JDK1.8 源码 java.util.LinkedHashMap
前言
在前面的章节内我们仔细阅读了java.util.HashMap的源码. 在后面的2章内, 我们将看下JDK1.8内其余的2种数据类型的源码, 即LinkedHashMap与TreeMap.
在看LinkedhashMap之前, 我们先回顾下HashMap的几个基本知识.
- 基本数据节点
Node
static class Node implements Map.Entry {
final int hash;
final K key;
V value;
Node next;
}
- 数据存储地址
Node
transient Node[] table;
- 查找数据
- 先通过Hash值判定数组地址.
- 再依次搜寻. (
单个节点&链表&红黑树)
- 插入数据
- 先查找数据. 看是否已经存在, 已经存在就覆盖.
- 不存在就插入. (注意链表向红黑树的转换 与 扩容操作.)
- 删除数据
- 先查找数据.
- 存在即删除数据. (同时也需要注意 红黑树与链表转换)
- Hash值与数组长度
- 数组长度需要是
2^N. - Hash值计算为
hash & (length-1). 注意之前的hash值还有一个异或的随机操作.
- 数组长度需要是
LinkedHashMap
复习完了HashMap的基本知识后, 我们可以查看下今天的重点LinkedHashMap.
与之前一样. 我们仍然从基本数据类型与基本方法进行查看
- 基本数据类型
-
transient LinkedHashMap.Entry -
transient LinkedHashMap.Entry -
final boolean accessOrder; `true 当前顺序 / false插入顺序`
-
- 基本方法
- 初始化- 构造函数
- 查询
- 增
- 改
- 删
- 遍历
类声明-继承关系 & 构造函数
- 类声明
public class LinkedHashMap
extends HashMap
implements Map
{
由上可知. LinkedHashMap继承自HashMap. 且对其进行一部分方法的重写.
- HashMap 内节点数据类型
Node
static class Node implements Map.Entry {
final int hash;
final K key;
V value;
Node next;
}
- LinkedHashMap 内节点
Entry
static class Entry extends HashMap.Node {
Entry before, after;
Entry(int hash, K key, V value, Node next) {
super(hash, key, value, next);
}
}
继承自HashMap.Node. 其内多维护了一个前后的指针.
构造函数
- LinkedHashMap()
public LinkedHashMap() {
super();
accessOrder = false;
}
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
截取其中具有代表性的3个构造函数. 其中除了加上accessOrder=false之外, 使用的是HashMap的构造函数. 具体细节看HashMap的相关部分即可.
- 查询
get(Object key)
public V get(Object key) {
Node e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
可以看到getNode()方法使用的是HashMap内的方法.
关键点在于其如果accessOrder为true之后. 会触发afterNodeAccess()方法. 方法内容如下所示:
void afterNodeAccess(Node e) { // move node to last
LinkedHashMap.Entry last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry p =
(LinkedHashMap.Entry)e, b = p.before, a = p.after;
p.after = null;
// 删除节点
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
// 将节点插入到末尾.
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
可以看到. 以上是对于链表的操作. 步骤主要分为如下2步骤:
- 获取当前节点的头
before和尾after. 删除当前节点. 即before.after=after/after.before = before/ - 将当前节点插入队尾.
last.after = p/p.before=last; p.after=null
值得注意的是, 此次使用的是模版方法设计模式. 其方法在于HashMap内的实现为空方法实现.
void afterNodeAccess(Node p) { }
- 新增
put(K key, V value)
值得注意的是LinkedHashMap内并未实现put方法. 而且使用的HashMap的put方法. 我们回顾下其实现.
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node[] tab; Node p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
值得注意的是, 与get方法一样. LinkedHashMap在其内也对于部分方法进行了重写.

经过比对可以发现. 与put方法相关的重写方法有.
- newNode - 新增节点
- newTreeNode - 新增红黑树节点
- afterNodeAccess - 节点访问后
- afterNodeInsertion - 节点插入后
其中afterNodeAccess方法在前一小节已经说过. 这边不再缀述. 我们看下其余3个被重写方法.
- HashMap 内原实现
// Create a regular (non-tree) node
Node newNode(int hash, K key, V value, Node next) {
return new Node<>(hash, key, value, next);
}
// Create a tree bin node
TreeNode newTreeNode(int hash, K key, V value, Node next) {
return new TreeNode<>(hash, key, value, next);
}
void afterNodeInsertion(boolean evict) { }
- LinkedHashMap内重写实现
Node newNode(int hash, K key, V value, Node e) {
LinkedHashMap.Entry p =
new LinkedHashMap.Entry(hash, key, value, e);
linkNodeLast(p);
return p;
}
TreeNode newTreeNode(int hash, K key, V value, Node next) {
TreeNode p = new TreeNode(hash, key, value, next);
linkNodeLast(p);
return p;
}
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
可以看到. 主要的方法为linkNodeLast(p)与afterNodeInsertion(). 我们来看下其具体实现.
linkNodeLast(p)
// link at the end of list
private void linkNodeLast(LinkedHashMap.Entry p) {
LinkedHashMap.Entry last = tail;
tail = p;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
}
将新节点放到LinkedHashMap维护的尾节点末尾last.after=p/p.before=last / last=p. 就是在链表末尾新增一个节点的操作. 没有什么其他奥妙.
afterNodeInsertion()
值得注意的是, 其中有2个相关方法.removeNode是HashMap内的.removeEldestEntry内容如下所示:
protected boolean removeEldestEntry(Map.Entry eldest) {
return false;
}
也就是说LinkedHashMap内是不会删除过期节点的. 有可能其他方法再次继承重写后会进行改变. 个人猜测?定长消息队列?
删除节点``
public boolean remove(Object key, Object value) {
return removeNode(hash(key), key, value, true, true) != null;
}
final Node removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node[] tab; Node p; int n, index;
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node node = null, e; K k; V v;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
if (p instanceof TreeNode)
node = ((TreeNode)p).getTreeNode(hash, key);
else {
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode)
((TreeNode)node).removeTreeNode(this, tab, movable);
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}
LinkedHashMap的remove方法同样是使用的是HashMap的. 通过上述重写可以发现. 其主要重写的方法为afterNodeRemoval(node). 我们同样来看下具体实现.
void afterNodeRemoval(Node e) { // unlink
LinkedHashMap.Entry p =
(LinkedHashMap.Entry)e, b = p.before, a = p.after;
p.before = p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a == null)
tail = b;
else
a.before = b;
}
可以看到. 其删除节点后. 从维护的链表内也删除了该节点. b.after=a / a.before=b.
- 遍历
To be continue.
小结
从上述源码可以知道. LinkedHashMap即重写了HashMap内的部分方法来维持一个链表的目的. 其基本功能与HashMap基本一致, 唯一的区别在于, 其多维护了一个链表.
那么这个链表有什么用呢?
个人认为主要作用为: 保持数据的顺序性. (HashMap是无序的.)
其延伸的其他使用用例与数据结构为:
- 延迟队列.
- HashMap构建的消息队列. 其同时满足队列和HashMap这两者的特性.
-
相关演示图-HashMap
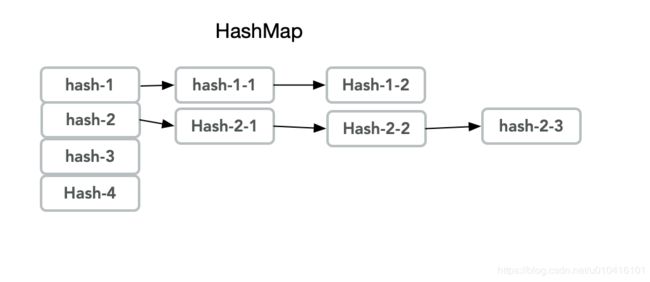
-
- 相关演示图-LinkedHashMap
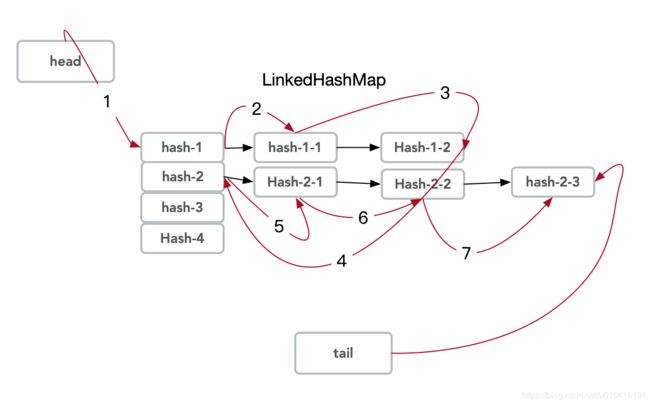
可以看到. 其在原来HashMap的基础上. 维持了自己的一个链表体系. 用于记录插入的顺序 & 遍历的顺序.
- 相关演示图-LinkedHashMap
Reference
[1] .JDK1.8源码(九)——java.util.LinkedHashMap 类