解读(DivideMix)DIVIDEMIX: LEARNING WITH NOISY LABELS AS SEMI-SUPERVISED LEARNING
论文链接:https://openreview.net/pdf?id=HJgExaVtwr
官方开源代码(pytorch):https://github.com/LiJunnan1992/DivideMix
这是Salesforce在今年年初出的一篇关于半监督学习的文章被ICLR 2020收录,目前还保持在SOTA状态。
文章主要做了两点工作:
• 提出了一个co-divide方法。
• 利用label co-refinement 和co-guessing 改善之前的谷歌提出的MixMatch方法
1.co-divide方法
大概思路:同时训练两个网络,让每个网络在样本损失分布上去拟合GMM模型,并利用GMM模型,将训练数据分为标签数据和未标签数据,co-divide 使前面分的标签与未标签数据分别在两个相同的模型上训练,让这两个网络彼此互斥,这样能够让网络过滤掉不同类型的错误以及防止确认性偏差。
流程图:
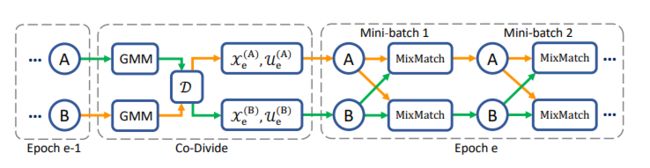
从上图,可以看出,在每个epoch里面,GMM负责将数据分为标签和无标签两种类型。并且分别喂入到两个相同的网络里面,在ssl阶段(半监督)每个模型利用改善的mixmatch去训练数据,对于标签数据还做了一个label co-refinement操作,对于无标签做label co-guessing操作。
在ssl领域里面,主要是对无标签数据做正则化训练,目前主流的做法分为两类:1,一致性正则化;2,最小化熵。目前MixMatch的做法是一致性正则+最小化熵+mixup。
1.使用GMM模型原因。
作者首先论阐了不使用BMM的原因,是因为在label noise 是非对称的时候,BMM会产生让人出乎意料的平滑分布,但是GMM可以很好的区别clean label 和noise label(这里可以理解为标签和无标签数据),因为它对那种锐力的分布是非常灵活的。
算法流程:

简单介绍一下吧。
2,首先使用所有的训练数据,按照普通的训练方法对两个相同的进行一个model预热,相当于进行一个比较好的参数参数化。
4-5,利用2步得到的初始化参数,以及所有训练数据,分别初始化两个GMM模型,然后得到两个不同参数W。
6,分别利用训练去训练两个模型
7-8,利用clean probability threshold τ,以及4-5步骤得到的两个参数,去divide标签和无标签数据。
10-11,分别取7-8中分好的标签以及无标签数据组batch,并且数量是相同的。
13-16,对标签和无标签数据,进行M次的不同增强,
17.对有标签数据进行model输入,并且对输出求平均,因为13-16上做了M次的增强,对比原来相当于产生了M倍的数据(训练一致性)。
18,对17的输出结果做了一个label co-refinement,
19,对18 label 数据的输出做了一个sharpen
20.label co-guessing,利用两个模型同时对无标签数据做预测,并输出,求平均。
21.同样对unlabel数据做一个sharpen
23-24,这两步分别得到了一个label data:ouput和一个unlabel data:output
25,利用23-24得到的两组数据(label,y_output),(unlabel,y'_output),做mixmatch,并得到标签数据和无标签数据的loss
26,求总loss,其中Lreg loss 后面会解释
27,SGD更新参数
分步解析:
(1)Confidence Penalty for Asymmetric Noise(对于非对称噪声的执行度惩罚)
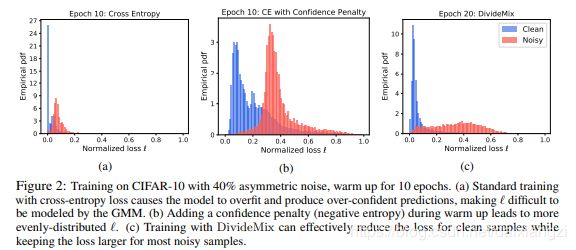
Asymmetric Noise:labels are only replaced by similar classes (e.g. deer→horse, dog↔cat).
Symmetric noise: that is generated by randomly replacing the labels for a percentage of the training data with all possible labels.
上图,纵轴是经验概率分布(Empirical ,Probability Distribution Function),横轴则是标准化的loss大小,图a 是在前10 epoch训练出来的,因为clean 的pdf值很高,则说明对于clean data(标签数据)存在着过拟合,同时loss也很小,说明了此时的个GMM对clean data 和noisy data并不具有良好的distinguish,为了解决该问题,we penalize confident predictions from the network by adding a negative entropy term,也就是在a的基础上,计算交叉熵的时候,添加了一个负号,让部分更平滑,造就了图b的诞生,即:
![]()
图c则是在b的基础上利用divide mix 去训练10epoch得到的,减小了clean loss,让noisy sample的loss 变的更大了。
(2)MIXMATCH WITH LABEL CO-REFINEMENT AND CO-GUESSING
其中的mixmatch我就不过多的做解释啦,不明白的可以去看看这篇论文。
LABEL CO-REFINEMENT:
pb是标签数据的输出。yb则是标签数据的真实label,wb原文中的解释是be clean probability wb produced by the other network,这wb的产生来自于4-5中的高斯模型参数:
![]()
CO-GUESSING:
对应算法步骤20,就是同时利两个模型,对无标签进行预测求均值,这利用了集成学习的思想。
(3)Lreg loss
原因:Under high levels of noise, the network would be encouraged to predict the same class to minimize the loss. To prevent assigning all samples to a single class, we apply the regularization term used by Tanaka et al. (2018) and Arazo et al. (2019), which uses a uniform prior distribution π (i.e. πc = 1/C) to regularize the model’s average output across all samples in the mini-batch
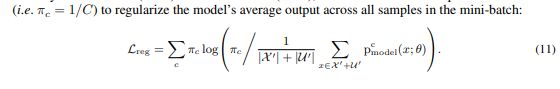
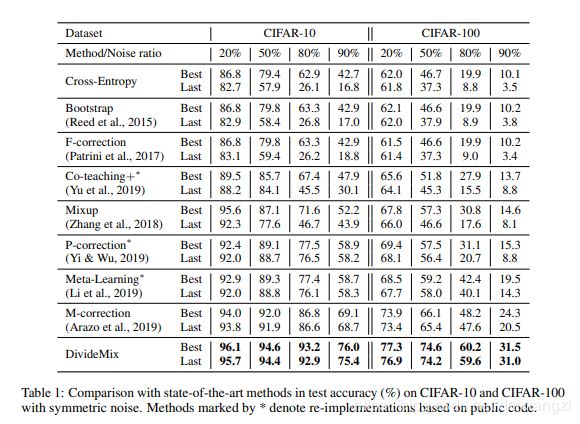
实验结果:
在cifar数据集上的结果
相关消融实验:
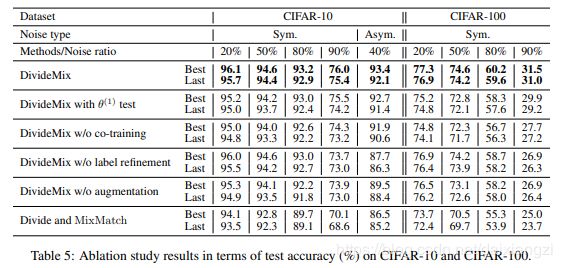
消融实验结论:
