Object Detection -- 论文SSD(SSD: Single Shot MultiBox Detector)解读
SSD
Introduction
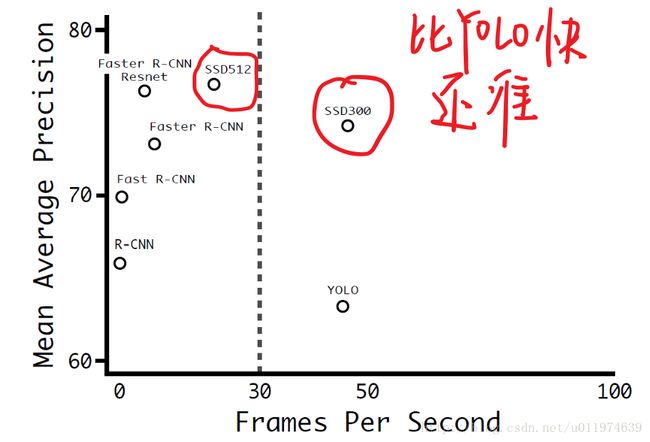
基于“Proposal + Classification” 的 Object Detection 的方法,R-CNN 系列取得了非常好的结果,但是在速度方面离实时引用还差的比较多。前面讲的YOLO虽然能够达到实时的效果,但是在准确度上与the-state-of-art 的结果有很大的差距。YOLO 的问题在于:每个网格只预测一个物体,容易造成漏检;对于物体的尺度相对比较敏感,对于尺度变化较大的物体泛化能力较差。
针对 YOLO 中的这些不足,该论文提出的SSD模型在这两方面都有所改进,同时兼顾了准确率和实时性的要求。(YOLO2还在SSD后,现在YOLO2是the-state-of-art)
SSD的特点在于:
- 从YOLO中继承了将detection转化为regression的思路,同时一次即可完成网络训练
- 基于Faster RCNN中的anchor,提出了相似的prior box;
- 加入基于特征金字塔(Pyramidal Feature Hierarchy)的检测方式,相当于半个FPN思路
SSD架构
论文采用VGG16的基础网络结构,使用前面的五个CONV层作为特征提取,然后利用astrous 算法将FC6和FC7转化成CONV6和CONV7层。再增加3个卷积层,和一个average pool层。
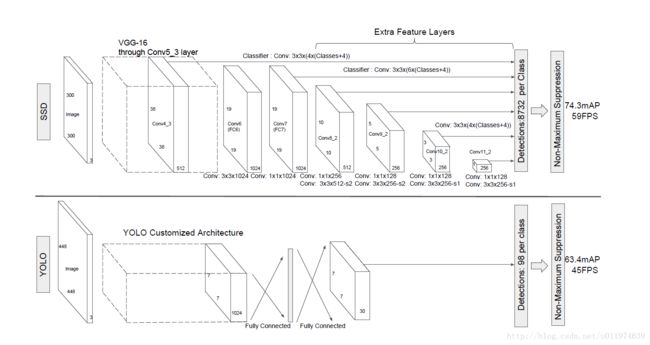
不同层次的feature map分别用于预测default box的偏移以及不同类别得分,最后通过 nms得到检测结果。
上图的下部分是YOLO结构,在卷积层后接全连接层,检测时只利用了最高层的feature maps(Faster R-CNN也是如此),而SSD采用了特征金字塔结构进行检测,即检测时用了conv4_3,conv_7,conv8_2,conv7_2,conv8_2,conv9_2,conv10_2,conv11_2这些大小不同的feature maps,在多个feature maps上同时进行softmax分类和位置回归,如下图: 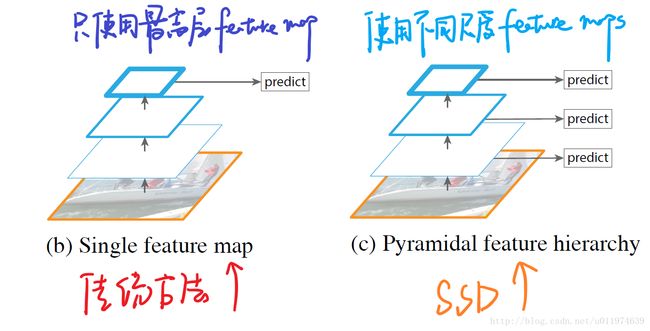
SSD上增加的卷积层的 feature maps的大小变化比较大,允许能够检测出不同尺度下的物体: 在低层的feature map,感受野比较小,高层的感受野比较大,在不同的feature map进行卷积,可以达到多尺度的目的。观察YOLO,后面存在两个全连接层,全连接层以后,每一个输出都会观察到整幅图像,并不是很合理。但是SSD去掉了全连接层,每一个输出只会感受到目标周围的信息,包括上下文。这样来做就增加了合理性。并且不同的feature map,预测不同宽高比的图像,这样比YOLO增加了预测更多的比例的box。
Default boxes and aspect ratios
在SSD中引入了Defalut Box,实际上与Faster R-CNN里的anchor box机制非常类似,就是预设一些目标预选框,后续通过softmax分类+bounding box regression获得真实目标的位置。
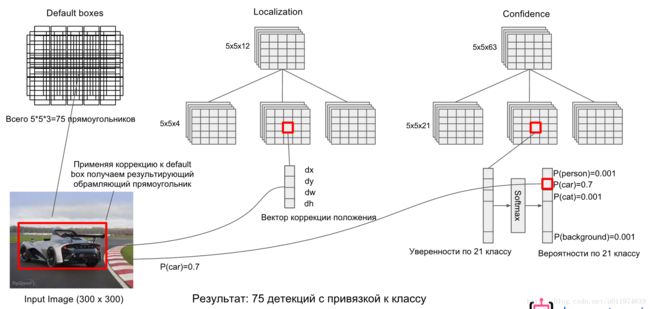
对于不同尺度feature map(上图中38×38×512,38×38×512,19×19×512,19×19×512,10×10×512,10×10×512, 5×5×512,5×5×512, 3×3×512,3×3×512,1×1×2561×1×256)的上的所有特征点上是使用不同的Default boxes,下图是整个预测图的展开图:
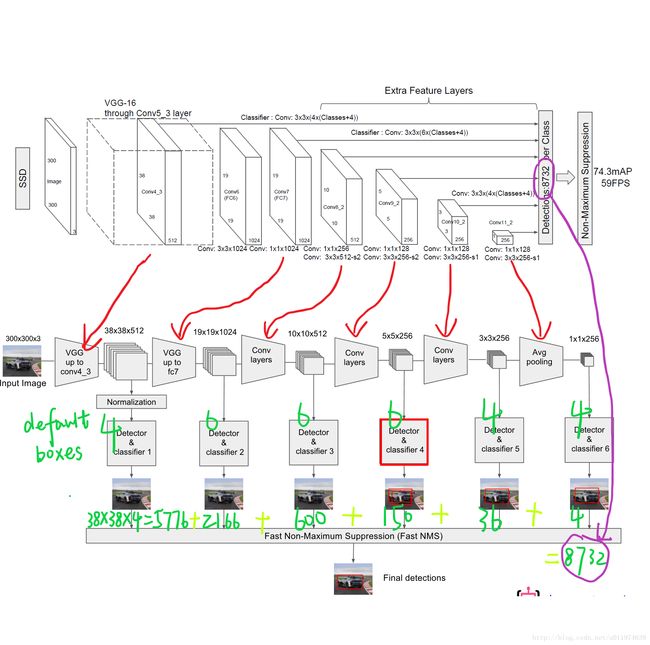
以5×5×2565×5×256为例, 它的Defalut boxes = 6(以3来计算):
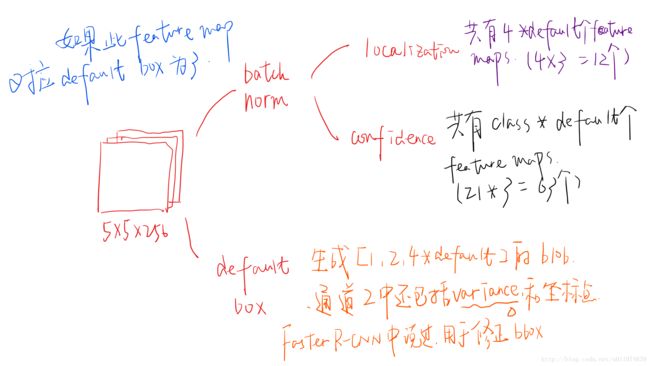
在5×5×2565×5×256的feature map网络pipeline分为了3条线路:
-
经batch norm+卷积,生成了[1, 4*default box, layer_height, layer_width]大小的feature用于bounding box regression(即每个点一组[dxmin,dymin,dxmax,dymax],参考Faster RCNN )
-
经batch norm+卷积,生成了[1, num_class*default box, layer_height, layer_width]大小的feature用于softmax分类目标和非目标(其中num_class是目标类别,SSD 300中num_class = 21)
-
生成了[1, 2, 4*default box]大小的default box blob,其中2个channel分别存储default box的4个点坐标和对应的4个variance
缩进后续通过softmax分类+bounding box regression即可从default box中预测到目标。其实pribox box的与Faster RCNN中的anchor非常类似,都是目标的预设框,没有本质的差异。区别是每个位置的prior box一般是4~6个,少于Faster RCNN默认的9个anchor;同时prior box是设置在不同尺度的feature maps上的,而且大小不同。
还有一个细节就是上面prototxt中的4个variance,这实际上是一种bounding regression中的权重。在图4线路(2)中,网络输出[dxmin,dymin,dxmax,dymax],即对应下面代码中bbox;然后利用如下方法进行针对prior box的位置回归:
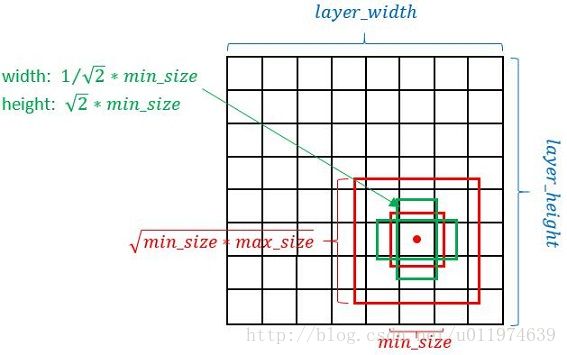
SSD按照如下规则生成Defalut box:
-
以feature map上每个点的中点为中心(offset=0.5),生成一些列同心的Defalut box(然后中心点的坐标会乘以step,相当于从feature map位置映射回原图位置)
-
使用m(SSD300中m=6)个不同大小的feature map 来做预测,最底层的 feature map 的 scale 值为 smin=0.2smin=0.2,最高层的为 smax=0.95smax=0.95,其他层通过下面公式计算得到:
sk=smin+smax−sminm−1(k−1)sk=smin+smax−sminm−1(k−1)
-
使用不同的 ratio值αr∈{1,2,12,3,13}αr∈{1,2,12,3,13},计算 default box 的宽度和高度:wak=skar−−√,hak=sk/ar−−√。wka=skar,hka=sk/ar。另外对于 ratio = 1 的情况,额外再指定 scale 为sk′=sksk+1−−−−−√sk′=sksk+1也就是总共有 6 中不同的 default box
训练策略
监督学习的训练关键是人工标注的label。对于包含default box(在Faster R-CNN中叫做anchor)的网络模型(如: YOLO,Faster R-CNN, MultiBox)关键点就是如何把 标注信息(ground true box,ground true category)映射到(default box上)
训练目标
和常见的 Object Detection模型的目标函数相同,整个目标函数分为两部分:计算相应的default box与目标类别的confidence loss以及相应的回归结果(位置回归)。
L(x,c,l,g)=1N(Lconf(x,c)+αLloc(x,l,g))L(x,c,l,g)=1N(Lconf(x,c)+αLloc(x,l,g))
其中N是match到Ground Truth的default box数量;而αα参数用于调整confidence loss和location loss之间的比例,默认α=1α=1。
-
位置回归则是采用 Smooth L1 loss,目标函数为:
Lloc(x,l,g)=∑i∈PosN∑m∈{cx,cy,w,h}xkijsmoothL1(lmi−g^mj)Lloc(x,l,g)=∑i∈PosN∑m∈{cx,cy,w,h}xijksmoothL1(lim−g^jm)
g^cxj=(gcxj−dcxi)/dwig^cyj=(gcyj−dcyi)/dhig^wj=log(gwjdwi)g^hj=log(ghjdhi)g^jcx=(gjcx−dicx)/diwg^jcy=(gjcy−dicy)/dihg^jw=log(gjwdiw)g^jh=log(gjhdih)
-
confidence loss是典型的softmax loss
Lconf(x,c)=−∑i∈PosNxpijlog(cpi^)−∑i∈Neglog(ci^0)where c^pi=exp(cpi)∑pexp(cpi)Lconf(x,c)=−∑i∈PosNxijplog(cip^)−∑i∈Neglog(ci^0)where c^ip=exp(cip)∑pexp(cip)
训练样本
Matching strategy(正负样本)
在训练时,ground truth 与 default boxes按照如下方式进行配对:
-
首先,寻找与每一个ground truth有最大的IoU的default box,这样就能保证ground truth至少有default box匹配。
-
SSD之后又将剩余还没有配对的default box与任意一个ground truth尝试配对,只要两者之间的IoU大于阈值(SSD 300 阈值为0.5),就认为match。
-
配对到ground truth的default box就是positive,没有配对的default box就是negative。
一个ground truth可能对应多个positive default box,而不再像MultiBox那样只取一个IoU最大的default box。其他的作为负样本(每个default box要么是正样本box要么是负样本box)。
Hard negative mining
一般情况下negative default boxes数量是远大于positive default boxes数量,如果随机选取样本训练会导致网络过于重视负样本,从而loss不稳定。所以需要平衡样本:依据confidience score排序default box,挑选其中confidience高的box进行训练,控制positive:negative=1:3
Data augmentation
为了增强模型的鲁棒性,采取输入可变size和shape,每个训练图片按照以下规则随机处理:
- 是用原图
- 采样一个patch,IoU值为:0.1,0.3,0.5,0.7 or 0.9
- 随机采样一个patch
采样的patch是原始图像大小比例是[0.1,1][0.1,1],aspect ratio在1/2与2之间。当 ground truth的中心在采样的patch中时,保留重叠部分。在这些采样步骤之后,每一个采样的patch被resize到固定的大小,并且以0.5的概率随机的水平翻转(horizontally flipped)。
训练细节
该论文是在ImageNet分类和定位问题上的已经训练好的VGG16模型基础上fine-tuning 得到的。下表是部分训练细节:
| 项目 | description |
|---|---|
| 方法 | SGD |
| batch size | 32 |
| learning rate | 10−310−3 会有调整 |
| momentum | 0.9 |
| weight decay | 0.0005 |
SSD网络结构优劣分析
SSD算法的优点应该很明显:运行速度可以和YOLO媲美,检测精度可以和Faster RCNN媲美。这里谈谈缺点:
-
需要人工设置prior box的min_size,max_size和aspect_ratio值。网络中default box的基础大小和形状不能直接通过学习获得,而是需要手工设置。而网络中每一层feature使用的default box大小和形状恰好都不一样,导致调试过程非常依赖经验。(相比之下,YOLO2使用聚类找出大部分的anchor box形状,这个思想能直接套在SSD上)
-
虽然采用了pyramdial feature hierarchy的思路,但是对小目标的recall依然一般,并没有达到碾压Faster RCNN的级别。可能是因为SSD使用conv4_3低级feature去检测小目标,而低级特征卷积层数少,存在特征提取不充分的问题。
参考资料
CNN目标检测与分割(三):SSD详解