python网络爬虫学习笔记(一)配置安装python环境
博主的毕设是要做一个指定领域的问答系统,寒假要做的就是确定领域,拿到数据。自己比较喜欢看书,所以选择书籍领域,数据找了好久都没找到现成的数据,就想着自己学学python写写爬虫,上网爬些数据。但对python一丁点都不了解,在学习的过程中整理了一下笔记。
一、下载python
请移步至python下载地址。我下载的是3.6.x版本的。
二、配置环境变量
安装的时候好像有个选项勾上就已经自动配置好环境变量了,因为我乱改系统用户名以及注册表的原因,折腾了一下午。
三、下载Beautiful Soup4
Beautiful Soup是python的一个模块,对于python3.x必须安装Beautiful Soup4,其他版本可能安装不了。
下载地址
下载之后解压到安装目录下,在Beautiful Soup目录下打开cmd,执行 setup.py build 再执行 setup.py install。这样Beautiful Soup模块就成功安装到python中了。
四、下载lxml库
lxml
是
Python
语言里和
XML
以及
HTML
工作的功能最丰富和最容易使用的库。下载地址。
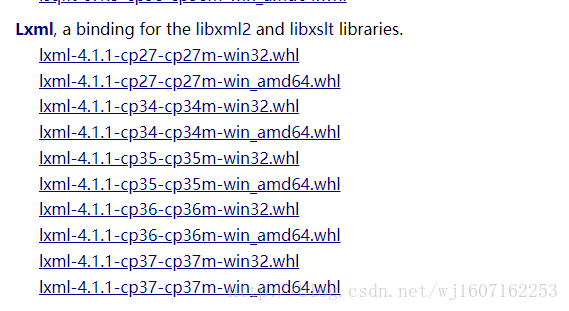
cp27代表是python2.7,cp34代表python3.4,amd64是64位的系统,不加代表32位。
下载后把它放进python的安装目录下,此操作与Beautiful Soup一样,这样主要是为了方便管理。在cmd命令里,先执行“python -m pip install wheel”,安装wheel,成功后在python目录下的Lib\site-packages,能查看到wheel文件夹,代表安装成功。
然后安装lxml,“python -m pip install 你的lxml的路径(D:\workapps\python3.4.4\lxml-3.6.4-.....)
五、试一试一个小demo
import urllib.request
url = "http://www.baidu.com"
page_info = urllib.request.urlopen(url).read()
page_info = page_info.decode('utf-8')
print(page_info)保存为baidu.py。进入存放文件的目录之后,执行python baidu.py ok啦~