《Mastering OpenCV》--3.Markless AR.无标识式AR (1)
第三章 无标记式增强现实
3.1 基于标记的AR与无标记的AR
| 算法 | 基于标记的AR | 基于无标记的AR |
| 优点 |
|
|
| 缺点 |
|
|
无标记AR利用真实图像和对象来定位摄像机,并在真实图像上进行渲染。其核心是图像识别和目标检测算法。
3.2 用特征描述符来检测视频中的任意图像
使用特征点和特征描述符可以很好地解决模式图像受到透视变换而不能直接与测试图像进行比较的问题。特征提取是指从输入图像中寻找感兴趣区域,例如寻找edges(边缘)corners(角点)或blobs(斑点)。书中第三章关注的是角点。
-
The corner detection is based on an analysis of the edges in the image. A corner-based edge detection algorithm searches for rapid changes in the image gradient. Usually it's done by looking for extremums of the first derivative of the image gradients in the X and Y directions.
-
特征点的主方向通过计算图像某区域内的图像主方向梯度得到。is usually computed as a direction of dominant image gradient in a particular area. When the image is rotated or scaled, the orientation of dominant gradient is recomputed by the feature-detection algorithm. This means that regardless of image rotation, the orientation of feature points will not change. Such features are called rotation invariant(旋转不变性).
-
一些特征检测算法使用固定大小的特征,然而其他算法分别计算每一个关键点的最优化大小。知道了特征点的大小,我们可以在被缩放图像中找到同样的特征点。使得特征尺度不变。 I have to mention a few points about the size feature point. Some of the feature-detection algorithms use fixed-size features, while others calculate the optimal size for each keypoint separately. Knowing the feature size allows us to find the same feature points on scaled images. This makes features scale invariant.
-
opencv特征检测算法
-
通过特征检测所在类的构造函数显式调用 Via an explicit call of the concrete feature detector class constructor:。
cv::Ptr
cv::Ptr
2.通过算法名创建一个特征检测器 Or by creating a feature detector by algorithm name:
cv::Ptr
cv::FeatureDetector::create("SURF");
- 检测特征点,调用detect
std::vector
detector->detect(image, keypoints);
检测到的特征点存储在 keypoints 容器中。每一个关键点包含它的中心,半径,角度和分数,以及一些与特征点相关的”质量”或者”强度”。每一个特征检测算法拥有自己的评分计算算法,因此通过特定的检测算法比较关键点的分数是很有效的。
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------
计算关键点的方向和大小,可以使得关键点具有尺度和旋转的不变性,像SIFT/SURF ORB/FREAK。(#the ORB algorithm does estimate keypoint orientation, but the feature size is still fixed.)
两帧之间逐像素地去比较图像计算花费很大,我们选择相信特征可以描述图像的一个部分,包含了下许多信息。所以为了宣召两帧之间的匹配关系,我们只需要匹配关键点。如何匹配关键点呢?我们在由关键点定义的patch上提取一个向量称之为描述子,作为对特征点的表达。再利用两个特征描述符的相似度距离来衡量。
特征描述子提取算法源于
cv::DescrptorExtrator 基类。同样的,作为特征检测算法他们可以通过指定算法名或者使用显式构造函数的调用来创建。
3.2.2 模式对象定义
为了描述一个模式对象,这里定义一个类叫做pattern。pattern里面包含一张训练图像/特征和描述子列表以及对应的2D和3D的初始pattern位置确定。
/**
* Store the image data and computed descriptors of target pattern
*/
struct Pattern
{
cv::Size size;
cv::Mat data;
std::vector keypoints;
cv::Mat descriptors;
std::vector points2d;
std::vector points3d;
}; 3.2.3 特征点匹配
寻找帧与帧之间对应关系的过程可以看作是寻找一个描述子集中每一个元素在另一个描述子集中的最近邻。
OpenCV中提供了bruteForce 暴力搜索和FLANN两种匹配方法的使用 (FLANN fast library for approximate nearest neighbors )
BF https://baike.baidu.com/item/BF%E7%AE%97%E6%B3%95/4326761
FLANN 算法 in OpenCV
https://blog.csdn.net/cshilin/article/details/52107580& https://blog.csdn.net/App_12062011/article/details/51987352
描述符匹配的结果是一个列表,列表上有两个描述符集合之间的对应关系。描述子的第一个集通常称为训练集,对应pattern图像。第二个集称为查询集,属于我们将要搜索的图像。找到越多的正确匹配(pattern与图像的对应越多),该图像上更有可能存在这个pattern。
为了提高匹配速度,在调用匹配函数之前,你可以训练一个匹配器。训练可以优化cv::FlannBaseMatcher 。为了完成训练,train 类为训练描述子建立索引树,这将提高大数据集的匹配速率(例如,如果你想从数百张图像中什么找到一个匹配的图像)
。对于 cv::BFmatcher,train 函数不做处理,只在内部字段(internal field)简单地存储训练描述子。
下面代码使用模式图像来训练描述符匹配器
void PatternDetector::train(const Pattern& pattern)
{
// Store the pattern object
m_pattern = pattern;
// API of cv::DescriptorMatcher is somewhat tricky
// First we clear old train data:
m_matcher->clear();
// That we add vector of descriptors
// (each descriptors matrix describe one image).
// This allows us to perform search across multiple images:
std::vector descriptors(1);
descriptors[0] = pattern.descriptors.clone();
m_matcher->add(descriptors);
// After adding train data perform actual train:
m_matcher->train();
} 为了匹配在查找的描述子,可使用 cv::DescriptorMatcher类中的一个方法的:
1)找到最佳匹配的简单列表。
void match(const Mat& queryDescriptors,
vector& matches,
=vector()); 2、对于每一个描述子寻找 k 最近的匹配
void knnMatch(const Mat& queryDescriptors,
vector&mathcer,int k,
const vector &masks=vector(),
bool compactResult=false); 3、找到不大于指定的距离的对应距离:
void radiusMatch(const Mat& queryDescrptors,
vecotor>& matches,maxDistance,
const vector& masks=vector(),
bool compactResult=false);
3.2.4 删除外点(离群值
匹配阶段错误的匹配分为两种类型。
1、假阳性:当特征点的对应是错误的。
2、假阴性:当特征点在两个图像上可视时,没有匹配。
假阴性在阈值确定下已经无法解决,删除外点只能是使得假阳性错误最小化。
- 交叉匹配技术。
这种思想是用查询集匹配训练描述子,再用训练的描述子匹配查询集。只有都存在在这两个匹配中的共同匹配才被返回。当有足够的匹配仅带有少量的异常值时,这种方法通常得到最好的结果。
交叉匹配过滤
交叉匹配可以在 cv::BFMatcher 类中访问的到。为了使用交叉检验测试,创建一个cv::BFMatcher 匹配器并且第二个参数设置为 true.
cv::Ptr matcher(new cv::BFMathcher(cv::NORM_HAMMING,true));
- 比率检定。
我们首先执行 KNN-matching,参数K=2,即对于每一个匹配返回2个最临近的描述子。仅当第一个和第二个匹配的距离ratio足够大,才返回这个match。(ratio 阈值通常接近与 2)。
比率检定可以移除几乎所用的异常值。但是在一些情况下,假阳性匹配可以通过这个检定。接下来将展示怎样移除剩下的异常值并且只留下正确的匹配。
- 单应性估计
为了进一步改善我们的匹配,我们使用随机采样一致性来过滤异常值。
当我们对图像进行处理时(一个平面物体)并且假设是刚体的。可以在pattern特征点和查询图像特征点之间找到单应性转换。单应性转换将点集从模式图像转换到查询图像坐标系统。 cv::findHomography 函数可用来寻找单应变换,它使用RANSAC来探测输入点的子集以找到最佳单应性矩阵。缺点是:函数通过计算单应矩阵的重投影误差,把每一个对应标记成内点或外点。

单应性搜索步骤很重要,因为得到的单应性变幻是找到查询图像中pattern位置的关键
- 单应细化
当我们查找单应性转换时,已经有了查找它们3D位置的所有数据。然而,我们可以通过找到更精确的模式角点来进一步改善其位置。具体的,利用估计的单应将输入图像warp来获得已经找到的一个pattern,warp后的pattern应当非常接近于源训练图像。
单应性提纯可以帮助我们找到更精确的单应性转换。

然后,会得到另外一个单应性和另外一组内层围特征。更精确的结果单一性将是 H1 和H2 单应性的矩阵乘积。
如果所有的异常值去除阶段后,匹配的数目仍合理(至少模式图像25%的特征和输入图像对应),可以确保pattern定位准确。
特征检测--综合步骤
为了得到特征检测、描述子提取,匹配算法的实例,需要创建 PatternMatcher 类,该类封装所有的这些数据,包含了特征检测器,描述子提取算法,特征匹配算法和控制检测过程的设置。
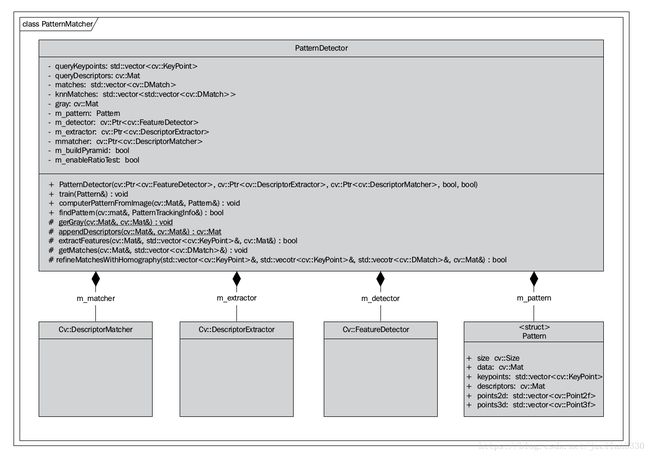
总而言之,我们简短的列一下我们将要执行的步骤:
1、转换输出图到灰度图像
2、使用我们的特征检测算法在查询图像上检测特征
3、从输入的图像中检测到的特征点中抽取描述子
4、与模式描述子进行匹配
5、使用交叉验证或者比率检定移除异常值
6、使用内围层匹配找到单应性变换
7、通过使用上一步骤得到的单应性变换查询图像来提纯单应性。
8、找到精确的单应性作为粗略的增值和提纯的单应性
9、转换模式角点到一副图像的坐标系统,来获得模式在这个图像上的位置。