ANN:Asymmetric Non-local Neural Networks for Semantic Segmentation 文章解读
《Asymmetric Non-local Neural Networks for Semantic Segmentation 》文章解读
网络简介
文中提出了两个模块Asymmetric Pyramid Non-local Block (APNB) 和Asymmetric Fusion Non-local Block (AFNB)。APNB将金字塔采样利用到non-local块中,在不牺牲性能的情况下大大降低了计算量和内存消耗,AFNB由APNB改造而来,在充分考虑到远程依赖关系的情况下融合了不同级别的特征。
一些研究表明如果充分利用远程依赖关系,可以提高网络性能,单个卷积核的感受野不足以覆盖相关区域,选择大尺寸的卷积核或者级联组成较深的网络可以提高网络的感受野但是计算量和参数量太大,所以一些研究使用全局方法比如non-local means或者spp。
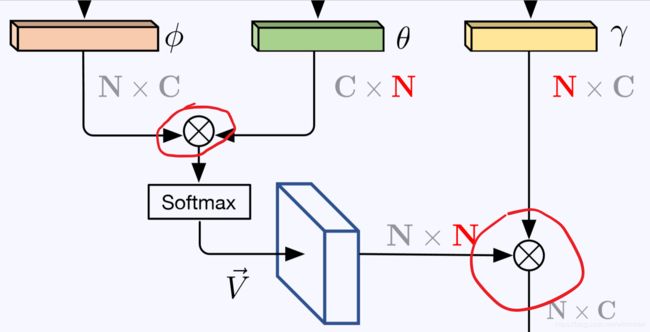
在王小龙的《 Non-local neural networks》里将CNN与传统non-local means结合,组合成了non-local block以便利用图像中所有位置的特征,该方法提高了性能但是计算量的增加限制了其使用场景。普通的non-local block如图a所示

这个块首先计算了所有位置之间的相似性,在输入特征图尺寸为CxHxW时所需要矩阵乘法的复杂度为O(CH2W2),然后同样需要一个复杂度为O(CH2W2)的乘法来手机所有位置对自己的影响。
我们注意到只要key和value分支的输出保持同样的尺寸,non-local block的输出将保持相同大小,所以作者上从key分支采样出几个代表性的点,把N采样到S,S<
Asymmetric Non-local Neural Network 结构详解
1.回顾Non-local Block
一个经典的non-local block结构如图所示

考虑输入特征为 X ∈ RC×H×W,首先有3个1x1卷积将特征图转化为三个特征,尺寸都为^C×H×W,通道数有所改变,然后将这三个特征展开为C×N的特征,其中N=H×W,然后相似矩阵V ∈RN×N 由前两个特征矩阵乘法计算而来:
V = φT ×θ
之后对V进行归一化得到相似矩阵→V,尺寸为N×N。(归一化函数可以为softmax,缩放或者none),在这里我们使用softmax,相当于一个self attention机制)。 attention层输出结果为O=→V × γT,O ∈ RN׈ C
最终non-local block的输出结果为:
Y = Wo(OT) + X 或者Y = cat(Wo(OT),X),
Wo是一个1x1的卷积操作,相当于一个通道上的权重参数,同时还原通道数C,然后通过summation或者concat与原输入特征结合在一起。
2.Asymmetric Pyramid Non-local Block(APNB)
non-local block有效地捕获了远程依赖关系,但是non-local操作相比于传统卷积核激活操作而言非常耗时耗内存,仔细观察可以发现non-block中
这两个矩阵乘法占据了主要的计算量,这两步的时间复杂度都为O( ˆCN2) = O( ˆCH2W2)。在语义分割中,为了保留细节的语义特征,网络的输出通常有很高的分辨率,这意味着N=H×W会很大,所以大矩阵的乘法运算是导致non-local效率低下的主要原因。non-local运算更为直接的流程如下:

从公式的角度出发,发现如果将N改为另一个值S(S<
回到non-local的流程图来看,相当于从 θ and γ中采样出几个代表点,而不是将所有点都带入运算,即展开后形状为C×N的特征,从N中采样出S个代表点进行下一步运算,计算复杂度就能大大减小,流程图更改后如下:
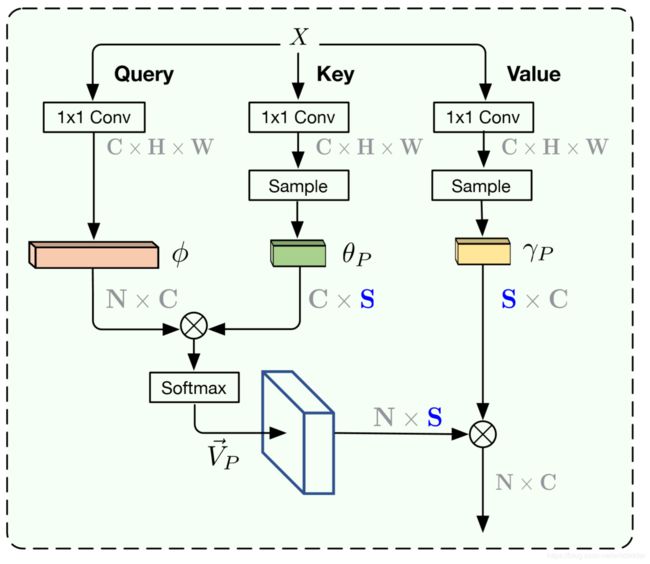
方案:
基于以上观察,作者提出加入两个采样模型 Pθ 和 Pγ ,对 θ 和 γ 采样出几个稀疏的锚点 θP ∈ R^ˆ C×S^ 和 γP ∈ R^ˆ C×S^
所以通过 Vp= φT × θp 计算出来的是θp和φ之间的相似度矩阵,Vp的尺寸是N × S。Vp经过与标准non-local块同样的归一化操作之后,继续计算attention:
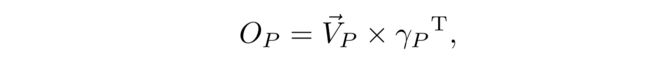
最后的输出为;

这种非对称的矩阵乘法时间复杂度为O( ˆCNS), 远小于标准non-local的O( ˆCN2),理想情况下S应该远小于N才能保证计算优势,但是很难保证S多小时性能会下降太多。
全局和多尺度表示对于语义分割很有效果,可以通过SPP(Spatial Pyramid Pooling)来实现,SPP没有参数而且非常有效,作者将其嵌入non-local来增强全局表示同时减少计算开销。
这样得到了APNB的最终结构:

可以看出APNB源自标准的non-local block, key 和 value 分支共享一个1
×1卷积核采样模块,这样在没有牺牲性能的情况下降低了参数量。采样模块用的时SPP:

其中n表示采样后的边长,取四个{1,3,6,8},也就是一共有4个并行的pool,最后展开得到S=∑n2=110,所以非对称non-local的计算复杂度仅为原来的S/N,当输入H=128,W=256时,节省了大约298倍的计算时间。另外,SPP提供了全局场景语义线索的足够特征统计信息,以纠正由于减少计算量导致的性能下降。
3.Asymmetric Fusion Non-local Block
很多工作提到不同级别的特征融合有助于语义分割和目标跟踪,但常见的方法是添加像素之间的局部连接,作者提出一种non-local长依赖的多级融合方式,成为Fusion Non-local Block(FNB)。
一个标准的non-local block只有一个输入,而FNB有两个:高级别的特征图Xh和低级别的特征图Xl:
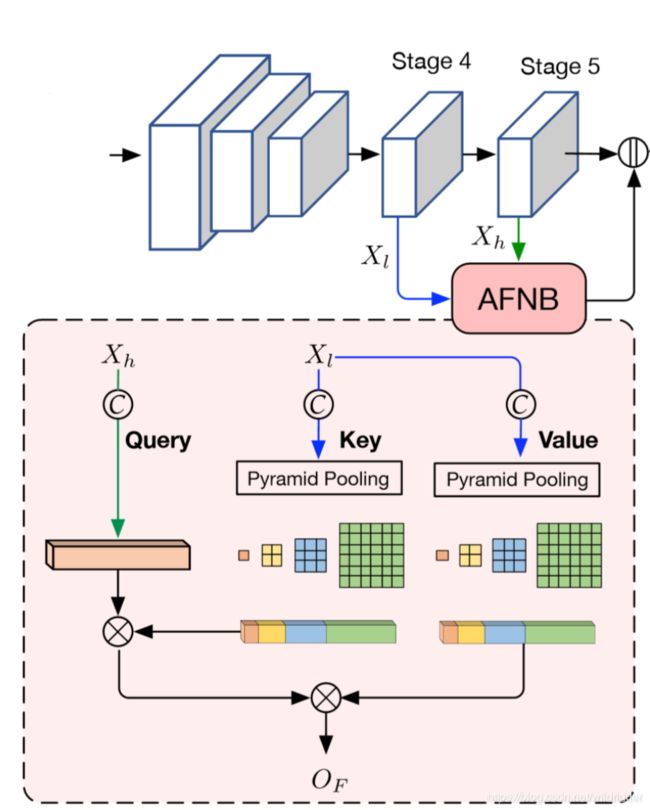
参照APNB的计算过程,得到的输出OF反映出Xl中全局特征对Xh的影响,OF经过一个1×1卷积恢复通道数后,得到最终输出:

4.网络结构
网络的整体结构如图所示:

作者选择了ResNet101作为backbone,移除了最后两个下采样层,使用空洞卷积以维持分辨率,使最后输出分辨率是输入图像的1/8,最后的三个stage都维持了相同的分辨率。将第四个和第五个stage的特征用AFNB混合后,与第五个stage的输出concat在一起,这样的特征充满了来自不同级别特征的大范围线索,将其作为APNB的输入,然后帮助发现像素之间的相关性。APNB的输出同样和输入concat在一起,最后送入一个分类器生成通道语义特征图,之后用于监督训练。
总的来说,APNB旨在减少 non-local block 的计算开销,而AFNB通过提高non-local block的学习能力来提高分割性能。
实验
作者在 Cityscapes, ADE20K 和 PASCAL Context 上做了实验,并在NYUD-V2 和 COCOStuff-10K 上做了补充实验。
APNB对比普通NB(Non-local Block)

可见采用APNB后,FLops和内存占用以及推理时间都大大优化
在各个数据集上与SOTA对比:
CityScapes:

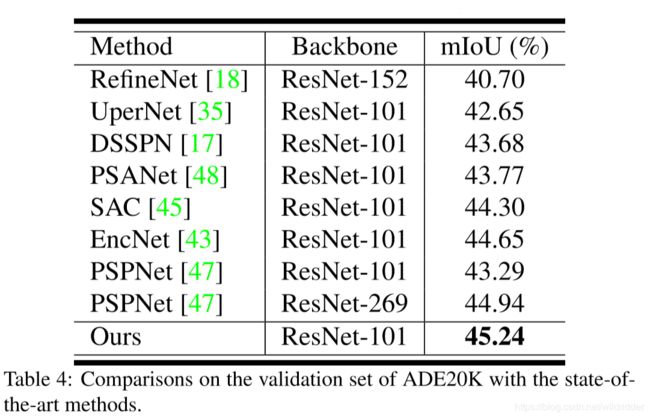
ADE20K:
PASCAL Context:

消融实验:

在消融实验中往往更能看出网络结构中每个模块的作用,跟Baseline对比,加上普通的NB(Non-local Block)没有APNB好,这说明APNB在大大降低计算量和内存占用的同时,还提高了性能,这应该是与SPP的全局信息表示能力有关。而在高级特征低级特征融合方面,普通的融合FNB和借鉴了APNB思路的AFNB相比则更胜一筹,最后同时使用APNB和AFNB效果更好。
但是这里作者没有给出APNB和FNB组合的效果,应该是更好的,但是AFNB的计算量还是大大降低了。
采样方法的选择:
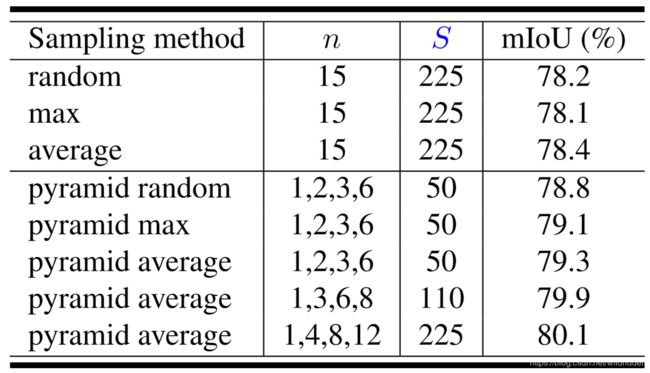
可见SPP还是明显优于普通的random、max、average方法,且在SPP的池化方法中,平均池化效果最好,而在池化尺寸的选择上,{1,4,8,12} 效果最好,但是考虑到计算量,还是选择 {1,3,6,8} 作为默认值。
分割效果对比:
其中红圈部分是由于其他网络的细节,可见在围栏、建筑物等大型物体上,以及电线杆等细长物体上 ANN更好。
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #
背景知识Non-local Networks ,可以参考这两位的说明:
ICCV2019 语义分割之高效Non-local Networks - 杨先生的文章 - 知乎
https://zhuanlan.zhihu.com/p/80254858
Non-local neural networks - Gapeng的文章 - 知乎
https://zhuanlan.zhihu.com/p/33345791