【计算机视觉之四】深度学习框架介绍
本文简单介绍一下当前比较受欢迎的各种深度学习框架,以及基本的使用方法。
- Caffe
1.1 Caffe的安装教程
1.2 Caffe 的使用方法
1.2.1 Caffe基本设置
1.2.2 Python接口:pycaffe - Tensorflow
2.1 基本概念
四种框架一览: 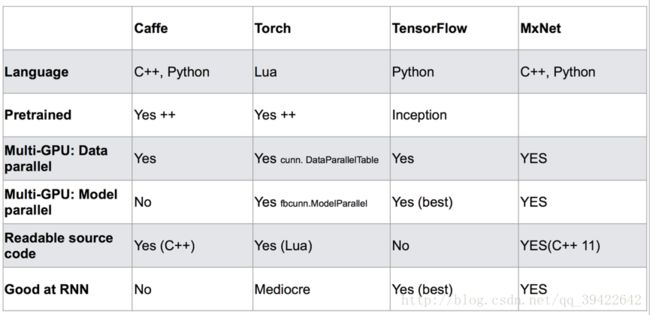
1.Caffe
1.1 Caffe的安装教程
Caffe是目前产品化最多的框架,而且在处理图像问题上非常方便,只要写prototxt就OK了。它是来源于Barkeley的开源框架,提供了python和mathlab的接口,但安装都非常麻烦,主要是因为这个框架是在很多其他的框架上建立起来的,依赖包比较多。
安装教程:
对于Ubuntu 14.04
对于MAC电脑
对于CentOS
1.2 Caffe 的使用方法
1.2.1 Caffe基本设置
这种训练方式不用写代码,主要做好这四步:
第一步:Resize 图像,转换存储格式(LMDB/LevelDB)
第二步:定义网络结构(编辑prototxt)
第三步:定义solver(编辑另一个prototxt)
第四步:开始命令—训练
先来看第一步:转换格式
数据层从LMDB读取对应的图片数据,可以使用convert_imageset来创建。注意测试文件的每一行的格式是这样的:[图片的绝对路径/图片数据][标签]
第二步:定义层次结构

其实就是定义这个结构。
数据层
用lenet看一下,因为它虽然简单,但也基本包含了基本的层次结构。
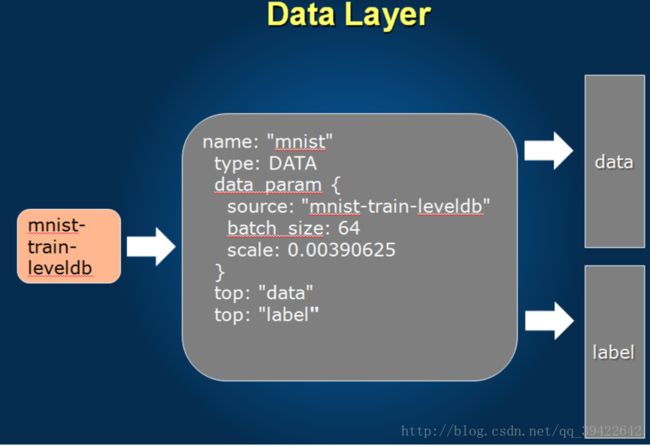
中间灰色的部分就是我们的配置,
name:首先是当前层的名字(这个很重要,如果要用其他已经训练好的模型,记得要改名字)
dataparam:source:数据在哪里,batch_size:一轮多少
top:当前输出的是什么数据
bottom:从哪里读过来的数据
用top/bottom来和其他层串起来
卷积层
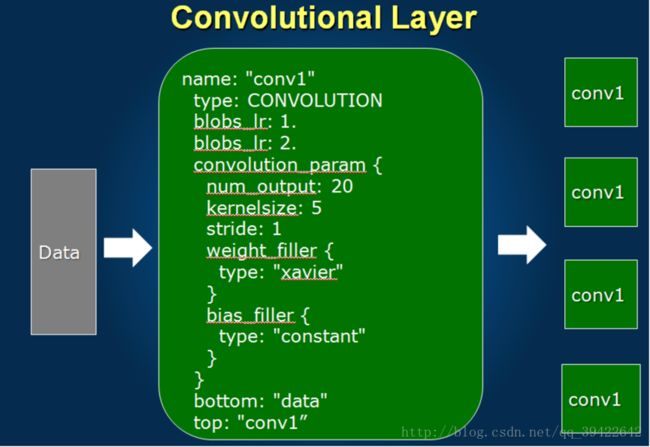
name:定义这一层的名字
bottom:先告诉卷积层你的数据从哪里来
top:这一层的数据输出是什么(conv1)
blobs_lr:1. —对应W的学习率
blobs_lr:2. —对应b的学习率
把w和b分开,可以让模型更加灵活,而且这是局部的学习率。
convolution_param:这才是真正的卷积层的参数
num_output:20—有20个卷积核
kernelsize:5—滑动的窗口为5
stride:1 –步长为1
weight_filler:对w的初始化采用xavier
bias_filler:对偏执值的初始化采用固定的值
下采样层
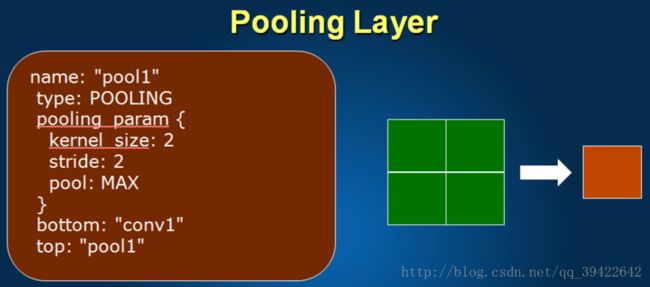
主要看pooling_param的参数
kernel_size:2 —每个窗口有多大
stirde:步长是多少
pool:max –采用最大值的方式采样
全连接层

type:INNER_PRODUCT—表示全连接
inner_product_param:同样也是定义这一层的全连接参数
num_output:输出有多少个
激活层

type:看你用什么函数作为激活
SoftMax + LossLayer
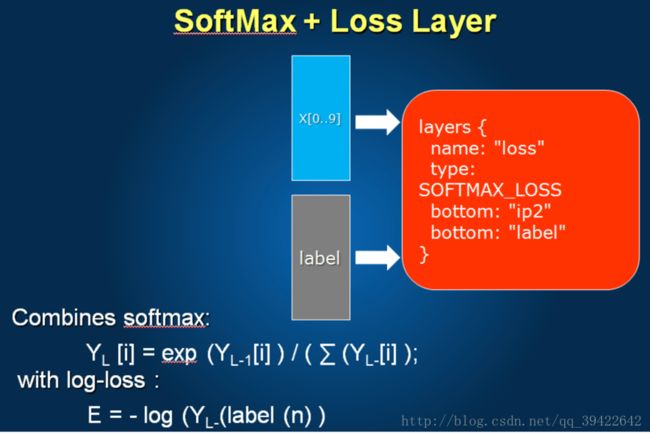
softmax是一个多分类器,同时定义损失函数,以便做反传播。
第三步:定义solver

test_iter/test_interval:1000,表示一个batch为1000张图片
base_lr:全局学习率 (前面的学习率要乘以0.01才能使用)
lr_policy:’step’—用sgd的下山,所以是下山法
display:20—每20轮展示一次
snapshot:10000,每迭代10000轮之后,保存参数(防止服务器断了)
第四步:训练
-gpu 0 —使用第0个gpu
-gpu all —使用这台服务器上的所有gpu
-weights path/to/pretrained_weights.caffemodel:用先前训练好的模型参数
model zoo中有很多训练好的模型你可以使用,比如VGG,AlexNet,GoogleNet,ResNet。
fine_tuning技巧:
每一层都有控制学习率的参数,可以把前面层的学习率调低,最后新加层的调高,同时在solver的时候,可以调低一下solver处的学习率(1/10,1/100),一定要记住储存一下中间结果。
1.2.2 Python接口:pycaffe
使用cpu
caffe.set_mode_cpu()
使用gpu
caffe.set_device(0)
caffe.set_mode_gpu()
详细的还是看官网吧:
2.Tensorflow
2.1 基本概念
这是Google开源的深度学习库,能做的东西特别多,包括什么图像处理,聊天机器人等,比较适合做分布式的处理。
计算模型
A 首先构造好整个计算链路
B 可以对链路进行优化
C 分布式调度
基于层模型
A 每个层的计算,固定实现forward/backward
B 必须手动指定目标GPU卡
tensor:张量,用来表示数据
import numpy as np
import tensorflow as tf
a = np.zeros((2,2))
ta = tf.zeros((2,2))
print(a)输出:
[[ 0. 0.]
[ 0. 0.]]
如果想直接把ta输出不行,必须使用.eval().
print(ta.eval())graph:图,用来表示计算任务
tensorflow一共可以分为两个部分,第一个部分就是构造图,包含计算流图,以及通过session来执行图中的计算。
在构造图的时候,需要创建节点(source op)
从源节点输出传递给其他节点(op)做运算
TF默认图时,节点构造器可以增加节点。
Session:会话,上下文的执行图
前面部分都是准备工作,到这里的时候用run函数,才运行真正的神经网络。
Variable:通过变量维护状态
最后运行的时候一定要记得初始化变量
feed/fetch:可以任意的操作赋值或者从其中获取数据
未完