save(FEATURE_PIPELINE_MODEL_FILE);
BatchOperator.execute();示例四
上一篇我们训练并保存了特征工程处理模型,我们这里需要使用特征工程处理模型:
- 将批式原始训练数据转化为批式向量训练数据;
- 将流式原始训练数据转化为流式向量训练数据;
- 将流式原始预测数据转化为流式向量预测数据。

批式原始训练数据为:
CsvSourceBatchOp trainBatchData = new CsvSourceBatchOp()
.setFilePath("http://alink-release.oss-cn-beijing.aliyuncs.com/data-files/avazu-small.csv")
.setSchemaStr(schemaStr);我们可以通过定义一个流式数据源,并按1:1的比例实时切分数据,从而得到流式原始训练数据、流式原始预测数据。
// prepare stream train data
CsvSourceStreamOp data = new CsvSourceStreamOp()
.setFilePath("http://alink-release.oss-cn-beijing.aliyuncs.com/data-files/avazu-ctr-train-8M.csv")
.setSchemaStr(schemaStr);
// split stream to train and eval data
SplitStreamOp spliter = new SplitStreamOp().setFraction(0.5).linkFrom(data);
StreamOperator train_stream_data = spliter;
StreamOperator test_stream_data = spliter.getSideOutput(0);通过PipelineModel.load()方法,可以载入前面保存的特征工程处理模型。
// load pipeline model
PipelineModel feature_pipelineModel = PipelineModel.load(FEATURE_PIPELINE_MODEL_FILE);Alink的PipelineModel既能预测批式数据,也可以预测流式数据,而且调用方式系统,使用模型实例的transform方法即可。
批式向量训练数据可以通过如下代码得到:
feature_pipelineModel.transform(trainBatchData)流式向量训练数据可以通过如下代码得到:
feature_pipelineModel.transform(train_stream_data)流式向量预测数据可以通过如下代码得到:
feature_pipelineModel.transform(test_stream_data)进一步,我们通过批式向量训练数据可以训练出一个线性模型作为后面在线学习FTRL算法的初始模型。如下面脚本所示,首先定义逻辑回归分类器lr,然后将批式向量训练数据“连接”到此分类器,输出结果便为逻辑回归模型。
// train initial batch model
LogisticRegressionTrainBatchOp lr = new LogisticRegressionTrainBatchOp()
.setVectorCol(vecColName)
.setLabelCol(labelColName)
.setWithIntercept(true)
.setMaxIter(10);
BatchOperator initModel = feature_pipelineModel.transform(trainBatchData).link(lr);示例五
基于前面几篇的准备工作,我们已经具备了初始模型、流式向量训练数据、流式向量预测数据,如下图蓝色节点所示。接下来,我们会进入该系列文章的关键时刻,演示如何接入FTRL在线训练模块及对应的在线预测模块。
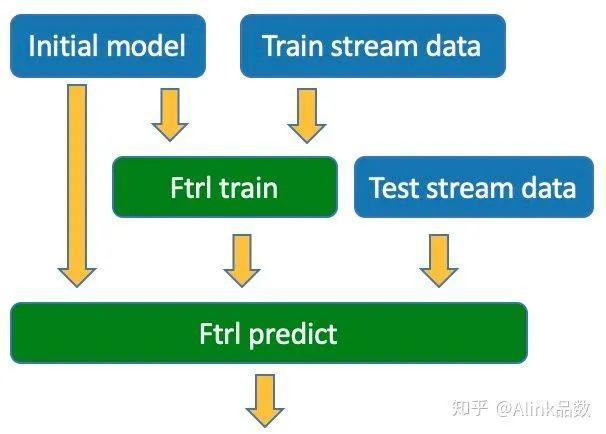
FTRL在线模型训练的代码如下,在FtrlTrainStreamOp的构造函数中输入初始模型initModel,随后是设置各种参数,并“连接“流式向量训练数据。
# ftrl train
model = FtrlTrainStreamOp(initModel) \
.setVectorCol(vecColName) \
.setLabelCol(labelColName) \
.setWithIntercept(True) \
.setAlpha(0.1) \
.setBeta(0.1) \
.setL1(0.01) \
.setL2(0.01) \
.setTimeInterval(10) \
.setVectorSize(numHashFeatures) \
.linkFrom(feature_pipelineModel.transform(train_stream_data))FTRL在线预测的代码如下,需要“连接”FTRL在线模型训练输出的模型流,和流式向量预测数据。
# ftrl predict
predResult = FtrlPredictStreamOp(initModel) \
.setVectorCol(vecColName) \
.setPredictionCol("pred") \
.setReservedCols([labelColName]) \
.setPredictionDetailCol("details") \
.linkFrom(model, feature_pipelineModel.transform(test_stream_data))我们可以如下设置流式结果的打印,由于数据较多,打印前先对流式数据进行采样。注意,对于流式的任务,print()方法不能触发流式任务的执行,必须调用StreamOperator.execute()方法,才能开始执行。
predResult.sample(0.0001).print();
StreamOperator.execute();在执行的过程中,会先运行批式的初始模型训练,待批式任务执行结束,再启动流式任务。得到的结果显示片段如下:
......
click|pred|details
-----|----|-------
......
collect model : 27
collect model : 27
collect model : 27
collect model : 27
collect model : 27
collect model : 27
collect model : 27
collect model : 27
6 load model : 27
0|0|{"0":"0.9955912589178986","1":"0.0044087410821014306"}
3 load model : 27
0 load model : 27
2 load model : 27
5 load model : 27
4 load model : 27
7 load model : 27
1 load model : 27
0|0|{"0":"0.8264317979578765","1":"0.17356820204212353"}
0|0|{"0":"0.9620885206519035","1":"0.037911479348096466"}
0|0|{"0":"0.7733924667279566","1":"0.22660753327204342"}
0|0|{"0":"0.8502672431715895","1":"0.14973275682841047"}
0|0|{"0":"0.9422313239589072","1":"0.057768676041092815"}
0|0|{"0":"0.8540319447494245","1":"0.14596805525057555"}
1|0|{"0":"0.7956910587819983","1":"0.2043089412180017"}
collect model : 28
collect model : 28
collect model : 28
1 load model : 28
collect model : 28
7 load model : 28
collect model : 28
collect model : 28
6 load model : 28
4 load model : 28
collect model : 28
collect model : 28
5 load model : 28
0 load model : 28
3 load model : 28
2 load model : 28
0|0|{"0":"0.794857507111827","1":"0.205142492888173"}
0|0|{"0":"0.7489915122615897","1":"0.25100848773841034"}
0|0|{"0":"0.9145883964932835","1":"0.0854116035067165"}
0|0|{"0":"0.9699130297461115","1":"0.030086970253888512"}
0|0|{"0":"0.8633425927307238","1":"0.13665740726927622"}
1|0|{"0":"0.5067251707884466","1":"0.4932748292115534"}
0|0|{"0":"0.9197477679857682","1":"0.08025223201423182"}
0|0|{"0":"0.8754429175320314","1":"0.1245570824679686"}
0|0|{"0":"0.9027103601565077","1":"0.09728963984349226"}
0|0|{"0":"0.9396522264624441","1":"0.06034777353755594"}
0|0|{"0":"0.7870435722294925","1":"0.2129564277705075"}
......在打印显示的文本中混合了两种信息,一种为各流式预测节点,加载新模型的情况,比如:"5 load model : 27",代表5号节点成功加载模型流中的第27号模型。另一种是预测结果数据,前面打印信息中的。
click|pred|details
-----|----|-------为打印的流式数据的列名信息,第1列是原始的“click”信息,第二列为预测结果列,第三列为预测的详细信息列。对应的预测结果形式为:
0|0|{"0":"0.7870435722294925","1":"0.2129564277705075"}最后,我们再将预测结果流predResult,接入流式二分类评估组件EvalBinaryClassStreamOp,并设置相应的参数,由于每次评估结果给出的是Json格式,为了便于显示,还可以在后面上Json内容提取组件JsonValueStreamOp。代码如下:
// ftrl eval
predResult
.link(
new EvalBinaryClassStreamOp()
.setLabelCol(labelColName)
.setPredictionCol("pred")
.setPredictionDetailCol("details")
.setTimeInterval(10)
)
.link(
new JsonValueStreamOp()
.setSelectedCol("Data")
.setReservedCols(new String[] {"Statistics"})
.setOutputCols(new String[] {"Accuracy", "AUC", "ConfusionMatrix"})
.setJsonPath(new String[] {"$.Accuracy", "$.AUC", "$.ConfusionMatrix"})
)
.print();
StreamOperator.execute();注意:流式的组件“连接”完成后,需要调用流式任务执行命令,即StreamOperator.execute(),开始执行。显示结果如下:
......
Statistics|Accuracy|AUC|ConfusionMatrix
----------|--------|---|---------------
......
window|0.839781746031746|0.6196235914061319|[[140,174],[6609,35413]]
all|0.839781746031746|0.6196235914061319|[[140,174],[6609,35413]]
......
window|0.8396464236640808|0.6729843274019895|[[206,220],[14601,77400]]
all|0.8396889353902778|0.6559248735416315|[[346,394],[21210,112813]]
......
window|0.8389366017867161|0.7125709974947197|[[328,233],[14695,77428]]
all|0.8393823616051211|0.6792648375138227|[[674,627],[35905,190241]]
......上面Statistics列有两个值all和window,all表示从开始运行到现在的所有预测数据的评估结果;wiodow表示时间窗口(当前设置为10秒)的所有预测数据的评估结果。
示例六:完整代码
最后,贴出完整代码,感兴趣的读者可以运行实验。
注意,由于示例中需要演示中间结果,有很多打印或执行的方法,我现将调用这些方法的代码设为了注释,读者可以自己释放某些代码,查看运行效果。
package com.alibaba.alink;
import com.alibaba.alink.operator.batch.BatchOperator;
import com.alibaba.alink.operator.batch.classification.LogisticRegressionTrainBatchOp;
import com.alibaba.alink.operator.batch.source.CsvSourceBatchOp;
import com.alibaba.alink.operator.stream.StreamOperator;
import com.alibaba.alink.operator.stream.dataproc.JsonValueStreamOp;
import com.alibaba.alink.operator.stream.dataproc.SplitStreamOp;
import com.alibaba.alink.operator.stream.evaluation.EvalBinaryClassStreamOp;
import com.alibaba.alink.operator.stream.onlinelearning.FtrlPredictStreamOp;
import com.alibaba.alink.operator.stream.onlinelearning.FtrlTrainStreamOp;
import com.alibaba.alink.operator.stream.source.CsvSourceStreamOp;
import com.alibaba.alink.pipeline.Pipeline;
import com.alibaba.alink.pipeline.PipelineModel;
import com.alibaba.alink.pipeline.dataproc.StandardScaler;
import com.alibaba.alink.pipeline.feature.FeatureHasher;
public class FTRLExample {
public static void main(String[] args) throws Exception {
//new TextSourceBatchOp()
// .setFilePath("http://alink-release.oss-cn-beijing.aliyuncs.com/data-files/avazu-small.csv")
// .firstN(10)
// .print();
String schemaStr
= "id string, click string, dt string, C1 string, banner_pos int, site_id string, site_domain string, "
+ "site_category string, app_id string, app_domain string, app_category string, device_id string, "
+ "device_ip string, device_model string, device_type string, device_conn_type string, C14 int, C15 int, "
+ "C16 int, C17 int, C18 int, C19 int, C20 int, C21 int";
CsvSourceBatchOp trainBatchData = new CsvSourceBatchOp()
.setFilePath("http://alink-release.oss-cn-beijing.aliyuncs.com/data-files/avazu-small.csv")
.setSchemaStr(schemaStr);
//trainBatchData.firstN(10).print();
String labelColName = "click";
String[] selectedColNames = new String[] {
"C1", "banner_pos", "site_category", "app_domain",
"app_category", "device_type", "device_conn_type",
"C14", "C15", "C16", "C17", "C18", "C19", "C20", "C21",
"site_id", "site_domain", "device_id", "device_model"};
String[] categoryColNames = new String[] {
"C1", "banner_pos", "site_category", "app_domain",
"app_category", "device_type", "device_conn_type",
"site_id", "site_domain", "device_id", "device_model"};
String[] numericalColNames = new String[] {
"C14", "C15", "C16", "C17", "C18", "C19", "C20", "C21"};
// result column name of feature enginerring
String vecColName = "vec";
int numHashFeatures = 30000;
// setup feature enginerring pipeline
Pipeline feature_pipeline = new Pipeline()
.add(
new StandardScaler()
.setSelectedCols(numericalColNames)
)
.add(
new FeatureHasher()
.setSelectedCols(selectedColNames)
.setCategoricalCols(categoryColNames)
.setOutputCol(vecColName)
.setNumFeatures(numHashFeatures)
);
// fit and save feature pipeline model
String FEATURE_PIPELINE_MODEL_FILE = "/Users/yangxu/alink/data/temp/feature_pipe_model.csv";
//feature_pipeline.fit(trainBatchData).save(FEATURE_PIPELINE_MODEL_FILE);
//
//BatchOperator.execute();
// prepare stream train data
CsvSourceStreamOp data = new CsvSourceStreamOp()
.setFilePath("http://alink-release.oss-cn-beijing.aliyuncs.com/data-files/avazu-ctr-train-8M.csv")
.setSchemaStr(schemaStr)
.setIgnoreFirstLine(true);
// split stream to train and eval data
SplitStreamOp spliter = new SplitStreamOp().setFraction(0.5).linkFrom(data);
StreamOperator train_stream_data = spliter;
StreamOperator test_stream_data = spliter.getSideOutput(0);
// load pipeline model
PipelineModel feature_pipelineModel = PipelineModel.load(FEATURE_PIPELINE_MODEL_FILE);
// train initial batch model
LogisticRegressionTrainBatchOp lr = new LogisticRegressionTrainBatchOp()
.setVectorCol(vecColName)
.setLabelCol(labelColName)
.setWithIntercept(true)
.setMaxIter(10);
BatchOperator initModel = feature_pipelineModel.transform(trainBatchData).link(lr);
// ftrl train
FtrlTrainStreamOp model = new FtrlTrainStreamOp(initModel)
.setVectorCol(vecColName)
.setLabelCol(labelColName)
.setWithIntercept(true)
.setAlpha(0.1)
.setBeta(0.1)
.setL1(0.01)
.setL2(0.01)
.setTimeInterval(10)
.setVectorSize(numHashFeatures)
.linkFrom(feature_pipelineModel.transform(train_stream_data));
// ftrl predict
FtrlPredictStreamOp predResult = new FtrlPredictStreamOp(initModel)
.setVectorCol(vecColName)
.setPredictionCol("pred")
.setReservedCols(new String[] {labelColName})
.setPredictionDetailCol("details")
.linkFrom(model, feature_pipelineModel.transform(test_stream_data));
//predResult.sample(0.0001).print();
//
//StreamOperator.execute();
// ftrl eval
predResult
.link(
new EvalBinaryClassStreamOp()
.setLabelCol(labelColName)
.setPredictionCol("pred")
.setPredictionDetailCol("details")
.setTimeInterval(10)
)
.link(
new JsonValueStreamOp()
.setSelectedCol("Data")
.setReservedCols(new String[] {"Statistics"})
.setOutputCols(new String[] {"Accuracy", "AUC", "ConfusionMatrix"})
.setJsonPath(new String[] {"$.Accuracy", "$.AUC", "$.ConfusionMatrix"})
)
.print();
//StreamOperator.execute();
}
}