Python数据挖掘基础(四):Pandas高级处理
目录
- 1. 缺失值处理
- 2. 数据离散化
- 2.1 为什么要离散化?
- 2.2 什么是数据的离散化?
- 2.3 股票涨跌幅分组数据变成one-hot编码
- 3. 合并
- 4. 交叉表与透视表
- 5. 分组与聚合
1. 缺失值处理
本文所使用到的所有数据在此处下载:
链接:https://pan.baidu.com/s/16ayvfRw95K0xma9o3YPN3Q 密码:qgt3
判断缺失值是否存在,示例代码如下:
import numpy as np
import pandas as pd
type(np.NAN) # float
# 读取电影数据
movie_data = pd.read_csv("./data/IMDB-Movie-Data.csv")
# 1.判断是否存在缺失值
np.any(pd.isnull(movie_data)) # 里面如果有一个缺失值,就返回True
# 2.判断缺失值是否存在
np.all(pd.notnull(movie_data)) # 里面如果有一个缺失值,就返回False
处理缺失值,示例代码如下:
# 处理缺失值
# 1.删除缺失值 pandas删除缺失值,使用dropna的前提是,缺失值的类型必须是np.nan
movie_data.dropna() # 不修改原数据
np.any(pd.isnull(movie_data)) # True
data = movie_data.dropna() # 可以使用一个新的变量接收它
np.any(pd.isnull(data)) # False
# 2.替换缺失值
# 不修改原有的数据 用平均值来进行代替
data2 = movie_data["Revenue (Millions)"].fillna(value=movie_data["Revenue (Millions)"].mean())
# 直接将原有的数据进行修改
# movie_data["Revenue (Millions)"].fillna(value=movie_data["Revenue (Millions)"].mean(), inplace=True)
data2
# 3.替换所有缺失值
for i in movie_data.columns:
# print(i)
if np.all(pd.notnull(movie_data[i])) == False:
# print(i)
# 替换
movie_data[i].fillna(value=movie_data[i].mean(), inplace=True)
np.any(pd.isnull(data))
不是缺失值 nan 的,而是有 ? 等默认标记的处理,示例代码如下:
# 有默认标记的处理
# 数据准备
wis = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data")
# 1.先替换"?"为np.nan to_replace: 替换前的值 value: 替换后的值
wis = wis.replace(to_replace="?", value=np.nan)
# 2.在进行缺失值的处理
wis.dropna()
2. 数据离散化
2.1 为什么要离散化?
连续属性离散化的目的是为了简化数据结构,数据离散化技术可以用来减少给定连续属性值的个数。离散化方法经常作为数据挖掘的工具。
2.2 什么是数据的离散化?
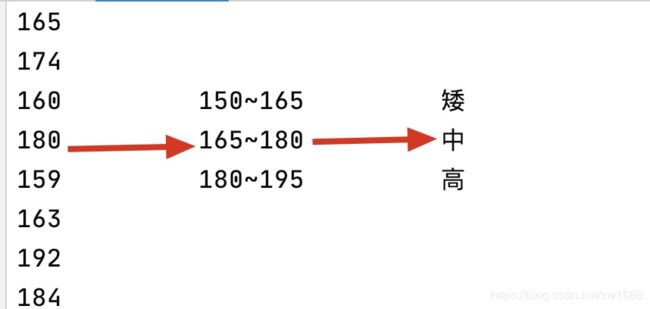
连续属性的离散化就是在连续属性的值域上,将值域划分为若干个离散的区间,最后用不同的符号或整数 值代表落在每个子区间中的属性值。离散化有很多种方法,这里使用一种最简单的方式去操作,如下:
- 原始人的身高数据:165,174,160,180,159,163,192,184
- 假设按照身高分几个区间段:150~165, 165~180,180~195
接下来对股票每日的 p_change 进行离散化,示例代码如下:
# 1.读取文件
data = pd.read_csv("./data/stock_day.csv")
# 2.删除一些列,让数据更简单些,再去做后面的操作
data = data.drop(["ma5","ma10","ma20","v_ma5","v_ma10","v_ma20"], axis=1)
p_change = data["p_change"]
# p_change
# 3. 对数据进行分组将数据分组 一般会与value_counts搭配使用,统计每组的个数
qcut = pd.qcut(p_change, 10) # 自由分组 组数为10
qcut.value_counts() # 统计每组的个数
上述代码执行结果如下:

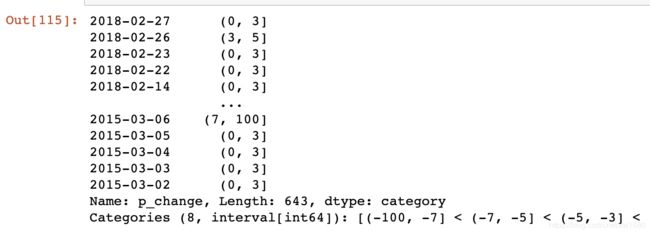
当然,我们也可以自定义区间分组,示例代码如下:
# 自己指定分组区间
bins = [-100, -7, -5, -3, 0, 3, 5, 7, 100]
p_counts = pd.cut(p_change, bins)
p_counts
结果如下:
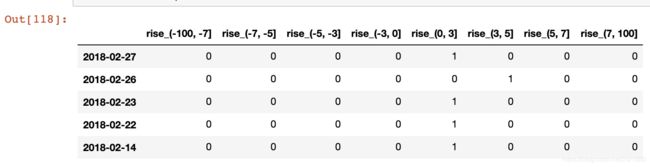
2.3 股票涨跌幅分组数据变成one-hot编码
把每个类别生成一个布尔列,这些列中只有一列可以为这个样本取值为1。其又被称为热编码。把下图中左边的表格转化为使用右边形式进行表示:
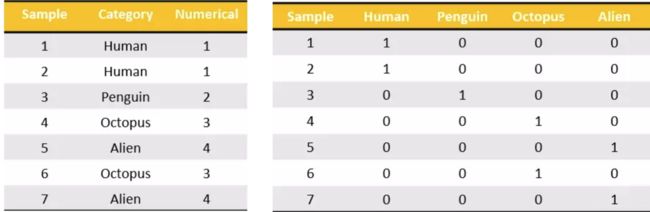
示例代码如下:
# 得出one-hot编码矩阵
dummies = pd.get_dummies(p_counts, prefix="rise")
dummies.head() # 只取了前5行演示结果
结果如下:
3. 合并
如果你的数据由多张表组成,那么有时候需要将不同的内容合并在一起分析。
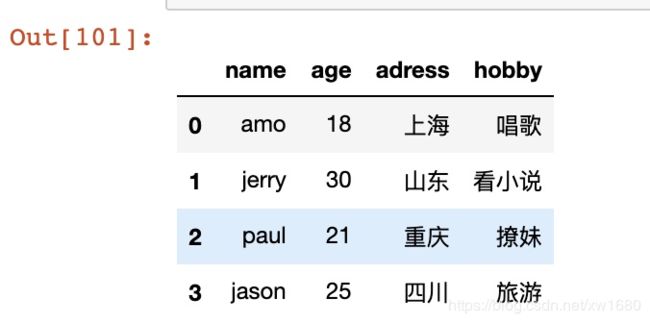
pd.concat([data1, data2], axis=1) 按照行或列进行合并,axis=0为列索引,axis=1为行索引,示例代码如下:
dict1 = {"name": ["amo","jerry","paul","jason"], "age": [18,30,21,25]}
data1 = pd.DataFrame(dict1)
data2 = pd.DataFrame({"adress":["上海","山东","重庆","四川"], "hobby": ["唱歌","看小说","撩妹","旅游"]})
# 将data1表和data2表合并
pd.concat([data1, data2], axis=1) # 指定轴
结果如下所示:
指定按照两组数据的共同键值对合并或者左右各自,语法格式如下:
pd.merge(left, right, how='inner', on=None,
left_on=None, right_on=None)
参数说明如下:
- left:A DataFrame object
- right:Another DataFrame object
- on:Columns (names) to join on. Must be found in both the left and right DataFrame objects.
- left_on=None, right_on=None:指定左右键
| Merge method | SQL Join Name | Description |
|---|---|---|
| left | LEFT OUTER JOIN | Use keys from left frame only |
| right | RIGHT OUTER JOIN | Use keys from right frame only |
| outer | FULL OUTER JOIN | Use union of keys from both frames |
| inner | INNER JOIN | Use intersection of keys from both frames |
示例代码如下:
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
# 默认内连接
result = pd.merge(left, right, on=['key1', 'key2'])
result # 有点类似于数据库
结果如下所示:

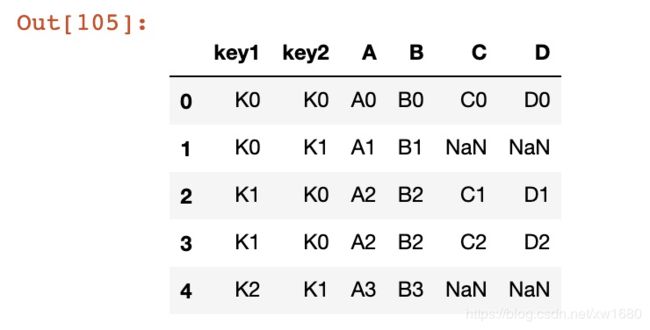
左连接,示例代码如下:
# 左连接
result = pd.merge(left, right, how='left', on=['key1', 'key2'])
result
结果如下所示:
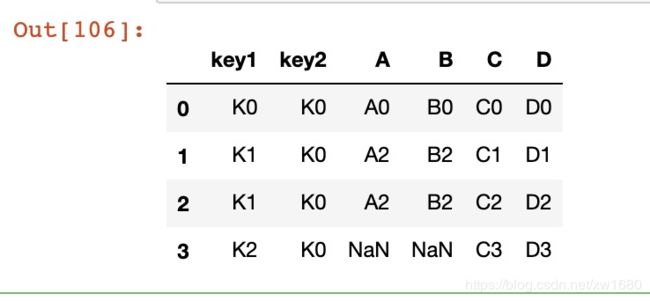
右连接,示例代码如下:
result = pd.merge(left, right, how='right', on=['key1', 'key2'])
result
结果如下所示:
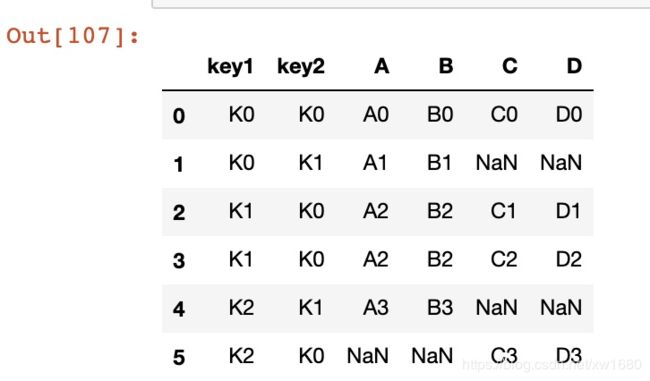
外连接,示例代码如下:
result = pd.merge(left, right, how='outer', on=['key1', 'key2'])
result
结果如下所示:
4. 交叉表与透视表
交叉表用于计算一列数据对于另外一列数据的分组个数(寻找两个列之间的关系)。用以下案例进行具体说明,示例代码如下:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 准备两列数据,星期数据以及涨跌幅是好是坏数据
stock_data = pd.read_csv("./data/stock_day.csv")
stock_data
# 寻找星期几跟股票张得的关系
# 1.先把对应的日期找到星期几
date = pd.to_datetime(stock_data.index).weekday
stock_data["week"] = date
# stock_data
# 2.假如把p_change按照大小去分个类0为界限
stock_data['posi_neg'] = np.where(stock_data["p_change"]>0, 1, 0)
# stock_data.head(20)
# 3.查找两列的关系
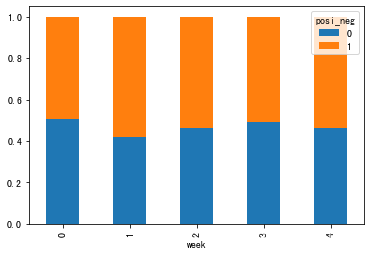
count = pd.crosstab(stock_data["week"], stock_data["posi_neg"])
# count
# 4.计算百分比
sum1 = count.sum(axis=1) # 默认按列进行求和 需要指定轴
pro = count.div(sum1, axis=0) # 需要指定轴 注意轴不用死记 用的时候试试就好了
# 5.展示数据
pro.plot(kind="bar", stacked=True) # 可以发现比matplotlib画图更简单
plt.show()
# 通过透视表,将整个过程变成更简单一些
stock_data.pivot_table(['posi_neg'], index='week')
结果如下所示:
5. 分组与聚合
分组与聚合通常是分析数据的一种方式,通常与一些统计函数一起使用,查看数据的分组情况。想一想上面的交叉表与透视表也有分组的功能,所以算是分组的一种形式,只不过他们主要是计算次数或者计算比例。效果:
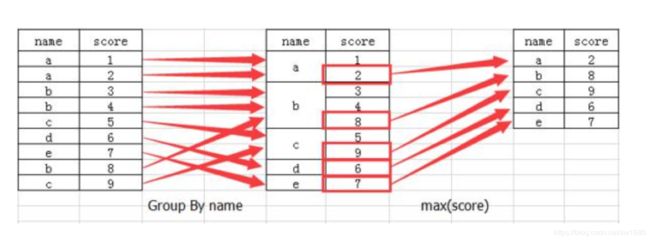
API:DataFrame.groupby(key, as_index=False),用一个案例来进行说明,不同颜色的不同笔的价格数据,示例代码如下:
col = pd.DataFrame({'color': ['white','red','green','red','green'],
'object': ['pen','pencil','pencil','ashtray','pen'],
'price1':[5.56,4.20,1.30,0.56,2.75],
'price2':[4.75,4.12,1.60,0.75,3.15]})
# 1.进行分组,对颜色分组,price进行聚合求平均值
col.groupby(by="color")["price1"].mean()
# 这样写也是可以的 我习惯上面一种
col["price1"].groupby(by=col["color"]).mean() # 这种方式不能使用as_index:设置索引
col.groupby(by="color", as_index=False)["price1"].mean()
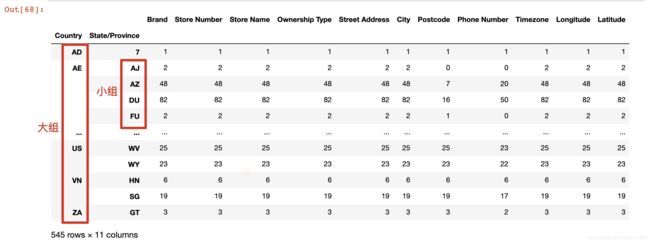
现在我们有一组关于全球星巴克店铺的统计数据,如果我想知道美国的星巴克数量和中国的哪个多,或者我想知道中国每个省份星巴克的数量的情况,那么应该怎么办?示例代码如下:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 1.从文件中读取辛巴克数据
starbucks = pd.read_csv("./data/starbucks/directory.csv")
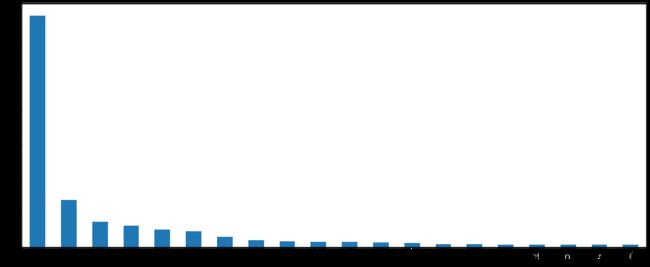
# 2.按照国家分组,求出每个国家的星巴克零售店数量
count = starbucks.groupby(["Country"]).count()
# 3.全部展示出来太乱 先排序 然后取前20的数据展示即可
# ascending=False 降序排列
count["Brand"].sort_values(ascending=False)[:20].plot(kind="bar", figsize=(20, 8))
plt.show()
上述代码执行结果如下:
假设我们加入省市一起进行分组,示例代码如下:
starbucks.groupby(["Country","State/Province"]).count()
结果如下图所示: