相机字符叠加原理2
相机字符叠加原理
一、点阵字库
GB2312又称国标码,由国家标准总局发布,1981年5月1日实施,通行于大陆。新加坡等地也使用此编码。它是一个简化字的编码规范,当然也包括其他的符号、字母、日文假名等,共7445个图形字符,其中汉字占6763个。我们平时说6768个汉字,实际上里边有5个编码为空白,所以总共有6763个汉字。
GB2312规定“对任意一个图形字符都采用两个字节表示,每个字节均采用七位编码表示”,习惯上称第一个字节为“高字节”,第二个字节为“低字节”。GB2312中汉字的编码范围为,第一字节0xB0-0xF7(对应十进制为176-247),第二个字节0xA0-0xFE(对应十进制为160-254)。
GB2312将代码表分为94个区,对应第一字节(0xa1-0xfe);每个区94个位(0xa1-0xfe),对应第二字节,两个字节的值分别为区号值和位号值加32(2OH),因此也称为区位码。01-09区为符号、数字区,16-87区为汉字区(0xb0-0xf7),10-15区、88-94区是有待进一步标准化的空白区。
二、中英文字的区分
汉字占两个字节,英文和阿拉伯数字等占一个字节。例如,需要叠加字符串char *szTime="当前2015",则其内存为:
szTime0x0f5dc50c "当前时间:2015-03"
[0x00000000] 0xb5 '?' char 当
[0x00000001] 0xb1 '?' char
[0x00000002] 0xc7 '?' char 前
[0x00000003] 0xb0 '?' char
[0x00000009] 0x32 '2' char 2
[0x0000000a] 0x30 '0' char 0
[0x0000000b] 0x31 '1' char 1
[0x0000000c] 0x35 '5' char 5
我们可以看出汉字的“当”字由两个字节组成:0xb5=0B1011 01010xb1=0B1011 0001
判断汉字的规则为:第一个字节&0x80 成立 否则则为英文
三、字与字库之间的关系


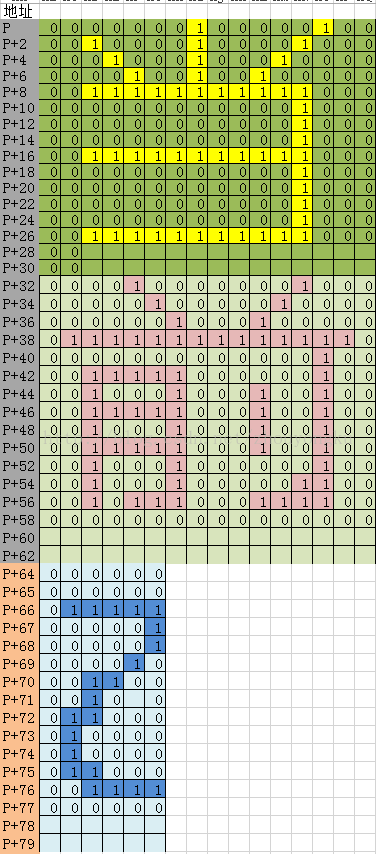
四、点阵与YUV图像
typedef struct YUV_IMAGE
{
YUV_IMAGE(){ y = NULL; u = NULL; v = NULL; w = 0; h = 0; }
~YUV_IMAGE(){ y = NULL; u = NULL; v = NULL; w = 0; h = 0; }
UCHAR *y;
UCHAR *u;
UCHAR *v;
UINT w;
UINT h;
IMAGE_TYPE t;
};
//pLib--点阵字库
//szHZ[2] --汉字
//pImage 图像
// col --叠加的颜色
void OSD(TUchar *pLib, char szHZ[2], YUV_IMAGE *pImage, COLORREF col, UINT nFontW)
{
TUchar szDZ[1000] = { 0 };
UINT h = nFontW, w = nFontW / 8;
UINT wImg = pImage->w;
//计算点阵字节量
UINT nLen = nFontW*nFontW / 8;
//计算点阵在字库中的偏移量
UINT nOff = (94 * szHZ[0] + szHZ[1])*nLen;
memcpy(szDZ, pLib + nOff, nLen);
//垂直遍历
for (int i = 0; i < h; i++)
{
//水平遍历
for (int j = 0; j < w; j++)
{
//按字节中的位遍历
for (int k = 0; k < 8; i++)
{
TUchar szByte = szDZ[i*w + j];
//如果这一位是需要显示出来的
if ((szByte >> k) & 0x01)
{
//叠加Y
TUchar y, u, v;
RGB2YUV(col.r, col.g, col.b, &y, &u, &v);
pImage->y[wImg*h + j*nFontW + k] = y;
//针对YUV420UV分开存储的图像格式 下面需要稍微修改一下 因为UV是垂直1/2采样
if (i% 2)
{
pImage->y[wImg*h + j*nFontW + k] = u;
pImage->y[wImg*h + j*nFontW + k] = v;
}
}
}
}
}
}