python 简单快速爬取豆瓣电影热播名单
网址:https://movie.douban.com/
爬取豆瓣电影热播名单,包括题目(litile)、时间(time)、国家(country)、导演(director)、作者(actors)、评分(score)。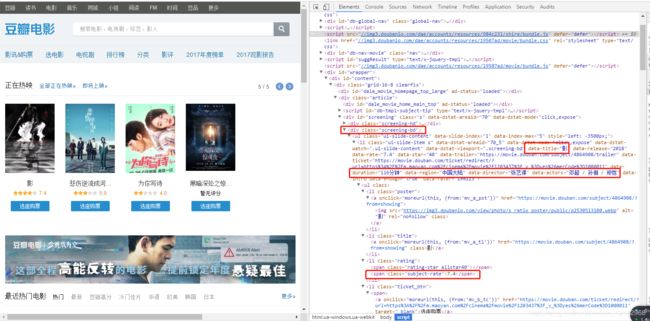 爬取下来的内容如下所示:
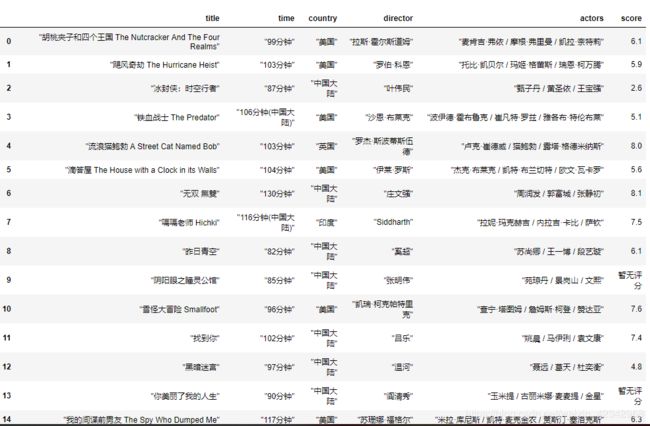
爬取下来的内容如下所示:
import requests
from bs4 import BeautifulSoup
import re
import pandas as pd
import urllib.request
import pandas as pdurl = "https://movie.douban.com/" #原始网址
r = urllib.request.Request(url)
response = urllib.request.urlopen(r)
data= response.read() #返回的网页内容
data= data.decode('utf-8')
soup = BeautifulSoup(data,"html.parser")
data1=soup.find_all(name = "div",attrs = {"class":"screening-bd"})
data1=str(data1) #转化为文本形式建立一个新的文档,利于保存数据
f1=pd.DataFrame()title=[]
a= re.findall(r'data-title=".*?"',data1)
len(title)
for i in a:
temp=re.sub(r"data-title=","",i)
title.append(temp)
f1['title']=title
也可以简单的方法:
a= re.findall(r'data-title=".*?"',data1)
f1['title']=a
'''
"胡桃夹子和四个王国 The Nutcracker And The Four Realms"
"飓风奇劫 The Hurricane Heist"
"冰封侠:时空行者"
"铁血战士 The Predator"
"流浪猫鲍勃 A Street Cat Named Bob"
"滴答屋 The House with a Clock in its Walls"
"无双 無雙"
"嗝嗝老师 Hichki"
"昨日青空"
"阴阳眼之瞳灵公馆"
"雪怪大冒险 Smallfoot"
"找到你"
"黑暗迷宫"
"你美丽了我的人生"
"我的间谍前男友 The Spy Who Dumped Me"
"阿拉姜色"
"八仙"
"追鹰日记 Brothers of the Wind"
"暮光·巴黎 Lumière Amoureuse"
"功夫联盟"
"影"
"悲伤逆流成河"
"为你写诗"
"黑暗深处之惊魂夜"
'''time=[]
a= re.findall(r'data-duration=".*?"',data)
for i in a:
temp=re.sub(r"data-duration=","",i)
time.append(temp)
f1['time']=time
'''
"99分钟"
"103分钟"
"87分钟"
"106分钟(中国大陆)"
"103分钟"
"104分钟"
"130分钟"
"116分钟(中国大陆)"
"82分钟"
"85分钟"
"96分钟"
"102分钟"
"97分钟"
"90分钟"
"117分钟"
"109分钟"
"87分钟"
"97分钟"
"91分钟"
"102分钟"
"116分钟"
"104分钟"
"105分钟"
"90分钟"
'''
country=[]
a= re.findall(r'data-region=".*?"',data)
for i in a:
temp=re.sub(r"data-region=","",i)
country.append(temp)
f1['country']=country
'''
"美国"
"美国"
"中国大陆"
"美国"
"英国"
"美国"
"中国大陆"
"印度"
"中国大陆"
"中国大陆"
"美国"
"中国大陆"
"中国大陆"
"中国大陆"
"美国"
"中国大陆"
"中国大陆"
"奥地利"
"法国"
"中国大陆"
"中国大陆"
"中国大陆"
"中国大陆"
"中国大陆"
'''director=[]
a= re.findall(r'data-director=".*?"',data)
for i in a:
temp=re.sub(r"data-director=","",i)
director.append(temp)
f1['director']=director
'''
"拉斯·霍尔斯道姆"
"罗伯·科恩"
"叶伟民"
"沙恩·布莱克"
"罗杰·斯波蒂斯伍德"
"伊莱·罗斯"
"庄文强"
"Siddharth"
"奚超"
"张明伟"
"凯瑞·柯克帕特里克"
"吕乐"
"温河"
"阎清秀"
"苏珊娜·福格尔"
"松太加"
"曹博"
"杰拉多·奥利瓦雷斯"
"万沥方"
"刘镇伟"
"张艺谋"
"落落"
"吴克群"
"玉素"
'''actors=[]
a= re.findall(r'data-actors=".*?"',data)
for i in a:
temp=re.sub(r"data-actors=","",i)
print(temp)
actors.append(temp)
f1['actors']=actors
'''
"麦肯吉·弗依 / 摩根·弗里曼 / 凯拉·奈特莉"
"托比·凯贝尔 / 玛姬·格蕾斯 / 瑞恩·柯万腾"
"甄子丹 / 黄圣依 / 王宝强"
"波伊德·霍布鲁克 / 崔凡特·罗兹 / 雅各布·特伦布莱"
"卢克·崔德威 / 猫鲍勃 / 露塔·格德米纳斯"
"杰克·布莱克 / 凯特·布兰切特 / 欧文·瓦卡罗"
"周润发 / 郭富城 / 张静初"
"拉妮·玛克赫吉 / 内拉吉·卡比 / 萨钦"
"苏尚卿 / 王一博 / 段艺璇"
"苑琼丹 / 景岗山 / 文熙"
"查宁·塔图姆 / 詹姆斯·柯登 / 赞达亚"
"姚晨 / 马伊琍 / 袁文康"
"聂远 / 葛天 / 杜奕衡"
"玉米提 / 古丽米娜·麦麦提 / 金星"
"米拉·库尼斯 / 凯特·麦克金农 / 贾斯汀·塞洛克斯"
"容中尔甲 / 尼玛颂宋 / 赛却加"
""
"让·雷诺 / 曼纽尔·卡马科 / 托比亚斯·莫雷蒂"
"塞缪尔·默瑟 / 西里尔·迪雷尔 / 苏珊娜·罗尔特-巴利特"
"赵文卓 / 安志杰 / 陈国坤"
"邓超 / 孙俪 / 郑恺"
"赵英博 / 任敏 / 辛云来"
"吴克群 / 周依然 / 周键铭"
"林潇 / 葛凌芮 / 李劲峰"
'''注意的是,到获取评分的时候,是两种不一样的类。所以采取

![]()
score=[]
for i in soup.find_all(name = "li",attrs = {"class":"rating"}):
temp = i.get_text().strip()
print(temp)
score.append(temp)
f1['score']=score
'''
6.1
5.9
2.6
5.1
8.0
5.6
8.1
7.5
6.1
暂无评分
7.6
7.4
4.8
暂无评分
6.3
7.6
暂无评分
7.3
暂无评分
3.6
7.4
5.9
4.0
暂无评分
'''最后打印f1,可得到结果。再保存excel文档。