JVM锁实现探究2:synchronized深探
本文来自网易云社区
作者:马进
这里我们来聊聊synchronized,以及wait(),notify()的实现原理。
在深入介绍synchronized原理之前,先介绍两种不同的锁实现。
一、阻塞锁
我们平时说的锁都是通过阻塞线程来实现的:当出现锁竞争时,只有获得锁的线程能够继续执行,竞争失败的线程会由running状态进入blocking状态,并被登记在目标锁相关的一个等待队列中,当前一个线程退出临界区,释放锁后,会将等待队列中的一个阻塞线程唤醒(按FIFO原则唤醒),令其重新参与到锁竞争中。
这里要区别一下公平锁和非公平锁,顾名思义,公平锁就是获得锁的顺序按照先到先得的原则,从实现上说,要求当一个线程竞争某个对象锁时,只要这个锁的等待队列非空,就必须把这个线程阻塞并塞入队尾(插入队尾一般通过一个CAS保持插入过程中没有锁释放)。相对的,非公平锁场景下,每个线程都先要竞争锁,在竞争失败或当前已被加锁的前提下才会被塞入等待队列,在这种实现下,后到的线程有可能无需进入等待队列直接竞争到锁。
非公平锁虽然可能导致活锁(所谓的饥饿),但是锁的吞吐率是公平锁的5-10倍,synchronized是一个典型的非公平锁,无法通过配置或其他手段将synchronized变为公平锁,在JDK1.5后,提供了一个ReentrantLock可以代替synchronized实现阻塞锁,并且可以选择公平还是非公平。
二、自旋锁
线程的阻塞和唤醒需要CPU从用户态转为核心态,频繁的阻塞和唤醒对CPU来说是一件负担很重的工作。同时我们可以发现,很多对象锁的锁定状态只会持续很短的一段时间,例如整数的自加操作,在很短的时间内阻塞并唤醒线程显然不值得,为此引入了自旋锁。
所谓“自旋”,就是让线程去执行一个无意义的循环,循环结束后再去重新竞争锁,如果竞争不到继续循环,循环过程中线程会一直处于running状态,但是基于JVM的线程调度,会出让时间片,所以其他线程依旧有申请锁和释放锁的机会。
自旋锁省去了阻塞锁的时间空间(队列的维护等)开销,但是长时间自旋就变成了“忙式等待”,忙式等待显然还不如阻塞锁。所以自旋的次数一般控制在一个范围内,例如10,100等,在超出这个范围后,自旋锁会升级为阻塞锁。
所谓自适应自旋锁,是通过JVM在运行时收集的统计信息,动态调整自旋锁的自旋上界,使锁的整体代价达到最优。
介绍了自旋锁和阻塞锁这两种基本的锁实现之后,我们来聊一聊synchronized背后的锁实现。
synchronized锁在运行过程中可能经过N次升级变化,首先可以想到的是:
自适应自旋锁—>阻塞锁
自适应自旋锁是JDK1.6中引入的,自旋锁的自旋上界由同一个锁上的自旋时间统计和锁的持有者状态共同决定。当自旋超过上界后,自旋锁就升级为阻塞锁。就像C中的Mutex,阻塞锁的空间和时间开销都比较大(毕竟有个队列),为此在阻塞锁中,synchronized又进一步进行了优化细分。阻塞锁升级变化过程如下:
偏向锁—>轻量锁—>重量锁
重量锁就是带着队列的锁,开销最大,它的实现和Mutex很像,但是多了一个waiting的队列,这部分实现最后介绍,我们先来看看轻量锁和偏向锁是什么玩意。
在进一步介绍锁实现之前,我们需要先了解一下JVM中对象的内存布局,JVM中每个对象都有一个对象头(Object header),普通对象头的长度为两个字,数组对象头的长度为三个字(JVM内存字长等于虚拟机位数,32位虚拟机即32位一字,64位亦然),其构成如下所示:
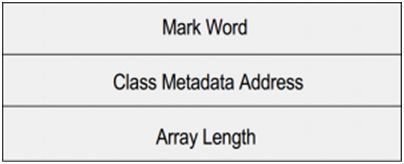
图1. JAVA对象头结构
ClassAddress是指向方法区中对象所属类对象的地址指针,ArrayLength标志了数组长度, MarkWord用于存储对象的各种标志信息,为了在极小的空间存储尽量多的信息,MarkWord会根据对象状态复用空间。MarkWord中有2位用于标志对象状态,在不同状态下MarkWord中存储的信息含义分别为:
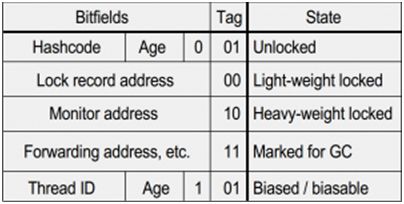
图2. MarkValue结构
看到这个表格多少会让人有些眼花缭乱,不急,我们在讲解下面几种锁的过程中会分别介绍这几种状态。
三、轻量锁(Light-weight lock)
首先需要明确的是,无论是轻量锁还是偏向锁,都不能代替重量锁,两者的本意都是在没有多线程竞争的前提下,减少重量锁产生的性能消耗。一旦出现了多线程竞争锁,轻量锁和偏向锁都会立即升级为重量锁。进一步讲,轻量锁和偏向锁都是重量锁的乐观并发优化。
对对象加轻量锁的条件是该对象当前没有被任何其他线程锁住。
先从对象O没有锁竞争的状态说起,这时候MarkWord中Tag状态为01,其他位分别记录了对象的hashcode,4位的对象年龄信息(新建对象年龄为0,之后每次在新生代拷贝一次就年龄+1,当年龄超过一个阈值之后,就会被丢入老年代,GC原理不是本文的主题,但至少我们现在知道了,这个阈值<=15),以及1位的偏向信息用于记录这个对象是否可用偏向锁。 当一个线程A在对象O上申请锁时,它首先检查对象O的Tag,若发现是01且偏向信息为0,表明当前对象还未加锁,或加过偏向锁(加过,注意是加过偏向锁的对象只能被同样的线程加锁,如果不同的线程想要获取锁,需要先将偏向锁升级为轻量锁,稍后会讲到),在判断对当前对象确实没有被任何其他线程锁住后(Tag为01或偏向线程不具有该对象锁),即可以在该对象上加轻量锁。
在判断可以加轻量锁之后,加轻量锁的过程为两步:
1. 在当前线程的栈(stack frame)中生成一个锁记录(lock record),这个锁记录并不是我们通常意义上说的锁对象(包含队列的那个),而仅仅是对象头MarkValue的一个拷贝,官方称之为displayed mark value。如图3所示:
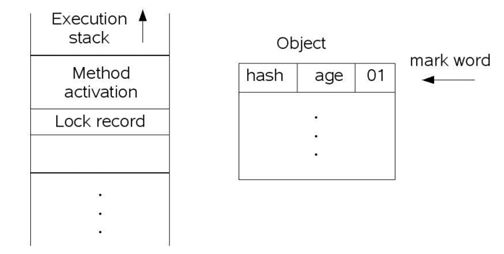
图3. 加轻量锁之前
2. 通过CAS操作将上一步生成的lock record地址赋给目标对象的MarkValue中(Tag同时改为00),保证在给MarkValue赋值时Tag不会动态修改,如果CAS成功,表明轻量锁申请成果,如果CAS不成功,且Tag变为00,则查看MarkValue中lock record address是否指向当前线程栈中的锁记录,若是,则表明是同样的线程锁重入,也算锁申请成果。如图4所示: 在第二步中,若不满足加锁成功的两种情况,说明目标锁已经被其他线程持有,这时不再满足加轻量锁条件,需要将当前对象上的锁状态升级为重量锁:将Tag状态改为10,并生成一个Monitor对象(重量锁对象),再将MarkValue值改为该Monitor对象的地址。最后将当前线程塞入该Monitor的等待队列中。
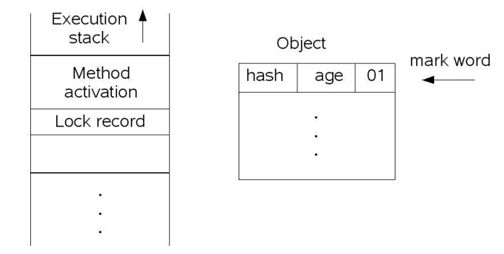
图4.加轻量锁之后
轻量锁的解锁过程也依赖CAS操作: 通过CAS将lock record中的Object原MarkValue赋还给Object的MarkValue,若替换成功,则解锁完成,若替换不成功,表示在当前线程持有锁的这段时间内,其他线程也竞争过锁,并且发生了锁升级为重量锁,这时需要去Monitor的等待队列中唤醒一个线程去重新竞争锁。
当发生锁重入时,会对一个Object在线程栈中生成多个lock record,每当退出一个synchronized代码块便解锁一次,并弹出一个lock record。
一言以蔽之,轻量锁通过CAS检测锁冲突,在没有锁冲突的前提下,避免采用重量锁的一种优化手段。
加轻量锁的代价是数个指令外加一个CAS操作,虽然轻量锁的代价已经足够小,它依然有优化空间。 细心的人应该发现,轻量锁的每次锁重入都要进行一次CAS操作,而这个操作是可以避免的,这便是偏向锁的优化手段了。
偏向锁
所谓偏向,就是偏袒的意思,偏向锁的初衷是在某个线程获得锁之后,消除这个线程锁重入(CAS)的开销,看起来让这个线程得到了偏护。
偏向锁和轻量锁的加锁过程很类似,不同的是在第二步CAS中,set的值是申请锁的线程ID,Tag置为01(就初始状态来说,是不变),这点可以从图2中开出。当发生锁重入时,只需要检查MarkValue中的ThreadID是否与当前线程ID相同即可,相同即可直接重入,不相同说明有不同线程竞争锁,这时候要先将偏向锁撤销(revoke)为轻量锁,再升级为重量锁。 因为偏向锁的MarkValue为线程ID,可以直接定位到持有锁的线程,偏向锁撤销为轻量锁的过程,需要将持有锁的线程中与目标对象相关的最老的lock record地址替换到当前的MarkValue中,并将Tag置为00。
偏向锁的释放不需要做任何事情,这也就意味着加过偏向锁的MarkValue会一直保留偏向锁的状态,因此即便同一个线程持续不断地加锁解锁,也是没有开销的。 另一方面,偏向锁比轻量锁更容易被终结,轻量锁是在有锁竞争出现时升级为重量锁,而一般偏向锁是在有不同线程申请锁时升级为轻量锁,这也就意味着假如一个对象先被线程1加锁解锁,再被线程2加锁解锁,这过程中没有锁冲突,也一样会发生偏向锁失效,不同的是这回要先退化为无锁的状态,再加轻量锁,如图5:
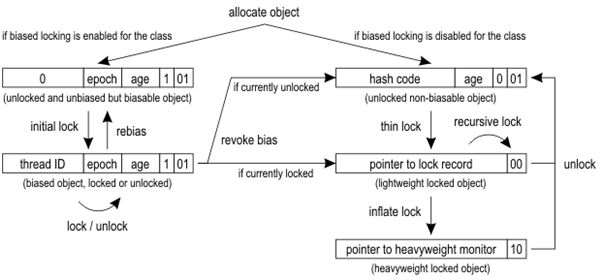
图5. 偏向锁,以及锁升级
回到图2,我们发现出了Tag外还有一个01标志位,上文中提到,这位表示偏向信息,0表示偏向不可用,1表示偏向可用,这位信息同样记录在对象的类对象中,当JVM发现一类对象频繁发生锁升级,而锁升级本身需要一定的开销,这种情况下偏向锁反而成为一种负担,尤其在生产者消费者这类常态竞争锁的场景中,偏向锁是完全无意义的,当JVM搜集到足够的“证据”证明偏向锁不应当存在后,它就会将类对象中的相关标志置0,之后每次生成新对象其偏向信息都是0,都不会再加偏向锁。官网上称之为Bulk revokation。
另外,JVM对那种会有多线程加锁,但不存在锁竞争的情况也做了优化,听起来比较拗口,但在现实应用中确实是可能出现这种情况,因为线程之前除了互斥之外也可能发生同步关系,被同步的两个线程(一前一后)对共享对象锁的竞争很可能是没有冲突的。对这种情况,JVM用一个epoch表示一个偏向锁的时间戳(真实地生成一个时间戳代价还是蛮大的,因此这里应当理解为一种类似时间戳的identifier),对epoch,官方是这么解释的:
A similar mechanism, called bulk rebiasing, optimizes situations in which objects of a class are locked and unlocked by different threads but never concurrently. It invalidates the bias of all instances of a class without disabling biased locking. An epoch value in the class acts as a timestamp that indicates the validity of the bias. This value is copied into the header word upon object allocation. Bulk rebiasing can then efficiently be implemented as an increment of the epoch in the appropriate class. The next time an instance of this class is going to be locked, the code detects a different value in the header word and rebiases the object towards the current thread.
再次一言以蔽之,偏向锁是在轻量锁的基础上减少了减少了锁重入的开销。
重量锁
重量锁在JVM中又叫对象监视器(Monitor),它很像C中的Mutex,除了具备Mutex互斥的功能,它还负责实现了Semaphore的功能,也就是说它至少包含一个竞争锁的队列,和一个信号阻塞队列(wait队列),前者负责做互斥,后一个用于做线程同步。
这两天在网上找资料,发现一篇对重量锁不错的介绍,虽然个人觉得里面对轻量锁,偏向锁介绍的有点少,另外在锁的变化升级上有点含糊。不妨碍它在Monitor描述上的优质。为了尊重原作者,这里贴出它的博客链接:
http://blog.csdn.net/chen77716/article/details/6618779
从这篇博文中我们可以看到,在重量锁的调度过程中,可能有不同线程访问Monitor的队列,所以Monitor的队列必然都是并发队列,而并发队列的操作需要并发控制,是不是发现这又要依赖synchronized?哈哈,当然这种循环依赖是不可能出现的,因为Monitor中的队列都是通过CAS来保证其并发的正确性的。
写到这里,我自己都不由惊叹CAS的神奇,任何阅读到这里的读者都会发现,synchronized的实现中到处都有CAS的身影。那么CAS的代价到底有多大呢? 关于CAS的介绍推荐两篇介绍,和一个答疑:这里还需要说明一下自旋锁与阻塞锁三个过程之间的关系:自旋锁是在发生锁竞争时自旋等待,那么自旋锁的前提是发生锁竞争,而轻量锁,偏向锁的前提都是没有锁竞争,所以加自旋锁应当发生在加重量锁之前,准确地说,是在线程进入Monitor等待队列之前,先自旋一会,重新竞争,如果还竞争不到,才会进入Monitor等待队列。加锁顺序为:
偏向锁—>轻量锁—>自适应自旋锁—>重量锁
CAS具体的代价在不同硬件上有所区别,但从指令复杂度考虑,必然比普通赋值指令多很多时钟周期,但是在CAS和synchronized之间做选择时,依旧倾向CAS,因为synchronized背后布满了CAS,如果你对自己的coding有足够自信,那尝试自己CAS或许能有不错的收获。
最后回答我们最初提出的几个问题:
Q1: synchronized到底有多大开销?与CAS这样的乐观并发控制相比如何?
从上述四个锁的原理以及加速顺序我们不难发现,synchronzied在没有锁冲突的前提下最小开销为一个CAS+栈变量维护(lock record)+一个赋值指令,有锁冲突时需要维护一个Montor对象,通过Moinitor对象维护锁队列,这种情况下涉及到线程阻塞和唤醒,开销很大。
Synchronized大多数情况下没有CAS高效,因为synchronized的最小开销也至少包含一个CAS操作。CAS和synchronized实现的多线程自加操作性能对比见上一篇博客。
Q2:怎样使用synchronized更加高效?
使用synchronized要遵从上篇博客中提到的三个原则,另外如果业务场景允许使用CAS,倾向使用CAS,或者JDK提供的一些乐观并发容器(如ConcurrentLinkedQueue等),也可以先用synchronized将业务逻辑实现,之后做针对性的性能优化。
Q3:与ReentrantLock(JDK1.5之后提供的锁对象)一类的锁相比有什么优劣?
ReentrantLock代表了JDK1.5之后由JAVA语言实现的一系列锁的工具类,而synchronized作为JAVA中的关键字,是由native(根据平台有所不同,一般是C)语言实现的。ReentrantLock虽然也实现了 synchronized中的几种锁优化技术,但与synchronized相比,性能未必好,毕竟JAVA语言效率和native语言效率比大多数情况总有不如。ReentrantLock的优势在于为程序员提供了更多的选择和更好地扩展性,比如公平性锁和非公平性锁,读写锁,CountLatch等。
细心地人会发现,JDK1.6中的并发容器大多数都是用ReentrantLock一类的锁对象实现。例如LinkedBlockingQueue这样的生产者消费者队列,虽然也可以用synchronized实现,但是这种队列中存在若干个互斥和同步逻辑,用synchronized容易使逻辑变得混乱,难以阅读和维护。
总结一点,在业务并发简单清晰的情况下推荐synchronized,在业务逻辑并发复杂,或对使用锁的扩展性要求较高时,推荐使用ReentrantLock这类锁。
Q5:可以对synchronized做哪些优化?
通过介绍synchronized的背后实现,不难看出synchronized本身已经经过了高度优化,而且除了JVM运行时的锁优化外,JAVA编译器还会对synchronized代码块做一些额外优化,例如对肯定不会发生锁竞争的synchronized进行锁消除,或频繁对一个对象进行synchronized时可以锁粗化(如synchronzied写在for循环内时,可以优化到外面),因此程序员在使用synchronized时需要注意的就是上篇博客中提到的三点原则,尤其是控制synchronzied的代码量,将无需互斥执行的代码尽量移到synchronzed之外。
本文来自网易云社区,经作者马进授权发布
相关文章:
【推荐】 微服务实践沙龙-上海站
【推荐】 网易易盾验证码的核心指标和系统兼容性认知大全
【推荐】 数据挖掘统计分析软件推荐