【Python成长之路】卡萨帝冰箱能买吗?让数据来说话!

哈喽大家好,我是鹏哥。
今天我想与记录的是 —— python爬虫及文本情感分析。
~~~上课铃~~~
微微傅如乔 - 微微
1
写在前面
最近家里装修进度将近,因此家电采购的挑选就成了我空闲时间的填塞物。要买什么牌子的冰箱?哪些功能比较关键?……一开始是听从我爸的意见,想买卡萨帝BCD-520WICHUI,但是有一天心血来潮,想看看网上对这款冰箱的评价,所以就来一波python爬虫网友们的评论及自动完成相关的情感分析,让数据告诉你网友们对卡萨帝的评价。
2
效果展示
1、知乎话题(“卡萨帝冰箱怎么样”)的爬虫上千评论描述:
![]()
2、词云图分析
3、基于SnowNLP的情感分析

3
知识串讲(敲黑板啦)
(1)selenium爬虫
这里 selenium爬虫对象,我选择的是知乎。当然淘宝、京东等网站也是一样能爬虫的,只是这些网站上一般真实的差评会很少,经常会被店家各种处理,所以我选择知乎,至少我个人认为相当真实些。
爬虫流程:cookies保存、selenium库使用(登录知乎网站、爬取各类评价)。整体来说没有什么新的内容,所以我不再复述了,可以参考:
【Python成长之路】Boss直聘爬虫第2弹:selenium找不到元素的常见问题
当然,如果想要我的源码,可以到github上下载:
https://github.com/yuzipeng05/zhihu_spider.git
这里可能会有一个坑:如何将中文转成url码
因为访问知乎url时,如下:
![]()
但是复制后会变成:
https://www.zhihu.com/search?q=%E5%8D%A1%E8%90%A8%E5%B8%9D%E5%86%B0%E7%AE%B1%E6%80%8E%E4%B9%88%E6%A0%B7&utm_content=search_history&type=content
因此实际url是将“卡萨帝冰箱怎么样”进行了url转义。解决方法是用urllib库:
# 错误用法,会报找不到quote方法urllib.quote(question)# 正确用法urllib.parse.quote(question)
(2)词云图分析
词云图分析,之前也已经写过文章了,可以参考:
【Python成长之路】词云图制作
其实从效果来看,词云图需要对数据要求比较高,像爬虫的上千条评论进行绘制词云图是看不出什么内容的,只是看上去花里胡哨而已。如果是关键词和频率明确的话,效果才好。
(3)基于snownlp的情感分析
正是由于词云图无法帮助我快速从评价中得到结论:这款冰箱质量到底行不行啊?所以我这边又利用了snownlp库。
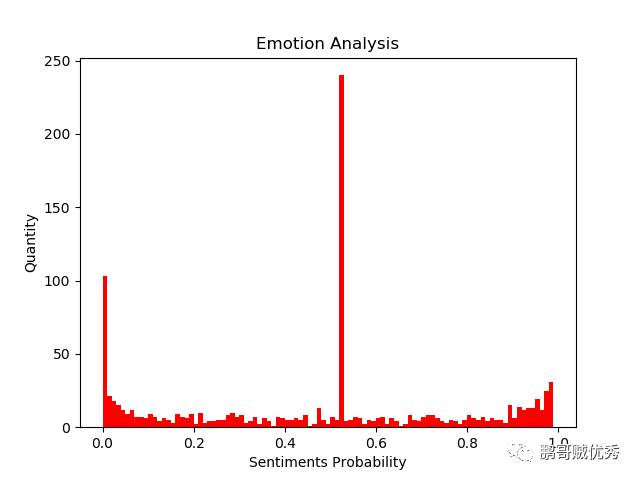
使用方法很简单,将comment文本作为 入参传给snownlp类,然后就会得到0-1的情感分析,其中0表示评价极差,1表示评价极好。
s = SnowNLP(comment)print(s.sentiments)
![]()
从这张情感分析的直方图数据来看,多数评价其实是0.5,这里是因为爬取到的内容中,有很多文字是单独地介绍产品信息,包括和其他产品的对比,因此判断为中性评价。下面我简单地列几条差评截图。
![]()


(4)绘图
绘图这块,可以用matplotlib库,也可以pyecharts库。
其中在使用pyecharts 库有3个坑:
(1)通过pip install pyecharts库经常超时
规避方法:通过清华大学的镜像下载,会加速很多,亲测有效
pip install --index https://mirrors.ustc.edu.cn/pypi/web/simple/ pyecharts(2)在如示例代码进行调用 Pie方法时,会报无法导入Bar、Pie、Map等。这里主要是因为新版本pyecharts库重构了方法,需要如下使用。
# 老版本pyechartsfrom pyecharts import Pie# 新版本pyecharts,但这条命令仍然有坑,看第3条from pyecharts.charts import Pie
(3)新版本Pyecharts用以下命令时,
from pyecharts.charts import Pie会报AttributeError: 'str' object has no attribute 'get'
规避方法:在一开始安装pyecharts时,要明确版本号,如pyecharts==0.1.9.4
4
示例代码
(1) snownlp情感分析的示例代码:
# coding=utf-8
# @公众号 : "鹏哥贼优秀"# @Date : 2020/5/15# @Software : PyCharm# @Python version: Python 3.7.2from snownlp import SnowNLPfrom pyecharts import Pieimport matplotlib.pyplot as pltimport numpy as npdef emotion_analysis(file):f = open(file, "r")comments = f.readlines()sentimentslist = []for comment in comments:s = SnowNLP(comment)print(s.sentiments)sentimentslist.append(s.sentiments)# 绘制直方图# plt.hist(sentimentslist, bins=np.arange(0, 1, 0.01), facecolor='red')# plt.xlabel('Sentiments Probability')# plt.ylabel('Quantity')# plt.title('Emotion Analysis')# plt.show()# 绘制圆饼图attr = ["很差", "较差", "一般", "较好", "很好"]v1 = [0 for i in range(5)]for i in sentimentslist:if i <= 0.2:v1[0] = v1[0] + 1elif 0.2 < i <= 0.4:v1[1] = v1[1] + 1elif 0.4 < i <= 0.6:v1[2] = v1[2] + 1elif 0.6 < i <= 0.8:v1[3] = v1[3] + 1else:v1[4] = v1[4] + 1pie = Pie('商品评价圆饼图')pie.add("", attr, v1,is_label_show=True)pie.render()if __name__ == "__main__":emotion_analysis("卡萨帝冰箱怎么样_内容.txt")
(2)知乎爬虫示例代码(cookies记录的相关代码就不附了):
# coding=utf-8# @公众号 : "鹏哥贼优秀"# @Date : 2020/5/15# @Software : PyCharm# @Python version: Python 3.7.2from record_cookies import *import urllibdef zhihu(question):url = 'https://www.zhihu.com/search?type=content&q={}'.format(urllib.parse.quote(question))option = webdriver.ChromeOptions()option.add_experimental_option('excludeSwitches', ['enable-automation'])driver = webdriver.Chrome('F:\\Python成长之路\\chromedriver.exe', options=option)driver.maximize_window()driver.get(url)time.sleep(3)# 加载cookiescookies = Cookies(driver)cookies.add_cookies()driver.get(url)time.sleep(3)# 加载所有搜索结果for i in range(5):js = 'var action=document.documentElement.scrollTop=50000'driver.execute_script(js)time.sleep(3)titles = driver.find_elements_by_xpath('//h2[@class="ContentItem-title"]/div/a')hrefs = []for title in titles:hrefs.append(title.get_attribute('href'))print(hrefs)# 对每一篇文章进行爬取评论for href in hrefs:driver.get(href)for i in range(5):try:comment_btn = driver.find_element_by_xpath \('//a[@class="QuestionMainAction ViewAll-QuestionMainAction"]')comment_btn.click()time.sleep(3)except:passfinally:js = 'var action=document.documentElement.scrollTop=50000'driver.execute_script(js)time.sleep(1)contents = driver.find_elements_by_xpath('//p')with open(question + '_内容.txt', 'a') as f:for content in contents:try:f.write(content.text+'\n')except:passdriver.close()if __name__ == "__main__":question = '卡萨帝冰箱怎么样'zhihu(question)
5
总结
下面我总结下自己这一周看冰箱下来的心得。
![]()
【参考】:https://zhuanlan.zhihu.com/p/136074643
~~~下课铃~~~

【往期热门文章】:
【Python成长之路】10行代码教你免费观看无广告版的《庆余年》腾讯视频
【Python成长之路】如何用python开发自己的iphone应用程序,并添加至siri指令
【Python成长之路】从 零做网站开发 -- 基于Flask和JQuery,实现表格管理平台

点击下方诗句,可以留言互动喔
浓墨难沾心事,寒夜怎寄相思。沉默有时念想有时。
【关注“鹏哥贼优秀”公众号,回复“python学习材料”,将会有python基础学习、机器学习、数据挖掘、高级编程教程等100G视频资料,及100+份python相关电子书免费赠送!】
扫描二维码
与鹏哥一起
学python吧!
