ICCV2019(Segmentation):ShelfNet-论文解读《ShelfNet for Fast Semantic Segmentation》
文章目录
- 原文地址
- 论文阅读方法
- 初识(Abstract & Introduction & Conclusion)
- 相知(Body)
- 2. Related Work
- 2.1 Semantic Segmentation
- 2.2 Real-time Semantic Segmentation
- 3. Methods
- 3.1 Structure of ShelfNet
- 3.2 Channel Reduction for Fast Inference Speed
- 3.3 ShelfNet is an Ensemble of FCNs
- 3.4 Ensemble of Deep and Shallow Paths
- 3.5 Shared-weights Residual Block(S-Block)
- 4. Experiments and Results
- 4.1 Datasets and Implementation Details
- 4.1.4 Implementation Details
- 4.2 Ablation Analysis
- 4.2.1 Ablation Study for Structure
- 4.2.2 Shared-weights Blocks (S-Block)
- 4.2.3 Speed Analysis for Backbone
- 4.3 Results
- 4.3.1 PASCAL VOC 2012
- 4.3.2 PASCAL-Context
- 4.3.3 Cityscapes
- 回顾(Review)
- 代码
原文地址
https://openaccess.thecvf.com/content_ICCVW_2019/papers/CVRSUAD/Zhuang_ShelfNet_for_Fast_Semantic_Segmentation_ICCVW_2019_paper.pdf
论文阅读方法
三遍论文法
初识(Abstract & Introduction & Conclusion)
这篇文章主要针对的情景为实时分割(Fast & Accuracy),目前大部分深度模型会带来计算上的负担,虽然提出了剪枝和蒸馏的策略,但对于Fast Semantic Segmentation任务来说这点提升是不足够的。
目前,绝大多数SOTA的Model都是基于"single encoder-decoder"结构,image经过下采样再上采样。本文提出的ShelfNet,采用了一种特殊的架构(类似于multi-column shelf),如下图的(a)所示(3.1节图例),Backbone不同阶段编码的multi-scale特征被送入"Segmentation Shelf",“Shelf"由多个’‘encoder-decoder’'对组成,在不同的空间分辨率分支上使用了"skip-connection”,这种独特的结构增加了网络内部的路径数量,以此来改善网络中的信息流动,从而提高了分割精度。
本文主要贡献:
- 全新的结构——ShelfNet,多个’encoder-decoder’对改善网络中的信息流动;
- 同一个residual block的两个卷积层贡献权重,在不影响精度的条件下,减少参数量;
- 在多个benchmark上得到验证
相知(Body)
2. Related Work
2.1 Semantic Segmentation
这一段主要回顾了一些经典的分割方法,包括基于HOG和SIFT来进行提取特征的传统方法,还有深度学习的FCN、U-Net、Refine-Net和SegNet等方法。最后特别提到了基于dilated convolution的方法(比如SOTA的DeepLab系列、PSPNet、EncNet等),由于空洞卷积的应用,它们拥有更高的空间分辨率,但同时也带来了更高的计算代价,这不适合对时间效率要求很高的分割任务。
2.2 Real-time Semantic Segmentation
这一段介绍了一些实时的语义分割模型,包括ICNet,Light-Weight RefineNet,GUN、EffConv、ENet和BiSeNet,并说明本文提出的ShelfNet与它们的不同。
3. Methods
3.1 Structure of ShelfNet

如上图所示,ShelfNet依附于Backbone(ResNet/Xception/DenseNet等),行A-D分别表示不同尺度的特征图输出,它们会被送入’Segmentation Shelf’中。Segmentation Shelf是一个Shelf形状的多列(1-4)结构,col.3为encoder(下采样),col2和col4为decoder (下采样),在相邻列(例如3和4)之间,在不同的空间尺度阶段(A-D)使用"skip-connection"。
Stage-wise特征经过col.1的编码后被送入col.2的S-Block模块中,S-Block如上图(b)所示,作为残差模块,两个卷积层共享权重(减少参数量),结合了垂直方向和水平方向的特征(sumed-up),并且S-Block的输入和输出具有相同的shape。
在encoder模块(col.3)中,feature map会经过一个stride=2的卷积,减半spatial size,加倍channel;同样地,在decoder模块(col2 col4)中,feature map经过一个stride=2的转置卷积来加倍spatial size,减半channel。最后,A4的output接一个1x1卷积+softmax操作,生成最后的分割结果。
3.2 Channel Reduction for Fast Inference Speed
从Backbone中直接得到的feature map通常具有比较大的channel数,为了更快速的inference速度,使用1x1卷积(后接batch-norm layer + ReLU)减少通道数。
3.3 ShelfNet is an Ensemble of FCNs
ShelfNet可以视为FCNs的ensemble,Andreas等人证明了ResNet可以看做是一些浅层网络的ensemble,因为残差结构为有效信息的流动提供了多条路径。同样地,ShelfNet也为有效信息流动提供了多条路径。如下图所示,不同颜色代表的信息流动路径,其中每一条路径都可以被看做一个FCN的变种,所以ShelfNet有能力去捕捉更复杂的特征并得到更高的精度。

相比于单个’encoder-decoder’结构(例如SegNet(4条)),ShelfNet(29条)中的FCN有效数量要大得多,FCN路径数量随着encoder-decoder pair的增加呈指数增长。ShelfNet这种独特的结构增加了有效FCN数量,因此能取得更高的准确率。
3.4 Ensemble of Deep and Shallow Paths

GridNet也是一个多列结构,这里主要说明ShelfNet与其的主要区别:当具有同等数量的encoder-decoder模块时,ShelfNet的信息路径将会更深。如上图所示ShelfNet为16层,GridNet为10层,ShelfNet能够更好地整合来自各种浅层、深层路径的信息。
3.5 Shared-weights Residual Block(S-Block)
相比于SegNet,FCN有效路径的增加用了额外的block,为了减小模型的大小,同一个Block中的两个卷积层共享权重(但有两个不同的batch-norm layer),这种重用设计类似于RCNN和RNN;为了防止过拟合,在两个卷积层中间加入了Dropout层。所以,S-Block模块结合了’skip-connection’,'RNN’和’drop-out’正则化,并且相比于residual block参数量更少。
4. Experiments and Results
4.1 Datasets and Implementation Details
前面几小节是数据集介绍,不再赘述
4.1.4 Implementation Details
训练:使用’poly’ schedule,weight-decay=10-4,SGD;
数据增广:flip、scale、rotate
测试:multi-scale input 后 average
4.2 Ablation Analysis
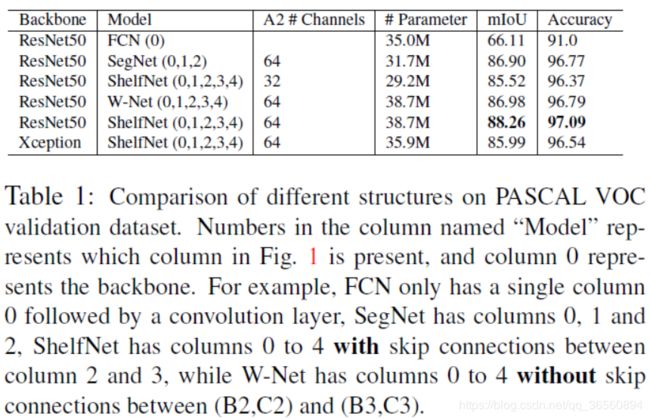
4.2.1 Ablation Study for Structure
作者基于PASCAL VOC的验证集做了消融实验,首先对比shelf-shaped结构(增加信息流动路径数)的影响。为了更好地对比,作者再构建了一个W-Net(删除了(B2,C2)和(B3,C3)之间的skip-connection),类似于SHN。数据流动的路径数量:ShelfNet>W-Net> SegNet>FCN,Table1的实验结果也验证了这个观点。
为了进一步证明准确率的提升是来自于路径数量的增加,而非参数量的增加。设置了设置了一个实验:保持backbone不变,将ShelfNet的通道数减少一半(例如A2:46->32)。这样,参数变为29.2M,相比于35.0M的FCN在性能上还是好了不少。
4.2.2 Shared-weights Blocks (S-Block)
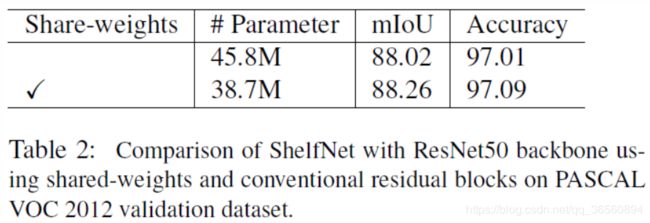
使用共享权重后,参数量减少,准确率和mIoU反而略有提升。
4.2.3 Speed Analysis for Backbone
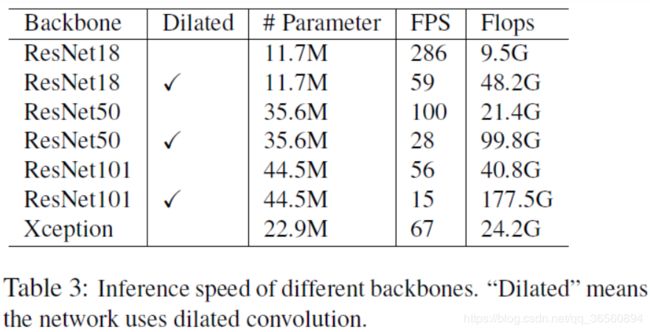
在不同的Backbone上测试ShelfNet的inference速度,从上表可以看到"Dilated"确实会影响速度。在相同的结构下,使用空洞卷积,速度会变慢5倍左右。
4.3 Results
4.3.1 PASCAL VOC 2012

Comparison with non real-time models:与非实时的SOTA的模型进行比较,ShelfNet在保持准确率的情况下,速度提升了很多倍。
4.3.2 PASCAL-Context

4.3.3 Cityscapes
对于非实时的任务(PASCAL数据集),使用的是3.1节所示的架构;对于实时任务,我们将网络修改为轻量级版本,命名为ShelfNet-lw。
Light-weight ShelfNet:在3.1节所示的架构上,ShelfNet-lw只使用BCD三个level的特征送入segmentation shelf(未使用A),对于ShelfNet34-lw,BCD的channel数设置为:128,256,512;对于ShelfNet18-lw,BCD的channel数设置为:64,128,256,进一步减少计算量。其次,将转置卷积转换为直接上采样(双线性插值),并使用conv-bn-relu和channel attention来代替上采样分支中的S-Block。为了训练light-weight ShelfNet,使用了online hard example mining和distributed training(匹配BiSeNet的训练策略)。
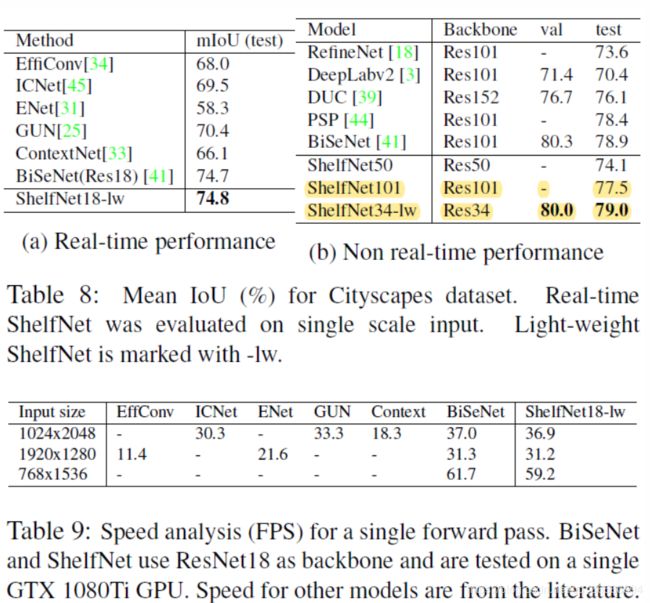
Numerical: 对于非实时任务,使用multi-scale + average,对于实时任务,使用single-scale。ShelfNet-lw在实时任务达到了新的SOTA,在推理速度上,媲美BiSeNet,远超其他model。
回顾(Review)
ShelfNet是发在2019年ICCV的workshop的一篇文章,它的性能都还可以,包括准确率和速度。其实,本文所提方法的创新性不是特别够,相当于多加了一个级联的encoder-decoder模块,不过作者的解释和写作还是没得说的,结构、思路都交代得很清楚,特别在第3节,多个角度解释了本文结构设计的好处。但其在对比准确率时候时,在Pascal和Cityspace数据集上,都没有提及最新的SOTA模型,这里应该也有减分吧。总之,这篇文章结构清晰、实现起来也不算难,论文写作手法也可借鉴。
代码
官方code:https://github.com/juntang-zhuang/ShelfNet-lw-cityscapes
这里放上作者的官方实现代码,等有空我再自己复现一篇将地址贴在这里~
以上为个人的浅见,水平有限,如有不对,望大佬们指点。
未经本人同意,请勿转载,谢谢。