keras模型——VGG16模型解析
运行代码
VGG16_model = VGG16(weights='imagenet')
VGG16_model.summary()
层情况
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 224, 224, 3) 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 224, 224, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 112, 112, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 112, 112, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 112, 112, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 56, 56, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 56, 56, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 28, 28, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 14, 14, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
_________________________________________________________________
flatten (Flatten) (None, 25088) 0
_________________________________________________________________
fc1 (Dense) (None, 4096) 102764544
_________________________________________________________________
fc2 (Dense) (None, 4096) 16781312
_________________________________________________________________
predictions (Dense) (None, 1000) 4097000
=================================================================
Total params: 138,357,544
Trainable params: 138,357,544
Non-trainable params: 0
_________________________________________________________________
上个结构图

代码
从vgg16.py获得层代码如下:
if input_tensor is None:
img_input = layers.Input(shape=input_shape)
else:
if not backend.is_keras_tensor(input_tensor):
img_input = layers.Input(tensor=input_tensor, shape=input_shape)
else:
img_input = input_tensor
# Block 1
x = layers.Conv2D(64, (3, 3),
activation='relu',
padding='same',
name='block1_conv1')(img_input)
x = layers.Conv2D(64, (3, 3),
activation='relu',
padding='same',
name='block1_conv2')(x)
x = layers.MaxPooling2D((2, 2), strides=(2, 2), name='block1_pool')(x)
# Block 2
x = layers.Conv2D(128, (3, 3),
activation='relu',
padding='same',
name='block2_conv1')(x)
x = layers.Conv2D(128, (3, 3),
activation='relu',
padding='same',
name='block2_conv2')(x)
x = layers.MaxPooling2D((2, 2), strides=(2, 2), name='block2_pool')(x)
# Block 3
x = layers.Conv2D(256, (3, 3),
activation='relu',
padding='same',
name='block3_conv1')(x)
x = layers.Conv2D(256, (3, 3),
activation='relu',
padding='same',
name='block3_conv2')(x)
x = layers.Conv2D(256, (3, 3),
activation='relu',
padding='same',
name='block3_conv3')(x)
x = layers.MaxPooling2D((2, 2), strides=(2, 2), name='block3_pool')(x)
# Block 4
x = layers.Conv2D(512, (3, 3),
activation='relu',
padding='same',
name='block4_conv1')(x)
x = layers.Conv2D(512, (3, 3),
activation='relu',
padding='same',
name='block4_conv2')(x)
x = layers.Conv2D(512, (3, 3),
activation='relu',
padding='same',
name='block4_conv3')(x)
x = layers.MaxPooling2D((2, 2), strides=(2, 2), name='block4_pool')(x)
# Block 5
x = layers.Conv2D(512, (3, 3),
activation='relu',
padding='same',
name='block5_conv1')(x)
x = layers.Conv2D(512, (3, 3),
activation='relu',
padding='same',
name='block5_conv2')(x)
x = layers.Conv2D(512, (3, 3),
activation='relu',
padding='same',
name='block5_conv3')(x)
x = layers.MaxPooling2D((2, 2), strides=(2, 2), name='block5_pool')(x)
if include_top:
# Classification block
x = layers.Flatten(name='flatten')(x)
x = layers.Dense(4096, activation='relu', name='fc1')(x)
x = layers.Dense(4096, activation='relu', name='fc2')(x)
x = layers.Dense(classes, activation='softmax', name='predictions')(x)
else:
详解
1、input层
通过img_input = layers.Input建立输入层,定义输出数据尺寸shape size。通过第二层input_tensor建立连接,也可以去掉input层直接在第二层通过定义input_shape实现。不过在进行模型并联时还是用input_tensor建立一个统一的输入比较好。
2、block1层
两个卷积层一个最大池化层
卷积层定义:
Conv2D(filters, kernel_size, strides=(1, 1), padding=‘valid’, data_format=None, dilation_rate=(1, 1), activation=None, use_bias=True, kernel_initializer=‘glorot_uniform’, bias_initializer=‘zeros’, kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None)
filters:定义使用多少滤波器进行特征提取,而滤波器权重就是cnn训练目标。
kernel_size:卷积核大小,从1~11都有,也可以设成可变形卷积核,核越大感受野越大,越小越精细。如果当前层和下一层都只有一个通道那么1×1卷积核相当于做了一个比例缩放。但若当前层为m通道,则1×1核只要n
同时小卷积核将具有:
- 网络更深,更多的激活函数、更丰富的特征,更强的辨别能力;
- 卷积层的参数减少。相比5x5、7x7和11x11的大卷积核,3x3明显地减少了参数量,即使通过叠加增加了网络深度,参数量也比大卷积核少;
- 多个小卷积堆叠在分类精度上比单个大卷积要好。
strides:滤波器移动步长,影响获得feature map的分辨率
padding:边缘处理,valid放弃边缘,same补充边缘
dilation_rate:扩张,相当于扩张filter处理范围,空洞卷积提供了更大的感受野。空洞卷积经常用在实时图像分割中。当网络层需要较大的感受野,但计算资源有限而无法提高卷积核数量或大小时,可以考虑空洞卷积。

activation:相当于对当前feature map卷积和的激活函数输出
use_bias:感知器的偏置值
kernel_initializer、bias_initializer:初始化值比较多,用的不多查文档吧
kernel_regularizer、bias_regularizer、activity_regularizer:正则化器允许在优化过程中对层的参数或层的激活情况进行惩罚,在过拟合情况下需要考虑调整
kernel_constraint、bias_constraint:最优化时限制参数的取值范围
卷积层参数量:kernel_size×filters×feature map+filters
最大池化层定义:
MaxPooling2D(pool_size=(2, 2), strides=None, padding=‘valid’, data_format=None)
pool_size:池大小。池化主要作用在于减少参数,简化特征,MaxPooling可以保留更多纹理信息,相应的AveragePooling保留更多的图像背景信息
strides、padding、data_format:参看conv层。
3、block2层
与block1层一致。对feature map进行特征提取。获取特征为上一层的一倍,1层相对来说还好理解为图像的轮廓、纵线条、横线条等等的特征。2层得到的特征就比较抽象,为对特征的进一步特征化并拆分为一倍特征进行表达。
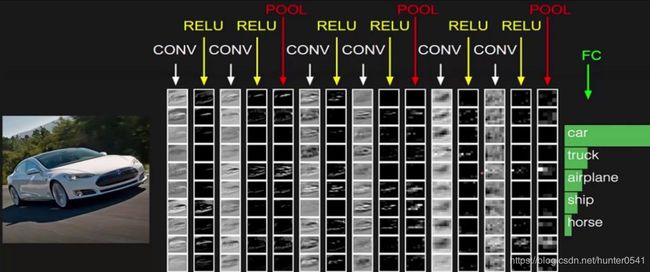
4、block3层、block4层、block5层
开始采用3层卷积层加池化层作为一个模块。如前所述,3层卷积相当于感受野再增大,3x3近似为7x7特征提取窗。推断论文作者认为随着特征尺寸减小维度升高,后续采用更大的感受野对抽象特征归类总结。
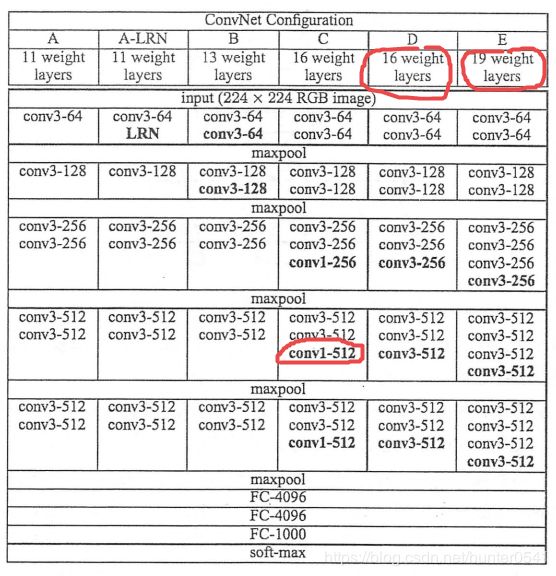
通过下图对VGG的设计可以看出,卷积块经历不断提升的试验。本意是探索卷积网络深度是如何影响大规模图像分类与识别的精度和准确率。通过VGG16、VGG19的试验比较,采用这种深度卷积的方式已经达到了检测精度的上限。
5、分类层
采用一个flatten层三个dense层组成。
Flatten(data_format=None)
将输入展平。多维变为一维,准备进入全连接层。
Dense(units, activation=None, use_bias=True, kernel_initializer=‘glorot_uniform’, bias_initializer=‘zeros’, kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None)
units:输出维度
其他参数参见conv层。
全连接层负责将特征与标签一一对应。