爬虫(二):requests模块(get+post请求)+爬取百度贴吧+百度翻译+有道词典的案例
文章目录
- 一、requests模块基础知识
- 1.要切记python模块的包名requests
- 2.使用步骤
- 3.response对象
- ①参数
- ②响应内容的乱码问题
- 4.查看网页使用的是get请求还是post请求的方法
- 二、requests模块的get请求的三种情况
- 1.没有请求参数的,比如百度的项目,只需要**填写请求头,封装user-agent**
- 案例1-----------百度产品
- 2.带请求参数的,**基础url就是问号和问号前的内容,并且需要设置请求字典**
- 案例2-------------新浪新闻
- 案例3-----------百度贴吧
- 三、requests模块的post请求
- 1.格式
- 2.JSON常用的两种方法
- 案例4--------百度翻译
- 案例5-------有道翻译
一、requests模块基础知识
1.要切记python模块的包名requests
2.使用步骤
-
1.导包
import requests -
2.确定请求的url
base_url='' -
3.发送请求,获取响应
response=requests.get( url=base_url, #请求的url headers={}, #请求头 params={}, #请求参数字典 )
3.response对象
①参数
-
状态码:response.status_code
-
响应头:response.headers[‘Cookie’]
-
响应正文:
1.获取字符串类型的响应正文: response.text 2.获取bytes类型的响应正文: response.content 3.响应正文字符串编码:response.encoding
②响应内容的乱码问题
问题:当我们用response.text获取字符串的响应正文的时候,有时候会出现乱码:原因是response.encoding这个字符安默认指定编码有误。
解决:
#---------------------------方法一:转换成utf-8格式
response.encoding='utf-8'
print(response.text)
#-------------------------------方法:二:解码为utf-8
with open('index.html','w',encoding='utf-8') as fp:
fp.write(response.content.decode('utf-8'))
4.查看网页使用的是get请求还是post请求的方法
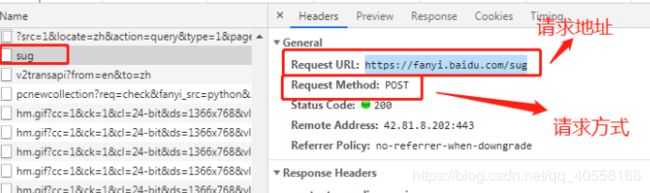
二、requests模块的get请求的三种情况
1.没有请求参数的,比如百度的项目,只需要填写请求头,封装user-agent
案例1-----------百度产品
# ------------------------------------------------1.导包
import requests
# -------------------------------------------------2.确定url
base_url = 'https://www.baidu.com/more/'
# ----------------------------------------------3.发送请求,获取响应
response = requests.get(base_url)
# -----------------------------------------------4.查看页面内容,可能出现 乱码
# print(response.text)
# print(response.encoding)
# ---------------------------------------------------5.解决乱码
# ---------------------------方法一:转换成utf-8格式
# response.encoding='utf-8'
# print(response.text)
# -------------------------------方法二:解码为utf-8
with open('index.html', 'w', encoding='utf-8') as fp:
fp.write(response.content.decode('utf-8'))
print(response.status_code)
print(response.headers)
print(type(response.text))
print(type(response.content))
2.带请求参数的,基础url就是问号和问号前的内容,并且需要设置请求字典
案例2-------------新浪新闻
import requests
# ------------------爬取带参数的get请求-------------------爬取新浪新闻,指定的内容
# 1.寻找基础url
base_url = 'https://search.sina.com.cn/?'
# 2.设置headers字典和params字典,再发请求
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36',
}
key = '孙悟空' # 搜索内容
params = {
'q': key,
'c': 'news',
'from': 'channel',
'ie': 'utf-8',
}
response = requests.get(base_url, headers=headers, params=params)
with open('sina_news.html', 'w', encoding='gbk') as fp:
fp.write(response.content.decode('gbk'))
-
分页类型
- 第一步:找出分页参数的规律
- 第二步:headers和params字典
- 第三步:用for循环
案例3-----------百度贴吧
# _--------------------爬取百度贴吧搜索某个贴吧的前十页
import requests, os
base_url = 'https://tieba.baidu.com/f?'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36',
}
dirname = './tieba/woman/'
if not os.path.exists(dirname):
os.makedirs(dirname)
for i in range(0, 10):
params = {
'ie': 'utf-8',
'kw': '美女',
'pn': str(i * 50)
}
response = requests.get(base_url, headers=headers, params=params)
with open(dirname + '美女第%s页.html' % (i+1), 'w', encoding='utf-8') as file:
file.write(response.content.decode('utf-8'))
三、requests模块的post请求
1.格式
response=requests.post(
url,
headers={},
data={},#请求数据字典
)
2.JSON常用的两种方法
json.dumps(python的list或者dict)---->(返回值)---->json字符串
json.loads(json字符串)---->(返回值)----->python的list或者dict
- post请求一般得到的响应内容是json数据。
- 处理json数据用到的模块是json模块。
- json数据本质就是一个字符串。
response.json()#可以直接将获取到的json字符串转换为json.dumps(python的list或者dict)---->(返回值)---->json字符串
案例4--------百度翻译
import requests
base_url = 'https://fanyi.baidu.com/sug'
kw = input('请输入要翻译的英文单词:')
data = {
'kw': kw
}
headers = {
# 由于百度翻译没有反扒措施,因此可以不写请求头
'content-length': str(len(data)),
'content-type': 'application/x-www-form-urlencoded; charset=UTF-8',
'referer': 'https://fanyi.baidu.com/',
'x-requested-with': 'XMLHttpRequest'
}
response = requests.post(base_url, headers=headers, data=data)
# print(response.json())
#结果:{'errno': 0, 'data': [{'k': 'python', 'v': 'n. 蟒; 蚺蛇;'}, {'k': 'pythons', 'v': 'n. 蟒; 蚺蛇; python的复数;'}]}
#-----------------------------把他变成一行一行
result=''
for i in response.json()['data']:
result+=i['v']+'\n'
print(kw+'的翻译结果为:')
print(result)
结果:

案例5-------有道翻译
import requests
base_url = 'http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule'
data = {
'i': 'spider',
'from': 'AUTO',
'to': 'AUTO',
'smartresult': 'dict',
'client': 'fanyideskweb',
'salt': '15722497498890',
'sign': 'a5bfb7f00ee1906773bda3074ff32fec',
'ts': '1572249749889',
'bv': '1b6a302b48b06158238e3c036feb6ba1',
'doctype': 'json',
'version': '2.1',
'keyfrom': 'fanyi.web',
'action': 'FY_BY_REALTlME',
}
headers= {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Length': '239',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Cookie': '_ntes_nnid=106c3a7170510674c7f7d772e62a558b,1565682306312; OUTFOX_SEARCH_USER_ID_NCOO=1135450303.6725993; OUTFOX_SEARCH_USER_ID="[email protected]"; [email protected]|1570794528|0|other|00&99|not_found&1570667109&mail_client#bej&null#10#0#0|152885&0||[email protected]; _ga=GA1.2.1944828316.1572140505; JSESSIONID=aaa-Ya9um-M_N80M5xr4w; ___rl__test__cookies=1572249749875',
'Host': 'fanyi.youdao.com',
'Origin': 'http://fanyi.youdao.com',
'Referer': 'http://fanyi.youdao.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
}
response = requests.post(base_url,headers = headers,data=data)
print(response.text)
爬取完后,我们发现,我们无法修改关键词,只可以查询词汇为spider的词语,因此,我们需要找到办法可以使查出所有词汇。一般这种情况,由于某些参数的随时变化,我们需要在有道上翻译多个词来对比参数有哪些不同
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-unnLgJFY-1572261727454)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\1572253859237.png)]](http://img.e-com-net.com/image/info8/fe1b97a039c5487399775253c6c4b158.jpg)
知道是这三个参数不一样,因此我们需要破解这三个参数,常见的参数位置:
- js代码中
- 前端页面(可能是隐藏的hidden标签)
- ajax处
经过查询此处为某个js代码中的参数
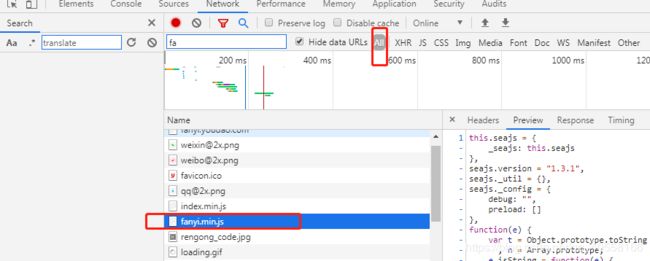
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lq5aYLjA-1572261727454)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\1572260250401.png)]](http://img.e-com-net.com/image/info8/e6ab685afd77435481536f8f53d03f9f.jpg)
所以下一步,我们需要把这几个参数用python求出来
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SWoj03rO-1572261727455)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\1572261045174.png)]](http://img.e-com-net.com/image/info8/a65539ab192d40f39e6d22736c9d1844.jpg)
完整代码:
import requests, time, random, hashlib
base_url = 'http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule'
value='world'#搜索单词
data = {
'i': value,
'from': 'AUTO',
'to': 'AUTO',
'smartresult': 'dict',
'client': 'fanyideskweb',
'salt': '15722497498890',
'sign': 'a5bfb7f00ee1906773bda3074ff32fec',
'ts': '1572249749889',
'bv': '1b6a302b48b06158238e3c036feb6ba1',
'doctype': 'json',
'version': '2.1',
'keyfrom': 'fanyi.web',
'action': 'FY_BY_REALTlME',
}
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Length': '239',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Cookie': '_ntes_nnid=106c3a7170510674c7f7d772e62a558b,1565682306312; OUTFOX_SEARCH_USER_ID_NCOO=1135450303.6725993; OUTFOX_SEARCH_USER_ID="[email protected]"; [email protected]|1570794528|0|other|00&99|not_found&1570667109&mail_client#bej&null#10#0#0|152885&0||[email protected]; _ga=GA1.2.1944828316.1572140505; JSESSIONID=aaa-Ya9um-M_N80M5xr4w; ___rl__test__cookies=1572249749875',
'Host': 'fanyi.youdao.com',
'Origin': 'http://fanyi.youdao.com',
'Referer': 'http://fanyi.youdao.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
}
# ---------------------------------------js代码中
# ts="" + (new Date).getTime()
# salt=r + parseInt(10 * Math.random(), 10)
# sign=n.md5("fanyideskweb" + e + i + "n%A-rKaT5fb[Gy?;N5@Tj")
# ------------------------------转化为python代码
def get_md5(value):
md5 = hashlib.md5()
md5.update(bytes(value, encoding='utf-8'))
return md5.hexdigest()
ts = str(int(time.time() * 1000))
salt = ts + str(random.randint(0, 10))
sign = get_md5("fanyideskweb" + value + salt + 'n%A-rKaT5fb[Gy?;N5@Tj')
response = requests.post(base_url, headers=headers, data=data)
print(response.text)