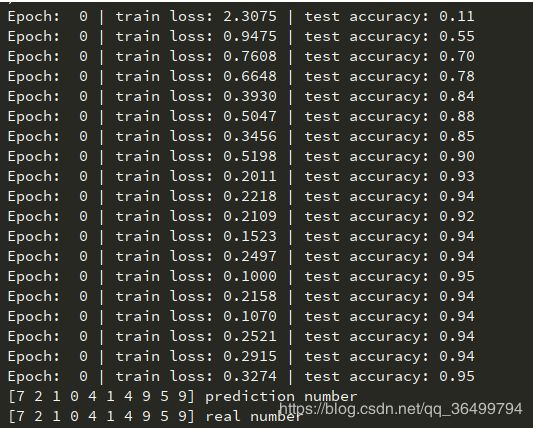
注意看代码注释,解析全在注释里面了。
1. 代码
import torch
from torch import nn
import torchvision.datasets as dsets
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
# torch.manual_seed(1) # reproducible
# 定义一些参数
EPOCH = 1 # 训练次数
BATCH_SIZE = 64 # 一次训练的数据量,可以理解为有多少条句子
TIME_STEP = 28 # 可以理解为一个句子的序列长度
INPUT_SIZE = 28 # 可以理解为每个词向量的维度,也就是输入维度,假如是3,那就是3
LR = 0.01 # learning rate
DOWNLOAD_MNIST = False # set to True if haven't download the data
# 定义数据集
train_data = dsets.MNIST(
root='./mnist/',
train=True, # this is training data
transform=transforms.ToTensor(), # Converts a PIL.Image or numpy.ndarray to
# torch.FloatTensor of shape (C x H x W) and normalize in the range [0.0, 1.0]
download=DOWNLOAD_MNIST, # download it if you don't have it
)
# plot one example
print(train_data.train_data.size()) # (60000, 28, 28)
print(train_data.train_labels.size()) # (60000)
plt.imshow(train_data.train_data[0].numpy(), cmap='gray')
plt.title('%i' % train_data.train_labels[0])
plt.show()
# 加载训练数据
train_loader = torch.utils.data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
# convert test data into Variable, pick 2000 samples to speed up testing
test_data = dsets.MNIST(root='./mnist/', train=False, transform=transforms.ToTensor())
test_x = test_data.test_data.type(torch.FloatTensor)[:2000]/255. # shape (2000, 28, 28) value in range(0,1)
test_y = test_data.test_labels.numpy()[:2000] # covert to numpy array
# 定义LSTM网络模型
class RNN(nn.Module):
def __init__(self):
super(RNN, self).__init__()
self.rnn = nn.LSTM( # if use nn.RNN(), it hardly learns
input_size=INPUT_SIZE, # 输入维度
hidden_size=28, # 隐藏层神经元节点个数
num_layers=2, # 神经元层数
batch_first=True, # input & output will has batch size as 1s dimension. e.g. (batch, time_step, input_size)
)
self.out = nn.Linear(28, 10) # 定义全连接层
def forward(self, x):
# x shape (batch, time_step, input_size)
# r_out shape (batch, time_step, output_size)
# h_n shape (n_layers, batch, hidden_size)
# h_c shape (n_layers, batch, hidden_size)
r_out, (h_n, h_c) = self.rnn(x, None) # h_n就是h状态,h_c就是细胞的状态
# choose r_out at the last time step
out = self.out(r_out[:, -1, :]) # 我们只要每一个time_step里的最后的一个。比如64个矩阵,每个28*28,我们只要每一个的第28次的那个数据。
return out
rnn = RNN()
print(rnn)
optimizer = torch.optim.Adam(rnn.parameters(), lr=LR) # optimize all cnn parameters
loss_func = nn.CrossEntropyLoss() # the target label is not one-hotted
# training and testing
for epoch in range(EPOCH):
for step, (b_x, b_y) in enumerate(train_loader): # gives batch data
# print('before reshape x: ',b_x)
b_x = b_x.view(-1, 28, 28) # reshape x to (batch, time_step, input_size)
# print('after reshape x: ',b_x)
# print('result b_y: ',b_y)
output = rnn(b_x) # rnn output
# print(output)
# print(torch.max(output, 1))
# print(torch.max(output, 1)[1])
loss = loss_func(output, b_y) # cross entropy loss
optimizer.zero_grad() # clear gradients for this training step
loss.backward() # backpropagation, compute gradients
optimizer.step() # apply gradients
# test_output = rnn(test_x) # (samples, time_step, input_size)
# print('output: ',test_output)
# print(torch.max(test_output, 1))
# print(torch.max(test_output, 1)[1])
# pred_y = torch.max(test_output, 1)[1].data.numpy()
# print(pred_y)
# print(test_y)
# break
if step % 50 == 0:
test_output = rnn(test_x) # (samples, time_step, input_size)
pred_y = torch.max(test_output, 1)[1].data.numpy()
accuracy = float((pred_y == test_y).astype(int).sum()) / float(test_y.size)
print('Epoch: ', epoch, '| train loss: %.4f' % loss.data.numpy(), '| test accuracy: %.2f' % accuracy)
# print 10 predictions from test data
test_output = rnn(test_x[:10].view(-1, 28, 28))
pred_y = torch.max(test_output, 1)[1].data.numpy()
print(pred_y, 'prediction number')
print(test_y[:10], 'real number')
2. 运行结果