深入了解分布式事务组件 Seata :AT 模式(二)
在前面一篇文章,我们介绍了阿里开源的分布式事务组件 Seata 的相关概念,重点介绍了 Seata 的 AT 模式。并通过一个 Spring-Cloud-JPA 的案例,演示了 AT 模式的使用入门。本文将会结合 Spring-Cloud-JPA 的案例,深入了解 Seata AT 模式的工作流程。本文基于 v0.8.1。
AT 模式与 TCC 模式
Seata AT 模式是基于两阶段提交模式设计的,以高效且对业务零侵入的方式,解决微服务场景下面临的分布式事务问题。它使得应用代码可以像使用本地事务一样使用分布式事务,完全屏蔽了底层细节,Seata AT 模式与 Seata MT(TCC) 模式的区别有以下几点:
- 使用上,TCC 依赖于用户自行实现的三个方法成本较大;AT 依赖全局事务注解和代理数据源,其余代码基本不需要改动,对业务无侵入、接入成本极小;
- TCC 的作用范围在应用层,本质上是实现针对某种业务逻辑的正向和反向方法;AT 模式的作用范围在于底层数据源,通过保存操作行记录的前后快照和生成反向 SQL 语句进行补偿操作,实现难度较大,优点是对上层应用透明;
- TCC 仅 try 阶段加锁,后续补偿逻辑事务间各自独立;AT 需要借助于全局锁和 GlobalLock 注解来解决不同全局事务间的写冲突问题,如果一阶段分支事务成功则二阶段一开始全局锁即被释放,否则需要夯住直到分支事务二阶段回滚完成才能释放全局锁。
AT 模式下,把每个数据库被当做是一个 Resource,Seata 里称为 DataSource Resource。业务通过 JDBC 标准接口访问数据库资源时,Seata 框架会对所有请求进行拦截,做一些操作。每个本地事务提交时,Seata RM(Resource Manager,资源管理器) 都会向 TC(Transaction Coordinator,事务协调器) 注册一个分支事务。当请求链路调用完成后,发起方通知 TC 提交或回滚分布式事务,进入二阶段调用流程。此时,TC 会根据之前注册的分支事务回调到对应参与者去执行对应资源的第二阶段。TC 是怎么找到分支事务与资源的对应关系呢?每个资源都有一个全局唯一的资源 ID,并且在初始化时用该 ID 向 TC 注册资源。在运行时,每个分支事务的注册都会带上其资源 ID。这样 TC 就能在二阶段调用时正确找到对应的资源。
关于 AT 模式用法,这里就不赘述了,主要包括以下几点:
- 增加全局事务注解
@GlobalTransactional:在整个分布式事务发起方的业务方法上增加; - 配置代理数据源:配置 Seata 的代理数据源
- 新建 undo_log 表:在事务链涉及的服务的数据库中新建 undo_log 表用来存储 UndoLog 信息,用于二阶段回滚操作,表中包含 xid、branchId、rollback_info 等关键字段信息。
AT 模式的架构与实现原理介绍
分布式事务是一个全局事务,由多个分支事务组成,Seata AT 模式具体包括如下两个阶段:
- 阶段 1:分支(本地)事务执行。将一个本地事务做为一个分布式事务分支,所以若干个分布在不同微服务中的本地事务共同组成了一个全局事务,结构如下。

- 阶段 2:分支事务提交或回滚。阶段 2 完成的是全局事物的最终提交或回滚,当全局事务中所有分支事务全部完成并且都执行成功,这时TM会发起全局事务提交,TC收到全全局事务提交消息后,会通知各分支事务进行提交;同理,当全局事务中所有分支事务全部完成并且某个分支事务失败了,TM会通知TC协调全局事务回滚,进而TC通知各分支事务进行回滚。
在业务应用启动过程中,由于引入了 Seata 客户端,RmRpcClient会随应用一起启动,该RmRpcClient采用Netty实现,可以接收TC消息和向TC发送消息,因此RmRpcClient是与TC收发消息的关键模块。
Seata 实现分布式事务的一般过程如下:
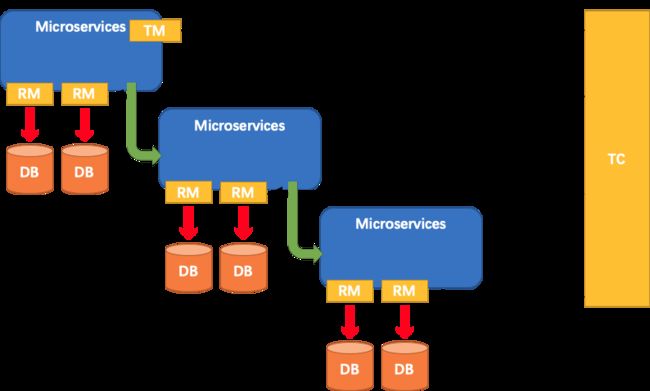
- TM 通知 TC 开始一个新的全局事务。TC 生成了一个代表全局事务的 XID。
- XID 通过微服务的调用链传播下去。
- RM将本地事务注册为XID到TC的相应全局事务的分支。
- TM 通知 TC 提交或者回滚 XID 对应的全局事务
- TC 驱动 XID 的对应全局事务下的所有分支事务以完成分支提交或回滚。
一阶段流程
在一阶段,Seata 会拦截业务 SQL,首先解析 SQL 语义,找到业务 SQL要更新的业务数据,在业务数据被更新前,将其保存成 before image,然后执行业务 SQL 更新业务数据,在业务数据更新之后,再将其保存成 after image,最后生成行锁。以上操作全部在一个数据库事务内完成,这样保证了一阶段操作的原子性。
一阶段中分支事务的具体工作有:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Jq5JsTrU-1574956653703)(https://ww1.sinaimg.cn/large/c3beb895ly1g4lntfoi5ij20q50l5wg1.jpg “图片来自网络”)]
- 根据需要执行的 SQL(UPDATE、INSERT、DELETE)类型生成相应的 SqlRecognizer
- 生成相应的 SqlExecutor
- 进入核心逻辑查询数据的前后快照,例如图中标红的部分,拿到修改数据行的前后快照之后,将二者整合生成 UndoLog,并尝试将其和业务修改在同一事务中提交。
实现上,Seata 对数据源做了封装代理,然后对于数据源的操作处理,就由 Seata 内部逻辑完成了。如我们之前例子中的数据源加载配置:
@Configuration
public class DataSourceConfig {
@Bean
@ConfigurationProperties(prefix = "spring.datasource")
public DruidDataSource druidDataSource() {
return new DruidDataSource();
}
@Primary
@Bean("dataSource")
public DataSource dataSource(DruidDataSource druidDataSource) {
return new DataSourceProxy(druidDataSource);
}
}
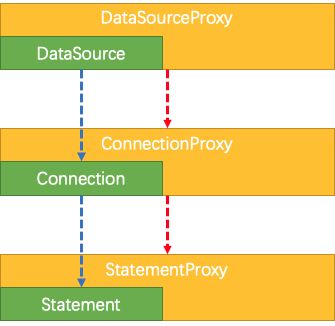
可以看到,我们使用的是 Seata 封装的代理数据源 DataSourceProxy。 DataSourceProxy 初始化时,会进行 Resouce 注册:
private void init(DataSource dataSource, String resourceGroupId) {
this.resourceGroupId = resourceGroupId;
Connection connection = dataSource.getConnection()
jdbcUrl = connection.getMetaData().getURL();
dbType = JdbcUtils.getDbType(jdbcUrl, null);
DefaultResourceManager.get().registerResource(this);
}
其实,数据源代理部分有三类 Proxy,Seata 除了对数据库的 DataSource 进行了封装,同样也对 Connection,Statement 进行了封装代理,分别为 ConnectionProxy 和 StatementProxy。
二阶段 Commit 流程
AT 模式的第二阶段会根据第一阶段的情况决定是进行全局提交还是全局回滚操作。对服务端来说,等到一阶段完成未抛异常,全局事务的发起方会向服务端申请提交这个全局事务,服务端根据 xid 查询出该全局事务后加锁并关闭这个全局事务,目的是防止该事务后续还有分支继续注册上来,同时将其状态从 Begin 修改为 Committing。
紧接着,判断该全局事务下的分支类型是否均为 AT 类型,若是则服务端会进行异步提交,因为 AT 模式下一阶段完成数据已经落地。服务端仅仅修改全局事务状态为 AsyncCommitting,然后会有一个定时线程池去存储介质(File 或者 Database)中查询出待提交的全局事务日志进行提交,如果全局事务提交成功则会释放全局锁并删除事务日志。整个流程如下图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LLMXos6v-1574956653704)(https://ww1.sinaimg.cn/large/c3beb895ly1g4npuh7hwqj20hx0s3wfe.jpg “图片来自网络”)]
如果所有 Branch RM 都执行成功了,那么就进行全局 Commit。因为此时我们不用回滚,而每个 Branch 本地数据库操作已经完成了,那么我们其实主要做的事情就是把本地的 Undolog 删了即可。
对客户端来说,先是接收到服务端发送的 branch commit 请求,然后客户端会根据 resourceId 找到相应的 ResourceManager,接着将分支提交请求封装成 Phase2Context 插入内存队列 ASYNC_COMMIT_BUFFER,客户端会有一个定时线程池去查询该队列进行 UndoLog 的异步删除。
一旦客户端提交失败或者 RPC 超时,则服务端会将该全局事务状态置位 CommitRetrying,之后会由另一个定时线程池去一直重试这些事务直至成功。
二阶段 Rollback 流程
二阶段如果是回滚的话,Seata 就需要回滚一阶段已经执行的业务 SQL,还原业务数据。回滚方式便是用 before image 还原业务数据;但在还原前要首先要校验脏写,对比数据库当前业务数据和 after image,如果两份数据完全一致就说明没有脏写,可以还原业务数据,如果不一致就说明有脏写,出现脏写就需要转人工处理。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JRmcxpjP-1574956653705)(https://ww1.sinaimg.cn/large/c3beb895gy1g4n22hpxcvj20fl0gkt92.jpg “图片来自网络”)]
回滚相对复杂一些,如果发起方一阶段抛异常会向服务端请求回滚该全局事务,服务端会根据 xid 查询出这个全局事务,加锁关闭事务使得后续不会再有分支注册上来,并同时更改其状态 Begin 为 Rollbacking,接着进行同步回滚以保证数据一致性。除了同步回滚这个点外,其他流程同提交时相似,如果同步回滚成功则释放全局锁并删除事务日志,如果失败则会进行异步重试。
客户端接收到服务端的 branch rollback 请求,先根据 resourceId 拿到对应的数据源代理,然后根据 xid 和 branchId 查询出 UndoLog 记录,反序列化其中的 rollback 字段拿到数据的前后快照,我们称该全局事务为 A。
根据具体 SQL 类型生成对应的 UndoExecutor,校验一下数据 UndoLog 中的前后快照是否一致或者前置快照和当前数据(这里需要 SELECT 一次)是否一致,如果一致说明不需要做回滚操作,如果不一致则生成反向 SQL 进行补偿,在提交本地事务前会检测获取数据库本地锁是否成功,如果失败则说明存在其他全局事务(假设称之为 B)的一阶段正在修改相同的行,但是由于这些行的主键在服务端已经被当前正在执行二阶段回滚的全局事务 A 锁定,因此事务 B 的一阶段在本地提交前尝试获取全局锁一定是失败的,等到获取全局锁超时后全局事务 B 会释放本地锁,这样全局事务 A 就可以继续进行本地事务的提交,成功之后删除本地 UndoLog 记录。
小结
本文主要介绍了 AT 模式下, Seata 的客户端和服务端的工作流程。AT 模式的一阶段、二阶段提交和回滚均由 Seata 框架自动生成,用户只需编写业务 SQL,便能轻松接入分布式事务,AT 模式是一种对业务无任何侵入的分布式事务解决方案。下篇文章开始将会结合源码具体讲解 AT 模式的实现。
推荐阅读
微服务合集
订阅最新文章,欢迎关注我的公众号
参考
- [图文] Seata AT 模式分布式事务源码分析
- Seata.io