爬虫实践---Selenium-抓取淘宝搜索商品信息
Selenium 是什么?一句话,自动化测试工具。它支持各种浏览器,包括 Chrome,Safari,Firefox 等主流界面式浏览器,如果你在这些浏览器里面安装一个 Selenium 的插件,那么便可以方便地实现Web界面的测试。
主要用法参考:Selenium用法
https://www.taobao.com 淘宝网首页,输入“键盘”,跳转页面,获取页面信息,扣取需要信息进行输出或保存。

显式等待
显式等待 使用ExpectedConditions类中自带方法, 可以进行显试等待的判断。
显式等待可以自定义等待的条件,用于更加复杂的页面等待条件
等待的条件 WebDriver方法
页面元素是否在页面上可用和可被单击 elementToBeClickable(By locator)
页面元素处于被选中状态 elementToBeSelected(WebElement element)
页面元素在页面中存在 presenceOfElementLocated(By locator)
在页面元素中是否包含特定的文本 text_To_Be_Present_In_Element(By locator)
页面元素值 textToBePresentInElementValue(By locator, java.lang.String text)
标题 (title) titleContains(java.lang.String title)
参见:【Selenium专题】元素定位之CssSelector
等待搜索框相应,并提交搜索关键词:
input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#q')))
# 等待搜索框加载完成 driver.findElement(By.cssSelector("#username"));只是 #id
#name = input("请输入搜索内容:")
input.send_keys("键盘") # 输入框中输入
提交搜索按钮:
sumbit=wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#J_TSearchForm > div.search-button > button'))) # 等待搜索按钮相应
sumbit.click() # 点击搜索按钮
copy selector
#spulist-pager > div > div > div > div.total寻找查找结果数量:
total=wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div.total')))大体框架
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
import re
browser=webdriver.Chrome() #创建webdriver对象
wait=WebDriverWait(browser, 10)
def get_search(url):
try:
browser.get(url)
input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#q')))
# 等待搜索框加载完成 driver.findElement(By.cssSelector("#username"));只是 #id
#name = input("请输入搜索内容:")
input.send_keys("键盘") # 输入框中输入
sumbit=wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#J_TSearchForm > div.search-button > button')))
sumbit.click()
total=wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div.total')))
return total.text
except TimeoutException:##spulist-pager > div > div > div > div.total
return search
def main():
url = 'https://www.taobao.com'
total = get_search(url)
total = int(re.compile('(\d+)').search(total).group(1))
print("抓取到{}页信息".format(total))
if __name__ == '__main__':
main()
total = int(re.compile('(\d+)').search(total).group(1))这是函数式用法,一次性操作
其实就等于:
pat = re.compile(r'(\d+)')
total = int(pat.search(total).group(1))
详细用法参见:Python RE库
FileNotFoundError: [Errno 2] No such file or directory: 'chromedriver'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "taobao_Search.py", line 9, in
browser=webdriver.Chrome() #创建webdriver对象
File "/home/pit-yk/anaconda3/lib/python3.6/site-packages/selenium/webdriver/chrome/webdriver.py", line 62, in __init__
self.service.start()
File "/home/pit-yk/anaconda3/lib/python3.6/site-packages/selenium/webdriver/common/service.py", line 81, in start
os.path.basename(self.path), self.start_error_message)
selenium.common.exceptions.WebDriverException: Message: 'chromedriver' executable needs to be in PATH. Please see https://sites.google.com/a/chromium.org/chromedriver/home 得到一个新的弹窗:

好了,浏览器已经执行了搜索功能,紧接着应该就是翻页了,不能老是盯着第一页看哈
![]()

手动输入页码进行翻页,
等待页码输入框和确定按钮加载完成,
然后将搜索框清空,
填入页面号码,点击确定,
确定页面号码是否填入。
input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.form > input")))
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.form > span.btn.J_Submit")))
input.clear()
input.send_keys(page_number)
submit.click()
wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR, '#mainsrp-pager > div > div > div > ul > li.item.active > span'), str(page_number))) #判断str(page_number)是否在文本中
实现翻页:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
import re
browser=webdriver.Chrome() #创建webdriver对象
wait=WebDriverWait(browser, 10)
def get_search(url):
try:
browser.get(url)
input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#q')))
# 等待搜索框加载完成 driver.findElement(By.cssSelector("#username"));只是 #id
#name = input("请输入搜索内容:")
input.send_keys("CMCC") # 输入框中输入
sumbit=wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#J_TSearchForm > div.search-button > button')))
sumbit.click()
total=wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div.total')))
return total.text
except TimeoutException:
return search
'''
显性等待:WebDriverWait,配合该类的until()和until_not()方法进行的等待。
它主要的意思就是:程序每隔xx秒看一眼,如果条件成立了,则执行下一步,否则继续等待,直到超过设置的最长时间,然后抛出TimeoutException。
调用方法如下:
WebDriverWait(driver, 超时时长, 调用频率, 忽略异常).until(可执行方法, 超时时返回的信息)
'''
def next_page(page_number):# #mainsrp-pager > div > div > div > div.form > input
try:
input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.form > input")))#搜索框
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.form > span.btn.J_Submit")))
input.clear()
input.send_keys(page_number)
submit.click()
wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR, '#mainsrp-pager > div > div > div > ul > li.item.active > span'), str(page_number))) #判断str(page_number)是否在文本中
print("正在浏览第{}页...".format(page_number))
except TimeoutException:
next_page(page_number)
def main():
url = 'https://www.taobao.com'
total = get_search(url)
total = int(re.compile('(\d+)').search(total).group(1))
print("抓取到{}页信息".format(total))
# 由于第一页本身就是显示出来的,从第2页开始遍历
for i in range(2,5+1):
next_page(i)
if __name__ == '__main__':
main()
输出结果:
$ python taobao_Search.py
抓取到100页信息
正在浏览第2页...
正在浏览第3页...
正在浏览第4页...
正在浏览第5页...
好啦,但是目前这个情况就是有一个真实存在浏览器界面在操作,并且还用商品情况没有扣取出来,下面将实现获取商品信息:

观察到这些都是商品,由于第一个商品的class和其他的有所不同,从大局出发,放弃了对于第一个商品的爬取,但是应该根据科学的严谨性这个程序是失败的,哈哈
对商品信息进行分析后,得出:
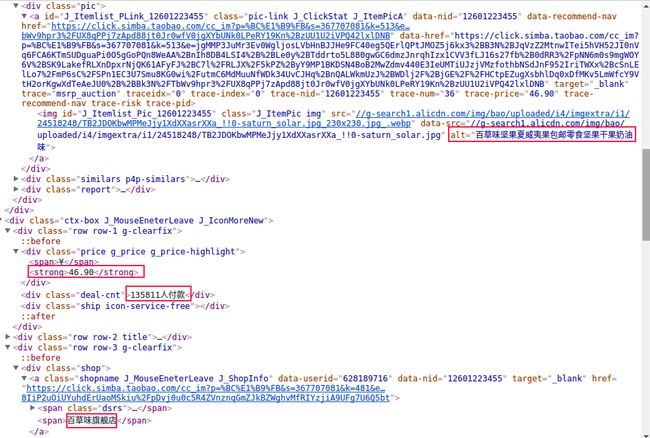
product['商品价格']=item.find_element_by_xpath('.//*[@class="price g_price g_price-highlight"]/strong').text
product['付款人数']=item.find_element_by_xpath('.//*[@class="deal-cnt"]').text
product['商品介绍']=item.find_element_by_xpath('.//*[@class="pic-link J_ClickStat J_ItemPicA"]/img').get_attribute('alt')
try:
product['商店名称']=item.find_element_by_xpath('.//*[@class="shop"]/a/span[2]').text #
except:
product['商店名称']=item.find_element_by_xpath('.//*[@class="shop"]/a').text #
由于存在部分商店名称有差异,所以进行try语句的甄别
最后对爬取的商品进行一个简单的价格排序,以及csv格式存储;
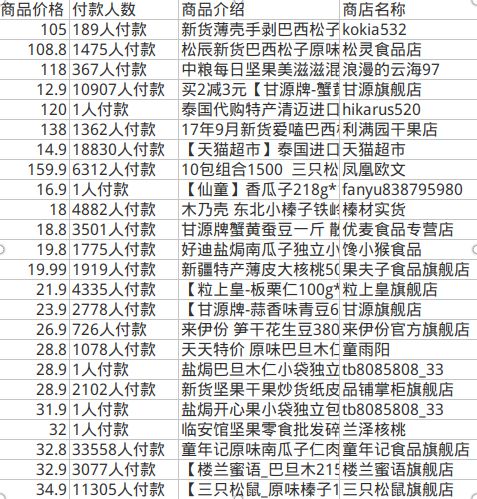
最终代码如下:
# https://www.qcloud.com/community/article/703975
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
import re
import csv
import os
'''
browser=webdriver.Chrome() #创建webdriver对象
wait=WebDriverWait(browser, 10)
'''
# SERVICE_ARGS = ['--load-images=false', '--disk-cache=true'] # 设置缓存和禁用图片加载功能
browser = webdriver.Chrome()
wait = WebDriverWait(browser, 10)
browser.set_window_size(1400, 900)
products = []
def get_search(url):
try:
print("正在打开网页...")
browser.get(url)
input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#q')))
# 等待搜索框加载完成 driver.findElement(By.cssSelector("#username"));只是 #id
input.send_keys("坚果") #输入框中输入
print("搜索中...")
sumbit=wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#J_TSearchForm > div.search-button > button')))
sumbit.click()
total=wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div.total')))
print("正在浏览第一页...")
get_products()
return total.text
except TimeoutException:
#browser.quit();
#browser.close();
return get_search(url)
'''
显性等待:WebDriverWait,配合该类的until()和until_not()方法进行的等待。
它主要的意思就是:程序每隔xx秒看一眼,如果条件成立了,则执行下一步,否则继续等待,直到超过设置的最长时间,然后抛出TimeoutException。
调用方法如下:
WebDriverWait(driver, 超时时长, 调用频率, 忽略异常).until(可执行方法, 超时时返回的信息)
'''
def get_products():
items =browser.find_elements_by_xpath('//*[@class="item J_MouserOnverReq "]')
# //*[@id="J_Itemlist_Pic_541203315153"]
for item in items:
product = {}
#print(item)
# //*[@id="J_Itemlist_Pic_541203315153
#product['商品图片']=item.find_element_by_xpath('.//*[@class="pic"]/a/img').get_attribute('data-src')
product['商品价格']=item.find_element_by_xpath('.//*[@class="price g_price g_price-highlight"]/strong').text
product['付款人数']=item.find_element_by_xpath('.//*[@class="deal-cnt"]').text
product['商品介绍']=item.find_element_by_xpath('.//*[@class="pic-link J_ClickStat J_ItemPicA"]/img').get_attribute('alt')
try:
product['商店名称']=item.find_element_by_xpath('.//*[@class="shop"]/a/span[2]').text #
except:
product['商店名称']=item.find_element_by_xpath('.//*[@class="shop"]/a').text #
#print(product)
# product['商店名称']=item.find_element_by_xpath('.//*[@class="shop"]/a/span[2]').text
products.append(product)
def next_page(page_number):# #mainsrp-pager > div > div > div > div.form > input
try:
input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.form > input")))#搜索框
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.form > span.btn.J_Submit")))
input.clear()
input.send_keys(page_number)
submit.click()
wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR, '#mainsrp-pager > div > div > div > ul > li.item.active > span'), str(page_number))) #判断str(page_number)是否在文本中
print("正在浏览第{}页...".format(page_number))
get_products()
except TimeoutException:
next_page(page_number)
def main():
url = 'https://www.taobao.com'
#name = input("请输入搜索内容:")
total = get_search(url)
total = int(re.compile('(\d+)').search(total).group(1))
print("抓取到{}页信息".format(total))
# 由于第一页本身就是显示出来的,从第2页开始遍历
for i in range(2,2+3):
next_page(i)
products.sort(key =lambda x:x["商品价格"])
'''
for product in products:
print(product)
'''
att=['商品价格','付款人数','商品介绍','商店名称']
with open("{}/products.csv".format(os.getcwd()),'w+') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(att)
for product in products:
pro = []
#print(product)
pro.append(product['商品价格'])
pro.append(product['付款人数'])
pro.append(product['商品介绍'])
pro.append(product['商店名称'])
writer.writerow(pro)
browser.quit();
# browser.close();
if __name__ == '__main__':
main()