kafka中的ISR、AR又代表什么?ISR伸缩又是什么?
kafka中的ISR、AR又代表什么?ISR伸缩又是什么?
分区中的所有副本统称为AR(Assigned Repllicas)。所有与leader副本保持一定程度同步的副本(包括Leader)组成ISR(In-Sync Replicas),ISR集合是AR集合中的一个子集。消息会先发送到leader副本,然后follower副本才能从leader副本中拉取消息进行同步,同步期间内follower副本相对于leader副本而言会有一定程度的滞后。前面所说的“一定程度”是指可以忍受的滞后范围,这个范围可以通过参数进行配置。与leader副本同步滞后过多的副本(不包括leader)副本,组成OSR(Out-Sync Relipcas),由此可见:AR=ISR+OSR。在正常情况下,所有的follower副本都应该与leader副本保持一定程度的同步,即AR=ISR,OSR集合为空。
Leader副本负责维护和跟踪ISR集合中所有的follower副本的滞后状态,当follower副本落后太多或者失效时,leader副本会吧它从ISR集合中剔除。如果OSR集合中follower副本“追上”了Leader副本,之后再ISR集合中的副本才有资格被选举为leader,而在OSR集合中的副本则没有机会(这个原则可以通过修改对应的参数配置来改变)
ISR的伸缩:
Kafka在启动的时候会开启两个与ISR相关的定时任务,名称分别为“isr-expiration"和”isr-change-propagation".。isr-expiration任务会周期性的检测每个分区是否需要缩减其ISR集合。这个周期和“replica.lag.time.max.ms”参数有关。大小是这个参数一半。默认值为5000ms,当检测到ISR中有是失效的副本的时候,就会缩减ISR集合。如果某个分区的ISR集合发生变更, 则会将变更后的数据记录到ZooKerper对应/brokers/topics//partition//state节点中。节点中数据示例如下:
{“controller_cpoch":26,“leader”:0,“version”:1,“leader_epoch”:2,“isr”:{0,1}}
其中controller_epoch表示的是当前的kafka控制器epoch.leader表示当前分区的leader副本所在的broker的id编号,version表示版本号,(当前半本固定位1),leader_epoch表示当前分区的leader纪元,isr表示变更后的isr列表。
除此之外,当ISR集合发生变更的时候还会将变更后的记录缓存到isrChangeSet中,isr-change-propagation任务会周期性(固定值为2500ms)地检查isrChangeSet,如果发现isrChangeSet中有ISR 集合的变更记录,那么它会在Zookeeper的/isr_change_notification的路径下创建一个以isr_change开头的持久顺序节点(比如/isr_change_notification/isr_change_0000000000), 并将isrChangeSet中的信息保存到这个节点中。kafka控制器为/isr_change_notification添加了一个Watcher,当这个节点中有子节点发生变化的时候会触发Watcher动作,以此通知控制器更新相关的元数据信息并向它管理的broker节点发送更新元数据信息的请求。最后删除/isr_change_notification的路径下已经处理过的节点。频繁的触发Watcher会影响kafka控制器,zookeeper甚至其他的broker性能。为了避免这种情况,kafka添加了指定的条件,当检测到分区ISR集合发生变化的时候,还需要检查一下两个条件:
(1).上一次ISR集合发生变化距离现在已经超过5秒,
(2).上一次写入zookeeper的时候距离现在已经超过60秒。
满足以上两个条件之一者可以将ISR写入集合的变化的目标节点。
有缩减就会有补充,那么kafka何时扩充ISR的?
随着follower副本不断进行消息同步,follower副本LEO也会逐渐后移,并且最终赶上leader副本,此时follower副本就有资格进入ISR集合,追赶上leader副本的判定准侧是此副本的LEO是否小于leader副本HW,这里并不是和leader副本LEO相比。ISR扩充之后同样会更新ZooKeeper中的/broker/topics//partition//state节点和isrChangeSet,之后的步骤就和ISR收缩的时的相同。
当ISR集合发生增减时,或者ISR集合中任一副本LEO发生变化时,都会影响整个分区的HW。
如下图所示,leader副本的LEO为9,follower副本的LEO为7,而follower2副本的LEO为6,如果判定这三个副本都处于ISR集合中,那么分区的HW为6,如果follower3已经判定失效副本被剥离出ISR集合,那么此时分区HW为leader副本和follower副本中LEO的最小值,即为7.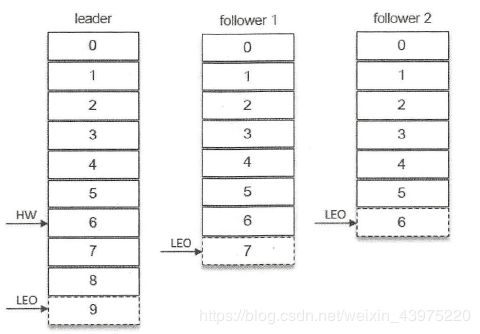
LW是Low Watermark的缩写,俗称“低水位”,代表AR集合中最小的logStartOffset值,副本的拉取请求(FetchRequest,它有可能触发新建日志分段而旧的的被清理,进而导致logStartoffset的增加)和删除请求(DeleteRecordRequest)都可能促使LW的增长。
kafka中的HW、LEO、LSO、LW等分别代表什么?
ISR与HW和LEO也有紧密的关系,HW是High Watermak的缩写, 俗称高水位,它表示了一个特定消息的偏移量(offset),消费之只能拉取到这个offset之前的消息。
如下,它代表一个日志文件,这个日志文件中有9条消息,第一消息的offset(LogStartOffset)为0,最后的一条消息offset为8,offset为9的消息用虚线框表示,代表下的一个待写入的消息。日志文件的HW为6.表示消费者只能拉取到offset0至5之间的消息,而offset为6的消息对消费者而言是不可见的。
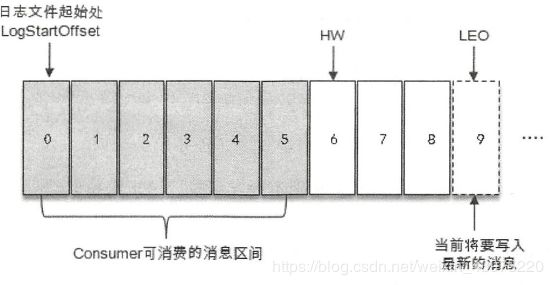
LEO是Log End Offset的缩写,它表示了当前日志文件中下一条待写入消息的offset,如上图offset为9的位置即为当前日志文件LEO,LEO的大小相当于当前日志分区中最后一条消息的offset值加1。分区ISR集合中的每个副本都会维护自身的LEO,而ISR集合中最小的LEO即为分区的HW,对消费这而言只能消费HW之前的消息。
如下图,假设某个分区的ISR集合中有三个副本,即一个leader副本和两个follower副本,此时分区的LEO和HW都为3。消息3和消息4从生产者发出之后会被先存入leader副本。
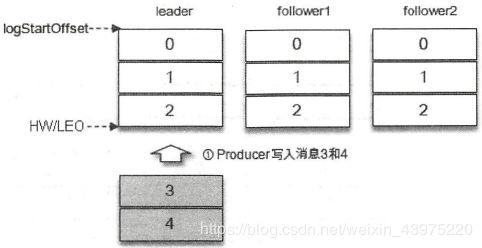
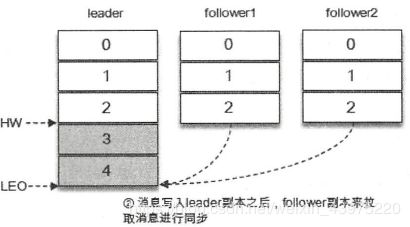
在消息写入leader副本之后,follower副本会发送拉取请求来拉取消息3和消息4以进行消息同步。
在同步过程中,不同的follower副本的同步效率也不尽相同。如下图,在某一时刻follower1完全跟上了leader副本而follower2只同步了消息3,如此leader副本的LEO为5,follower1的LEO为5,Follower2的LEO为4。那么当前分区的HW最小值4,此时消费者可以消费到offset为0-3之间的消息。
写入消息如下图,所有的副本都成功写入了消息3和消息4,整个分区的HW和LEO为5,因此消费者可以消费offset为4的消息了。
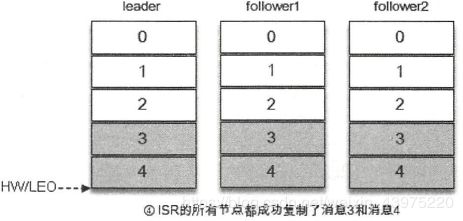
由此可见,kafka的复制机制不是完全的同步复制,也不是单纯的异步复制,事实上,同步复制要求所有能工作的Follower副本都复制完,这条消息才会被确认为成功提交,这种复制方式影响了性能。而在异步复制的情况下, follower副本异步地从leader副本中复制数据,数据只要被leader副本写入就被认为已经成功提交。在这种情况下,如果follower副本都没有复制完而落后于leader副本,如果突然leader副本宕机,则会造成数据丢失。Kafka使用这种ISR的方式有效的权衡了数据可靠性与性能之间的关系。
什么是LSO?
LSO特指LastStableOffset。它具体与kafka的事物有关。
-
消费端参数——isolation.level,这个参数用来配置消费者事务的隔离级别。字符串类型,“read_uncommitted”和“read_committed”,表示消费者所消费到的位置,如果设置为“read_committed",那么消费这就会忽略事务未提交的消息,既只能消费到LSO(LastStableOffset)的位置,默认情况下,”read_uncommitted",既可以消费到HW(High Watermak)的位置。
注:follower副本的事务隔离级别也为“read_uncommitted",并且不可修改。
在开启kafka事务的同时,生产者发送了若干消息,(msg1,msg2,)到broker中,如果生产者没有提交事务(执行CommitTransaction),那么对于isolation.level=read_committed的消费者而言是看不多这些消息的,而isolation.level=read_uncommitted则可以看到。事务中的第一条消息的位置可以标记为firstUnstableOffset(也就是msg1的位置)。
这个LSO还会影响到kafka消费之后的量,(也就是kafka,Log,很多时候也称之为kafka堆积量)的计算 。如下图。
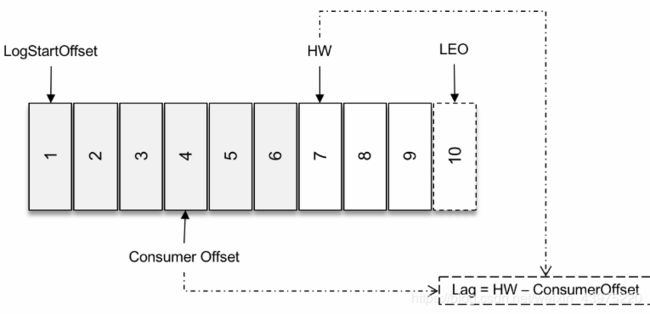
在图中,对每一个分区而言,它Lag等于HW-ConsumerOffset的值,其中ComsmerOffset表示当前的消费的位移,当然这只是针对普通的情况。如果为消息引入了事务,那么Lag的计算方式就会有所不同。
如果当消费者客户端的isolation.level的参数配置为“read_uncommitted"(默认),那么Lag的计算方式不受影响,如果这个参数配置为“read_committed",那么就要引入LSO来进行计算了。
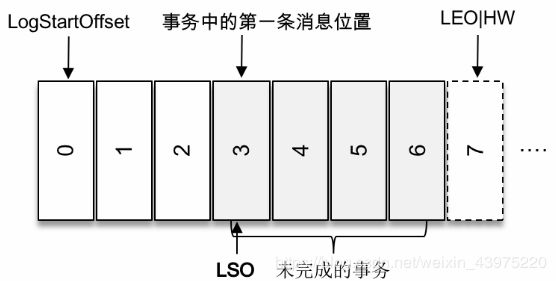
对于未完成的事务而言,LSO的值等于事务中的第一条消息所在的位置,(firstUnstableOffset)
对于已经完成的事务而言,它的值等同于HW相同,所以我们可以得出一个结论:LSO≤HW≤LEO
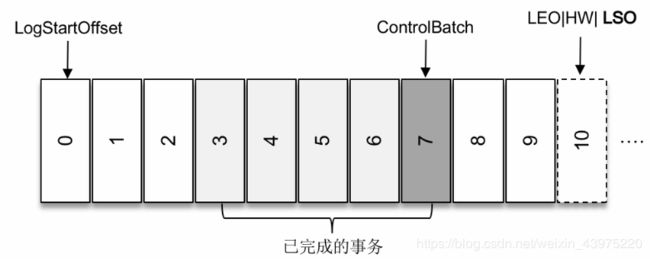
所以,对于分区中未完成的事务,并且消费者客户端的isolation.level参数配置为”read_committed
"的情况,它对应的Lag等于LSO-ComsumerOffset的值。