Spark的内存模型
Spark的内存管理机制
- 堆内和堆外内存
- 堆内
- 堆外
- 接口
- 内存空间分配
- 静态内存管理
- Execution的内存管理
- Storage的存储管理
- 统一内存管理
- 新的配置项
- 如何应对内存压力
- MemoryManager
- 存储内存管理
- RDD的持久化机制
- RDD缓存的过程
- 淘汰和落盘
- 执行内存管理
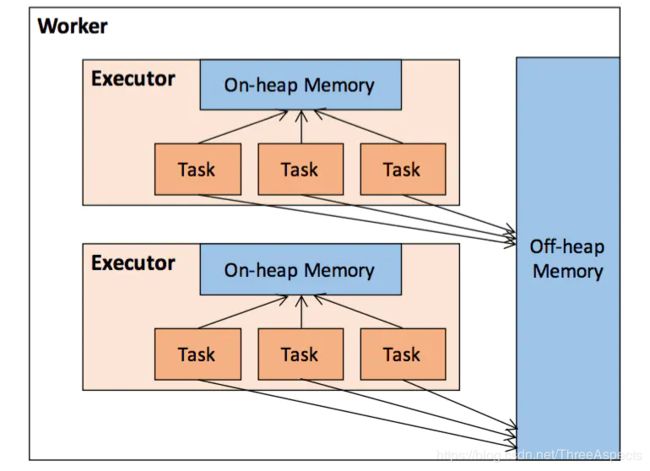
堆内和堆外内存
作为一个JVM进程,Executor的内存管理建立在JVM的内存管理之上,Spark对JVM的堆内(On-heap)空间进行了更为详细的分配,以充分利用内存。同时,Spark引入了堆外(Off-heap)内存,使之可以直接在工作节点的系统内存中开辟空间,进一步优化了内存的使用。
堆内
堆内内存的大小,由Spark应用程序启动时的 –executor-memory 或spark.executor.memory参数配置。Executor内运行的并发任务共享JVM堆内内存,这些任务在缓存RDD和广播(Broadcast)数据时占用的内存被规划为存储(Storage)内存,而这些任务在执行Shuffle时占用的内存被规划为执行(Execution)内存,剩余的部分不做特殊规划,那些Spark内部的对象实例,或者用户定义的Spark应用程序中的对象实例,均占用剩余的空间。不同的管理模式下,这三部分占用的空间大小各不相同。
Spark对堆内内存的管理是一种逻辑上的“规划式”的管理,因为对象实例占用内存的申请和释放都由JVM完成,Spark只能在申请后和释放前记录这些内存:
申请内存:
- Spark在代码中new一个对象实例
- JVM从堆内内存分配空间,创建对象并返回对象引用
- Spark保存该对象的引用,记录该对象占用的内存
释放内存:
- Spark记录该对象释放的内存,删除该对象的引用
- 等待JVM的垃圾回收机制释放该对象占用的堆内内存
对于Spark中序列化的对象,由于是字节流的形式,其占用的内存大小可直接计算,而对于非序列化的对象,其占用的内存是通过周期性地采样近似估算而得,即并不是每次新增的数据项都会计算一次占用的内存大小,这种方法可能导致某一时刻的实际内存有可能远远超出预期。此外,在被Spark标记为释放的对象实例,很有可能在实际上并没有被JVM回收,导致实际可用的内存小于Spark记录的可用内存。所以Spark并不能准确记录实际可用的堆内内存,从而也就无法完全避免内存溢出(OOM)。
堆外
为了进一步优化内存的使用以及提高Shuffle时排序的效率,Spark引入了堆外(Off-heap)内存,使之可以直接在工作节点的系统内存中开辟空间,存储经过序列化的二进制数据。利用JDK Unsafe API,Spark可以直接操作系统堆外内存,减少了不必要的内存开销,以及频繁的GC扫描和回收,提升了处理性能。堆外内存可以被精确地申请和释放,而且序列化的数据占用的空间可以被精确计算,所以相比堆内内存来说降低了管理的难度,也降低了误差。
在默认情况下堆外内存并不启用,可通过配置spark.memory.offHeap.enabled参数启用,并由spark.memory.offHeap.size参数设定堆外空间的大小。除了没有other空间,堆外内存与堆内内存的划分方式相同,所有运行中的并发任务共享存储内存和执行内存。
接口
Spark为存储内存和执行内存的管理提供了统一的接口——MemoryManager,同一个Executor内的任务都调用这个接口的方法来申请或释放内存,同时在调用这些方法时都需要指定内存模式(MemoryMode),这个参数决定了是在堆内还是堆外完成这次操作。MemoryManager的具体实现上,Spark 1.6之后默认为统一管理(Unified Memory Manager)方式,1.6之前采用的静态管理(Static Memory Manager)方式仍被保留,可通过配置spark.memory.useLegacyMode参数启用。两种方式的区别在于对空间分配的方式,下面分别对这两种方式进行介绍。
内存空间分配
静态内存管理
堆内
在静态内存管理机制下,存储内存、执行内存和其他内存三部分的大小在Spark应用程序运行期间是固定的,但用户可以在应用程序启动前进行配置,堆内内存的分配如图所示:
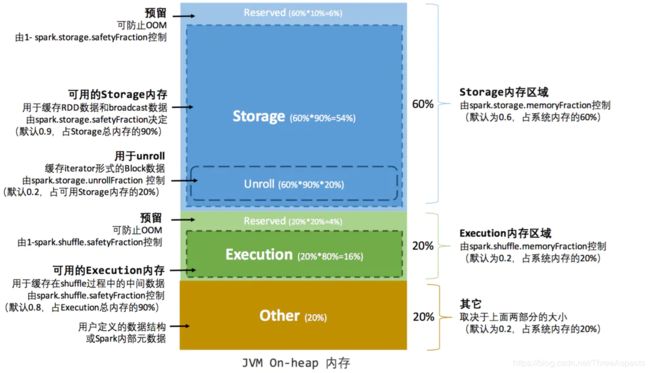
- Execution:在执行shuffle、join、sort和aggregation时,用于缓存中间数据。通过spark.shuffle.memoryFraction进行配置,默认为0.2
- Storage:主要用于缓存数据块以提高性能,同时也用于连续不断地广播或发送大的任务结果。通过spark.storage.memoryFraction进行配置,默认为0.6
- Other:这部分内存用于存储运行Spark系统本身需要加载的代码与元数据,默认为0.2
可用的堆内内存的大小需要按照下面的方式计算:
可用的存储内存 = systemMaxMemory * spark.storage.memoryFraction * spark.storage.safetyFraction
可用的执行内存 = systemMaxMemory * spark.shuffle.memoryFraction * spark.shuffle.safetyFraction
其中systemMaxMemory取决于当前JVM堆内内存的大小,最后可用的执行内存或者存储内存要在此基础上与各自的memoryFraction参数和safetyFraction参数相乘得出。上述计算公式中的两个safetyFraction参数,其意义在于在逻辑上预留出(1-safetyFraction)保险区域,降低因实际内存超出当前预设范围而导致OOM的风险。
堆外
堆外的空间分配较为简单,存储内存、执行内存的大小同样是固定的,如图所示:
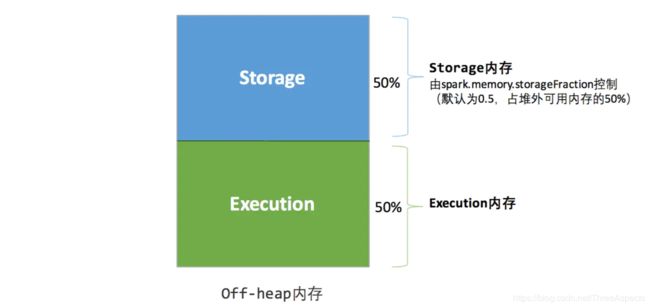
可用的执行内存和存储内存占用的空间大小直接由参数spark.memory.storageFraction决定,由于堆外内存占用的空间可以被精确计算,所以无需再设定保险区域。
静态内存管理机制实现起来较为简单,但很容易造成存储内存和执行内存中的一方剩余大量的空间,而另一方却早早被占满,不得不淘汰或移出旧的内容以存储新的内容。
Execution的内存管理
Execution内存进一步为多个运行在JVM中的任务分配内存。与整个内存分配的方式不同,这块内存的再分配是动态分配的。在同一个JVM下,倘若当前仅有一个任务正在执行,则它可以使用当前可用的所有Execution内存。Spark提供了如下Manager对这块内存进行管理:
- ShuffleMemoryManager:它扮演了一个中央决策者的角色,负责决定分配多少内存给哪些任务。一个JVM对应一个ShuffleMemoryManager
- TaskMemoryManager:记录和管理每个任务的内存分配,它实现为一个page table,用以跟踪堆(heap)中的块,侦测当异常抛出时可能导致的内存泄露。在其内部,调用了ExecutorMemoryManager去执行实际的内存分配与内存释放。一个任务对应一个TaskMemoryManager
- ExecutorMemoryManager:用于处理on-heap和off-heap的分配,实现为弱引用的池允许被释放的page可以被跨任务重用。一个JVM对应一个ExecutorMemeoryManager。
内存管理的执行流程大约如下:
当一个任务需要分配一块大容量的内存用以存储数据时,首先会请求ShuffleMemoryManager,告知:我想要X个字节的内存空间。如果请求可以被满足,则任务就会要求TaskMemoryManager分配X字节的空间。一旦TaskMemoryManager更新了它内部的page table,就会要求ExecutorMemoryManager去执行内存空间的实际分配。
这里有一个内存分配的策略。假定当前的active task数据为N,那么每个任务可以从ShuffleMemoryManager处获得多达1/N的执行内存。分配内存的请求并不能完全得到保证,例如内存不足,这时任务就会将它自身的内存数据释放。根据操作的不同,任务可能重新发出请求,又或者尝试申请小一点的内存块。
释放(spill)任务的内存数据需要谨慎,因为它可能会影响系统的分析性能。为了避免出现过度的内存数据清理操作,Spark规定:除非任务已经获得了整个内存空间的1/(2N)空间,否则不会执行清理操作。倘若没有足够的空闲内存空间,当前任务的请求会被阻塞,直到其他任务清理或释放了它们的内存数据。
spill的操作是由配置项spark.shuffle.spill控制的,默认值为true,用于指定Shuffle过程中如果内存中的数据超过阈值,是否需要将部分数据临时写入外部存储。如果设置为false,这个过程就会一直使用内存,可能导致OOM。
如果Spill的频率太高,可以适当地增加spark.shuffle.memoryFraction来增加Shuffle过程的可用内存数,进而减少Spill的频率。当然,为了避免OOM,可能就需要减少RDD cache所用的内存(即Storage Memory)。
Storage的存储管理
Storage内存由更加通用的BlockManager管理。如前所说,Storage内存的主要功能是用于缓存RDD Partitions,但也用于将容量大的任务结果传播和发送给driver。
Spark提供了Storage Level来指定块的存放位置:Memory、Disk或者Off-Heap。Storage Level同时还可以指定存储时是否按照序列化的格式。当Storage Level被设置为MEMORY_AND_DISK_SER时,内存中的数据以字节数组(byte array)形式存储,当这些数据被存储到硬盘中时,不再需要进行序列化。若设置为该Level,则evict数据会更加高效。
Cache中的数据不会一直存在,所以会在合适的时候被Evict(可以理解抹去数据)。Spark主要采用的Evict策略为LRU,且该策略仅针对内存中的数据块。不过,倘若一个RDD块已经在Cache中存在,那么Spark永远不会为了缓存该RDD块的额外的块而将这个已经存在的RDD块抹掉。
如果BlockManager接收到的数据以迭代器(Iterator)形式组成,且这个Block最终需要保存到内存中,则BlockManager会将迭代器展开(Unrolling),这就意味着需要耗费比迭代器更多的内存,甚至可能该迭代器代表的数组需要的容量会超过内存空间,故而BlockManager只能逐步地展开迭代器以避免OOM,在展开时,需要定期地去检查内存空间是否足够。
Unrollong使用的内存倘若不够,会从Storage Memory中借用。倘若当前没有Block,可以借走所有的Storage Memory空间。如果Storage Memory已有block使用,会强制将内存中的block抹去,唯一约束它的是spark.storage.unrollFraction配置项(默认为0.2),即抹去的内存按照这个配置的比例计算。
统一内存管理
Spark 1.6之后引入的统一内存管理机制,与静态内存管理的区别在于存储内存和执行内存共享同一块空间,可以动态占用对方的空闲区域,如图所示:
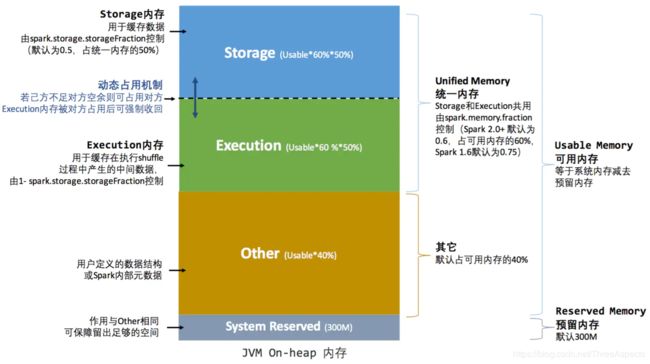
统一内存管理图示——堆内
Reserved Memory。这片区域的内存是Spark内部保留内存,会存储一些Spark的内部对象等内容。Spark 1.6默认的Reserved Memory大小是300MB(可以通过spark.testing.reservedMemory配置得到),在为executor申请内存后,这300MB是用户无法使用的。
User Memory。这个区域的内存是用户在程序中开的对象存储等一系列非Spark管理的内存开销所占用的内存(默认值为(JVM Heap Size - Reserved Memory) * (1-spark.memory.fraction))。
Spark Memory。这个区域的内存是用于Spark管理的内存开销。主要分成了两个部分,Execution Memory和Storage Memory,通过spark.memory.storageFraction来配置两块各占的大小(默认值0.5)。
- Storage Memory。主要用来存储Cache的数据和临时空间序列化时Unroll的数据,以及Broadcast变量Cache级别存储的内容
- Execution Memory。主要用来存储Spark Task执行时使用的内存(比如Shuffle时排序所需要的临时存储空间)

统一内存管理图示——堆外
为了提高内存利用率,Spark统一内存管理模型针对StorageMemory 和 Execution Memory有动态占用机制的规则如下:
- 设定基本的存储内存和执行内存区域(spark.storage.storageFraction参数),该设定确定了双方各自拥有的空间的范围
- 双方的空间都不足时,则存储到硬盘;若己方空间不足而对方空余时,可借用对方的空间;(存储空间不足是指不足以放下一个完整的Block)
- 执行内存的空间被对方占用后,可让对方将占用的部分转存到硬盘,然后“归还”借用的空间
- 存储内存的空间被对方占用后,无法让对方“归还”,因为需要考虑Shuffle过程中的很多因素,实现起来较为复杂
新的配置项
到了1.6版本,Execution Memory和Storage Memory之间支持跨界使用。当执行内存不够时,可以借用存储内存,反之亦然。1.6版本的实现方案支持借来的存储内存随时都可以释放,但借来的执行内存却不能如此。新的版本引入了新的配置项:
spark.memory.fraction(默认值为0.75):用于设置存储内存和执行内存占用堆内存的比例。
若值越低,则发生spill和evict的频率就越高。注意,设置比例时要考虑Spark自身需要的内存量。
spark.memory.storageFraction(默认值为0.5):显然,这是存储内存所占spark.memory.fraction设置比例内存的大小。
当整体的存储容量超过该比例对应的容量时,缓存的数据会被evict。
spark.memory.useLegacyMode(默认值为false):若设置为true,则使用1.6版本前的内存管理机制。此时,如下五项配置均生效:
spark.storage.memoryFraction
spark.storage.safetyFraction
spark.storage.unrollFraction
spark.shuffle.memoryFraction
spark.shuffle.safetyFraction
如何应对内存压力
当内存不足时,需要Evict内存中已有的数据,但是这需要考虑Evict数据的成本。
对于存储内存,eviction的成本取决于设置的Storage Level。如果设置为MEMORY_ONLY就意味着一旦内存中的数据被evict,当再次需要的时候就需要重新计算。设置为MEMORY_AND_DISK_SER自然成本最低,因为内容可以从硬盘中直接获取,无需重新计算,也不需要重新序列化内容,因而唯一的损耗是I/O。
执行内存的Evict就完全不同了。由于被Evict的数据都被spill到磁盘中了,故执行内存存储的数据无需重新计算,且执行数据是以压缩格式存储的,故而降低了序列化的成本。但是,这并不意味着Evict执行内存的成本就一定低于存储内存。在计算过程中,常常需要将spilled的执行内存读回,这就需要维护一个引用。如果不考虑重计算的成本,Evict执行内存的成本甚至要远远高于存储内存。因此实现存储内存的Eviction相对更容易,只需要使用现有的Eviction机制清除掉对应的数据块即可。
MemoryManager
1.6版本的内存管理主要由类MemoryManager承担。这是一个抽象类,提供的主要方法包括:
def acquireExecutionMemory(numBytes:Long):Long
def acquireStorageMemory(blockId:BlockId,numBytes:Long):Long
def releaseExecutionMemory(numBytes:Long):Unit
def releaseStorageMemory(numBytes:Long):Unit
继承这个抽象类的子类包括StaticMemoryManager、UnifiedMemoryManager。前者就是1.6版本之前的内存管理器,后者则实现了最新的内存管理机制。
acquireExecutionMemory方法,最重要的实现放在函数maybeGrowExecutionPool中。这个方法会判断是否需要增加执行内存,倘若事先设置的执行内存空间没有足够可用的内存,就会尝试从存储内存中借用。倘若存储内存的空间已经大于storageRegionSize设置的值,就需要根据借用的内存大小把存储内存中的存储块evict。调整内存大小以及Evict存储块是在maybeGrowExecutionPool函数内部中调用StorageMemoryPool的函数shrinkPoolToFreeSpace来完成的。
存储内存管理
RDD的持久化机制
Task在启动之初读取一个分区时,会先判断这个分区是否已经被持久化,如果没有则需要检查Checkpoint或按照血统重新计算。所以如果一个RDD上要执行多次行动,可以在第一次行动中使用persist或cache方法,在内存或磁盘中持久化或缓存这个RDD,从而在后面的行动时提升计算速度。事实上,cache方法是使用默认的MEMORY_ONLY的存储级别将RDD持久化到内存,故缓存是一种特殊的持久化。堆内和堆外存储内存的设计,便可以对缓存RDD时使用的内存做统一的规划和管理。
RDD的持久化由Spark的Storage模块负责,实现了RDD与物理存储的解耦合。Storage模块负责管理Spark在计算过程中产生的数据,将那些在内存或磁盘、在本地或远程存取数据的功能封装了起来。在具体实现时Driver端和Executor端的Storage模块构成了主从式的架构,即Driver端的BlockManager为Master,Executor端的BlockManager为Slave。Storage模块在逻辑上以Block为基本存储单位,RDD的每个Partition经过处理后唯一对应一个Block。Master负责整个Spark应用程序的Block的元数据信息的管理和维护,而Slave需要将Block的更新等状态上报到Master,同时接收Master的命令,例如新增或删除一个RDD。

RDD缓存的过程
RDD在缓存到存储内存之前,Partition中的数据以迭代器(Iterator)来访问,通过Iterator可以获取分区中每一条序列化或者非序列化的数据项(Record),这些Record的对象实例在逻辑上占用了JVM堆内内存的other部分的空间,同一Partition的不同Record的空间并不连续。
RDD在缓存到存储内存之后,Partition被转换成Block,Record在堆内或堆外存储内存中占用一块连续的空间。将Partition由不连续的存储空间转换为连续存储空间的过程,Spark称之为“展开”(Unroll)。Block有序列化和非序列化两种存储格式,具体以哪种方式取决于该RDD的存储级别。非序列化的Block以一种DeserializedMemoryEntry的数据结构定义,用一个数组存储所有的Java对象,序列化的Block则以SerializedMemoryEntry的数据结构定义,用字节缓冲区(ByteBuffer)来存储二进制数据。每个Executor的Storage模块用一个链式Map结构(LinkedHashMap)来管理堆内和堆外存储内存中所有的Block对象的实例,对这个LinkedHashMap新增和删除间接记录了内存的申请和释放。
因为不能保证存储空间可以一次容纳Iterator中的所有数据,当前的计算任务在Unroll时要向MemoryManager申请足够的Unroll空间来临时占位,空间不足则Unroll失败,空间足够时可以继续进行。对于序列化的Partition,其所需的Unroll空间可以直接累加计算,一次申请。而非序列化的Partition则要在遍历Record的过程中依次申请,即每读取一条Record,采样估算其所需的Unroll空间并进行申请,空间不足时可以中断,释放已占用的Unroll空间。如果最终Unroll成功,当前Partition所占用的Unroll空间被转换为正常的缓存RDD的存储空间,Spark Unroll示意图:

在静态内存管理时,Spark在存储内存中专门划分了一块Unroll空间,其大小是固定的,统一内存管理时则没有对Unroll空间进行特别区分,当存储空间不足是会根据动态占用机制进行处理。
淘汰和落盘
由于同一个Executor的所有的计算任务共享有限的存储内存空间,当有新的Block需要缓存但是剩余空间不足且无法动态占用时,就要对LinkedHashMap中的旧Block进行淘汰(Eviction),而被淘汰的Block如果其存储级别中同时包含存储到磁盘的要求,则要对其进行落盘(Drop),否则直接删除该Block。存储内存的淘汰规则为:
- 被淘汰的旧Block要与新Block的MemoryMode相同,即同属于堆外或堆内内存
- 新旧Block不能属于同一个RDD,避免循环淘汰
- 旧Block所属RDD不能处于被读状态,避免引发一致性问题
- 遍历LinkedHashMap中Block,按照最近最少使用(LRU)的顺序淘汰,直到满足新Block所需的空间。其中LRU是LinkedHashMap的特性。
落盘的流程则比较简单,如果其存储级别符合_useDisk为true的条件,再根据其_deserialized判断是否是非序列化的形式,若是则对其进行序列化,最后将数据存储到磁盘,在Storage模块中更新其信息。
执行内存管理
多任务间的分配
Executor内运行的任务同样共享执行内存,Spark用一个HashMap结构保存了任务到内存耗费的映射。每个任务可占用的执行内存大小的范围为1/2N ~ 1/N,其中N为当前Executor内正在运行的任务的个数。每个任务在启动之时,要向MemoryManager请求申请最少为1/2N的执行内存,如果不能被满足要求则该任务被阻塞,直到有其他任务释放了足够的执行内存,该任务才可以被唤醒。
Shuffle的内存占用
执行内存主要用来存储任务在执行Shuffle时占用的内存,Shuffle是按照一定规则对RDD数据重新分区的过程,Shuffle的Write和Read两阶段对执行内存的使用:
Shuffle Write
- 若在map端选择普通的排序方式,会采用ExternalSorter进行外排,在内存中存储数据时主要占用堆内执行空间
- 若在map端选择Tungsten的排序方式,则采用ShuffleExternalSorter直接对以序列化形式存储的数据排序,在内存中存储数据时可以占用堆外或堆内执行空间,取决于用户是否开启了堆外内存以及堆外执行内存是否足够
Shuffle Read
- 在对reduce端的数据进行聚合时,要将数据交给Aggregator处理,在内存中存储数据时占用堆内执行空间
- 如果需要进行最终结果排序,则要将再次将数据交给ExternalSorter处理,占用堆内执行空间
在ExternalSorter和Aggregator中,Spark会使用一种叫AppendOnlyMap的哈希表在堆内执行内存中存储数据,但在Shuffle过程中所有数据并不能都保存到该哈希表中,当这个哈希表占用的内存会进行周期性地采样估算,当其大到一定程度,无法再从MemoryManager申请到新的执行内存时,Spark就会将其全部内容存储到磁盘文件中,这个过程被称为溢存(Spill),溢存到磁盘的文件最后会被归并(Merge)。
Shuffle Write阶段中用到Tungsten,Spark会根据Shuffle的情况来自动选择是否采用Tungsten排序。Tungsten采用的页式内存管理机制建立在MemoryManager之上,即Tungsten对执行内存的使用进行了一步的抽象,这样在Shuffle过程中无需关心数据具体存储在堆内还是堆外。每个内存页用一个MemoryBlock来定义,并用Object obj和long offset这两个变量统一标识一个内存页在系统内存中的地址。堆内的MemoryBlock是以long型数组的形式分配的内存,其obj的值为是这个数组的对象引用,offset是long型数组的在JVM中的初始偏移地址,两者配合使用可以定位这个数组在堆内的绝对地址;堆外的MemoryBlock是直接申请到的内存块,其obj为null,offset是这个内存块在系统内存中的64位绝对地址。Spark用MemoryBlock巧妙地将堆内和堆外内存页统一抽象封装,并用页表(pageTable)管理每个Task申请到的内存页。
Tungsten页式管理下的所有内存用64位的逻辑地址表示,由页号和页内偏移量组成:
- 页号:占13位,唯一标识一个内存页,Spark在申请内存页之前要先申请空闲页号
- 页内偏移量:占51位,是在使用内存页存储数据时,数据在页内的偏移地址
有了统一的寻址方式,Spark可以用64位逻辑地址的指针定位到堆内或堆外的内存,整个Shuffle Write排序的过程只需要对指针进行排序,并且无需反序列化,整个过程非常高效,对于内存访问效率和CPU使用效率带来了明显的提升
总结:
Spark的存储内存和执行内存有着截然不同的管理方式:对于存储内存来说,Spark用一个LinkedHashMap来集中管理所有的Block,Block由需要缓存的RDD的Partition转化而成;而对于执行内存,Spark用AppendOnlyMap来存储Shuffle过程中的数据,在Tungsten排序中甚至抽象成为页式内存管理,开辟了全新的JVM内存管理机制。