线程的创建及线程池
目录
线程的创建
继承Thread类
实现Runnable接口
实现Callable接口
线程池
执行流程
线程池排队策略
拒绝策略
Executors的四种线程池
CompletionService
小结
前面讲了线程的六种状态及常见方法的比较,此节主要学习小结下线程的创建和线程池相关的一些知识。
线程的创建
1.继承Thread类,重写run方法(其实Thread类本身也实现了Runnable接口);
2.实现Runnable接口,重写run方法;
3.实现Callable接口,重写call方法(有返回值);
4.使用线程池(有返回值);
线程是进程的一个执行单元,本质都是在实现一个线程任务。线程是多线程的形式上实现方式主要有两种:一种是继承Thread类,一种是实现Runnable接口。以上是比较常用的四种创建线程的方式,都是对其的一个封装,下面看一下其具体实现。
继承Thread类
通过JDK提供的Thread类,继承Thread类,重写Thread类的run方法即可。步骤:
(1) 继承thread类,实现run() 方法,具体要完成的task;
(2) 启动线程,new Thread子类().start();
这里创建一个新的线程,都要新建一个Thread子类的对象,创建线程实际调用的是父类Thread空参的构造器,具体实现如下:
public class ExtentThreadTest extends Thread {
private static Logger log = LoggerFactory.getLogger(ExtentThreadTest.class);
public ExtentThreadTest(String threadName){
this.setName(threadName);
}
@Override
public void run() {
//TODO 实现任务task
log.info("线程run:" + Thread.currentThread().getName());
}
public static void main(String[] args) {
for (int i = 0; i < 5; i++) {
//启动线程
new ExtentThreadTest("MyThreadTest").start();
}
}
}实现Runnable接口
实现Runnable接口重写run方法,这是一种用的很多的方式。其实Runnable就是一个线程任务,线程任务和线程的控制分离,这也就是上面所说的解耦。我们要实现一个线程,可以借助Thread类,Thread类要执行的任务就可以由实现了Runnable接口的类来处理。具体步骤如下:
(1) 定一个线程任务类来实现Runnable接口;
(2) 实现run()方法,方法体中的代码就是所执行的task;
(3) 创建线程控制类thread类,将任务作为Thread类的构造方法传入;
(4) 启动线程;
Runnable接口代码:
@FunctionalInterface
public interface Runnable {
public abstract void run();
}实现实例:
public class RunnableThreadTest implements Runnable {
private static Logger log = LoggerFactory.getLogger(RunnableThreadTest.class);
//实现run方法,具体的任务实现
@Override
public void run() {
log.info("Runnable thread test");
}
public static void main(String[] args) {
//实例化线程任务类
RunnableThreadTest task1 = new RunnableThreadTest();
for (int i = 0; i < 5; i++) {
//创建线程对象,并将任务提交给线程执行;
new Thread(task1).start();
}
//函数式接口可用lamba表达式来实现
Runnable task2 = () -> {
log.info("lamba 方式实现 Runnable 任务线程");
};
for (int i = 0; i < 5; i++) {
new Thread(task2).start();
}
}
}ps:内部类的实现
不是新的方式,只是一种新的写法。在有些场景只需要异步处理一次就可以采用此种写法,避免了上面定义线程任务实现类。
public class AnonymousThreadTest {
private static Logger log = LoggerFactory.getLogger(AnonymousThreadTest.class);
public static void main(String[] args) {
//基于Thread子类的实现
new Thread() {
@Override
public void run() {
log.info("AnonymousThreadTest 基于子类thread实现");
}
}.start();
//基于接口的实现
new Thread(() -> {
log.info("基于接口类 Runnable方法的实现");
}).start();
}
}
实现Callable接口
前面的两种方式实现接口Runnable和继承Thread类我们发现都没有返回值,很多时候我们是需要得到任务执行后的一个反馈的,所以需要其中执行得到异常和返回值,这里Callable接口就为我们提供了这样的便利。具体步骤:
(1) 创建一个类实现Callable接口,实现call方法,可提供返回值;
(2) 创建一个FutureTask,指定Callable对象,做为线程任务;
(3) 创建线程,指定线程任务。
(4) 启动线程;
Callable接口类,也是一个函数式接口:
@FunctionalInterface
public interface Callable {
V call() throws Exception;
} PS: Callable中可以通过范型参数来指定线程的返回值类型。通过FutureTask的get方法拿到线程的返回值。
实现实例:
public class CallableThreadTest {
private static Logger log = LoggerFactory.getLogger(CallableThreadTest.class);
public static void main(String[] args) {
//第一步:创建线程任务
Callable taskCall = () -> {
return 1;
};
//第二步:创建一个FutureTask,指定Callable对象作为线程任务;
FutureTask futureTask = new FutureTask<>(taskCall);
//第三步:创建线程,指定线程任务;
Thread callThread = new Thread(futureTask);
//第四步:启动线程
callThread.start();
//得到线程执行的结果及响应的异常信息
try {
Integer result = futureTask.get();//这里get是阻塞的等待;
log.info("thread result:{}", result);
} catch (Exception e) {
log.error("Exception:", e);
}
}
} 线程池
其实工作中用的最多的就是线程池,例如单个任务处理时间短,需要处理的任务数量大我们就可以采用线程池的方式去处理。
那为什么要使用线程池呢?
如果当请求到达的时候就创建线程,有时候线程的创建和开销可能比处理业务请求的时间和资源还要多,如果创建线程过多,可能会因为系统过度消耗内存和线程的过度切换使系统资源不足。为了防止资源不足,我们必须采用“池化”技术来管理线程的创建和销毁,合理利用有限的系统资源,使之能高效稳定的运行。
从上面我们可以知道单一或者循环创建线程存在以下弊端:
(1)不管是继承子类thread或者是接口Runnable和Callbale创建线程,每次通过new Thread()创建对象性能不高;
(2)单一或者循环创建线程缺乏统一管理,频繁的创建和销毁无限定的线程,线程的切换通信竞争可能导致系统性能下降,资源的浪费;
(3)单一的线程创建不够灵活,如定时执行、定期执行、线程中断。
线程池帮我们解决了线程生命周期开销及资源不足的问题,通过重用线程,也提高了请求的响应速度。
使用Java线程池的好处?
(1)重用存在的线程,减少对象创建、消亡的开销,提升性能。
(2)可有效控制管理最大并发线程数,提高系统资源的使用率,同时避免过多资源竞争,避免堵塞。
(3)提供定时执行、定期执行、单线程、并发数控制等功能。
Java里面线程池的顶级接口是Executor,是一个执行线程的工具,真正的线程池接口是ExecutorService
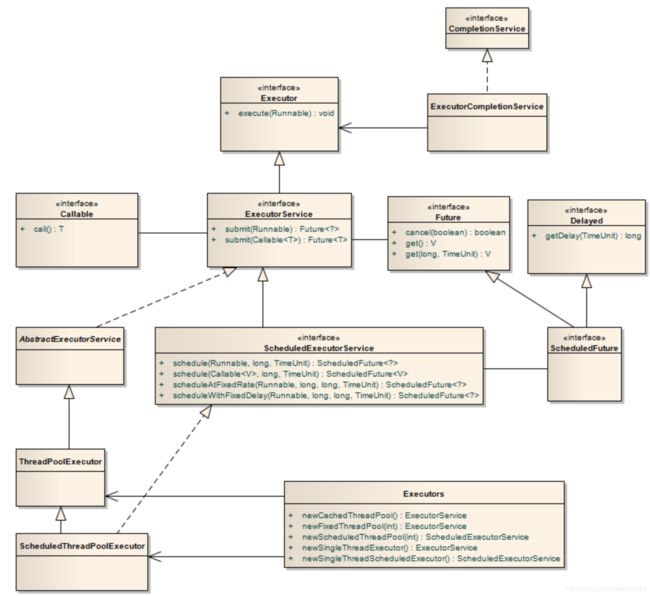 图一:线程池的类体系结构
图一:线程池的类体系结构
JDK 1.5以后,ThreadPoolExecutor作为java.util.concurrent包对外提供基础实现,以内部线程池的形式对外提供管理任务执行,线程调度,线程池管理等等服务。以下是其构造方法:
 图二:线程池的工作流程图
图二:线程池的工作流程图
执行流程
对于线程池的运行过程中,其中比较重要的几个参数是:corePoolSize,maximumPoolSize,workQueue之间关系。如图一所示,当一个新的任务请求到来时:
1.当线程池小于corePoolSize时,新提交任务将创建一个新线程执行任务,即使此时线程池中存在空闲线程;
2.当线程池达到corePoolSize时,新提交任务将被放入workQueue中,等待线程池中任务调度执行;
3.当workQueue已满,且maximumPoolSize>corePoolSize时,未达到最大的线程数,新提交任务会创建新线程执行任务;
4.当提交任务数超过maximumPoolSize时,新提交任务由RejectedExecutionHandler处理;
5.当线程池中超过corePoolSize线程,非核心线程空闲时间达到keepAliveTime时,关闭空闲线程;
6.当设置allowCoreThreadTimeOut(true)时,线程池中核心线程空闲时间达到keepAliveTime也将关闭。
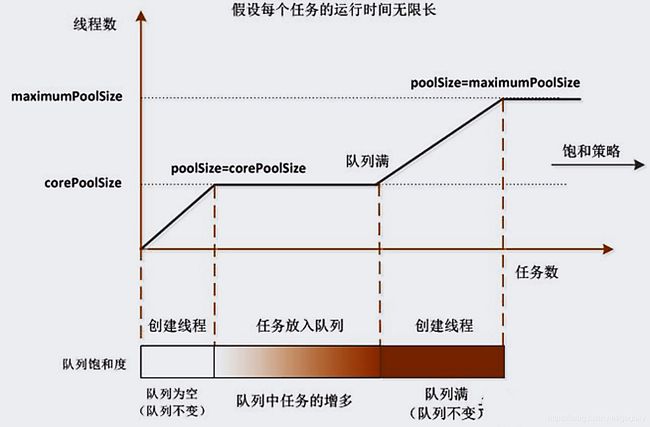 图三:线程数量与阻塞队列的关系
图三:线程数量与阻塞队列的关系
线程池排队策略
BlockingQueue是双缓冲队列。BlockingQueue内部使用两条队列,允许两个线程同时向队列一个存储,一个取出操作。在保证并发安全的同时,提高了队列的存取效率。常用的几种BlockingQueue如下:
(1) 直接提交-SynchronousQueue
直接提交-SynchronousQueue,直接提交策略时线程池不会对任务进行缓存,对于新提交的任务,如果线程池中没有空闲的线程,就创建一个新的线程去处理,线程池具有无限增长的可能性。对于“脉冲式”流量请求的情况可能是致命的,对导致系统oom,或者线程数过多过度切换导致系统瘫痪;
(2) 有界队列-ArrayBlockingQueue
新提交的任务,当线程池中线程达到corePoolSize时,新进任务被放在队列里排队等待处理。
使用大型队列+小型池:可以最大限度地降低 CPU 使用率、降低操作系统资源和上下文切换开销,于此同时也降低吞吐量。如果任务频繁的I/O繁阻塞,增加任务的耗时。
使用小型队列+大型池:CPU使用率较高;池子需要适量,否则容易出现oom或者线程的切换导致的系统崩溃。
(3) 无界队列- LinkedBlockingQueue
使用无界队列将导致在所有 corePoolSize 线程都忙时新任务在队列中等待。这样,创建的线程就不会超过 corePoolSize,此时maximumPoolSize 的值也就无效了。
(4) PriorityBlockingQueue:其所含对象的排序不是FIFO,而是依据对象的自然顺序或者构造函数的Comparator决定。
拒绝策略
策略一:AbortPolicy:丢弃任务并抛出RejectedExecutionException异常【jdk默认策略】;
策略二:DiscardPolicy:直接丢弃新来的任务,队列尾的任务,但是不抛出异常;
策略三:DiscardOldestPolicy:丢弃队列最前面的任务,执行后面的任务;
策略四:CallerRunsPolicy:即不用线程池中的线程执行,在调用execute的线程里面执行此command,会阻塞入口;
具体实现如下:
public class ThreadPoolRejectTest {
private static Logger log = LoggerFactory.getLogger(ThreadPoolRejectTest.class);
public static void main(String[] args) {
//创建一个核心线程为1,最大线程为2,核心线程存活时间为1s,有界队列为3的等待队列;
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(1,2,1000,
TimeUnit.MILLISECONDS,new ArrayBlockingQueue<>(3));
for (int i =0 ; i < 10 ; i++){
ThreadTask task = new ThreadTask(i);
threadPool.execute(task);
log.info("线程池中的线程数:{}, 队列中等待任务的线程数:{}, 已执行完的线程数:{}",threadPool.getCorePoolSize(),threadPool.getQueue().size(),threadPool.getCompletedTaskCount());
}
threadPool.shutdown();
}
}
class ThreadTask implements Runnable {
private static Logger log = LoggerFactory.getLogger(ThreadTask.class);
private int taskNum;
public ThreadTask(int num) {
this.taskNum = num;
}
@Override
public void run() {
log.info("线程 {} 任务 {} 执行 完毕。", Thread.currentThread().getName(), taskNum);
try {
sleep(1);//这里为了效果明显,必须模拟业务的停顿时间,否则执行太快看不到等待的效果;
} catch (Exception e) {
e.printStackTrace();
}
}
}使用策略一:AbortPolicy
因为jdk默认的就是策略一,所以默认运行结果和设置AbortPolicy策略一样。
//创建一个核心线程为1,最大线程为2,核心线程存活时间为1s,有界队列为3的等待队列,采用默认的AbortPolicy 拒绝策略;
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(1, 2, 3000,
TimeUnit.MILLISECONDS, new ArrayBlockingQueue<>(3),new ThreadPoolExecutor.AbortPolicy());运行结果
 图四:AbortPolicy策略执行结果
图四:AbortPolicy策略执行结果
从执行结果来看,任务任然执行完成了任务0-1-2-3-4 ,总过5个,任务5-6-7-8-9被抛弃了。AbordPolicy策略是,线程达到最大核心线程1个pool-1-thread-1时,放入队列,队列满,又创建了pool-1-thread-2,此时新提交的任务将会直接丢弃,且抛出RejectedExecutionException异常。
使用策略二:DiscardPolicy
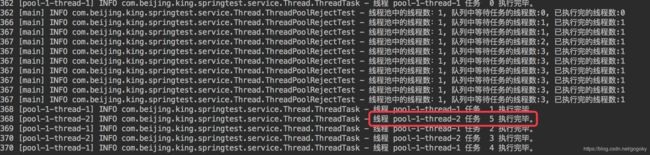 图五:
DiscardPolicy策略执行结果
图五:
DiscardPolicy策略执行结果
从结果来看,任务任然执行完成了任务0-1-2-3-4-5 ,总过6个,任务6-7-8-9被抛弃了。但是和策略一不同的地方是没有抛出拒绝异常,且丢弃的是后来最新提交的任务。
使用策略三:DiscardOldestPolicy
//创建一个核心线程为1,最大线程为2,核心线程存活时间为1s,有界队列为3的等待队列,采用DiscardOldestPolicy拒绝策略;
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(1, 2, 3000,
TimeUnit.MILLISECONDS, new ArrayBlockingQueue<>(3),new ThreadPoolExecutor.DiscardOldestPolicy());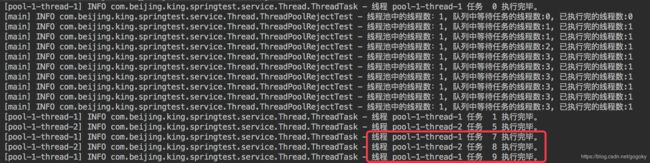 图六:DiscardOldestPolicy策略执行结果
图六:DiscardOldestPolicy策略执行结果
从结果来看,线程池执行来0-1-5-7-8-9任务,抛弃来2-3-4-6四个任务,没有抛出异常且丢弃的是队列中老的请求。
策略四:CallerRunsPolicy
//创建一个核心线程为1,最大线程为2,核心线程存活时间为1s,有界队列为3的等待队列,采用CallerRunsPolicy拒绝策略;
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(1, 2, 3000,
TimeUnit.MILLISECONDS, new ArrayBlockingQueue<>(3),new ThreadPoolExecutor.CallerRunsPolicy());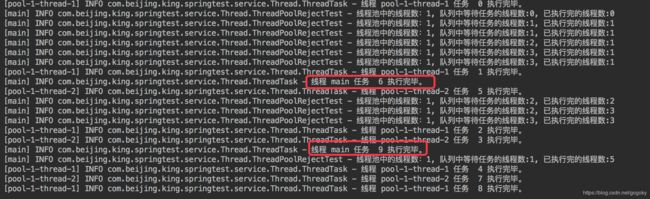 图七:
CallerRunsPolicy策略执行结果
图七:
CallerRunsPolicy策略执行结果
从结果来看,所有的10个任务全部执行,当队列满时,不想放弃执行任务。但是由于池中已经没有任何资源了,那么就直接使用调用该execute的线程本身main来执行。同时也减缓来请求的提交速度,达到来反控的目的。
Executors的四种线程池
newFixedThreadPool,构造一个固定线程数目的线程池,配置的corePoolSize与maximumPoolSize大小相同,同时使用了一个无界LinkedBlockingQueue存放阻塞任务,因此多余的任务将存在再阻塞队列,不会由RejectedExecutionHandler处理。
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(
nThreads,
nThreads,
0L,
TimeUnit.MILLISECONDS,
new LinkedBlockingQueue());
} newCachedThreadPool,构造一个缓冲功能的线程池,配置corePoolSize=0,maximumPoolSize=Integer.MAX_VALUE,keepAliveTime=60s,以及一个无容量的阻塞队列 SynchronousQueue,因此任务提交之后,将会创建新的线程执行;线程空闲超过60s将会销毁。
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(
0,
Integer.MAX_VALUE,
60L,
TimeUnit.SECONDS,
new SynchronousQueue());
} newSingleThreadExecutor,构造一个只支持一个线程的线程池,配置corePoolSize=maximumPoolSize=1,无界阻塞队列LinkedBlockingQueue;保证任务由一个线程串行执行。
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService(
new ThreadPoolExecutor(
1,
1,
0L,
TimeUnit.MILLISECONDS,
new LinkedBlockingQueue()));
} ScheduledThreadPoolExecutor,构造有定时功能的线程池,配置corePoolSize,无界延迟阻塞队列DelayedWorkQueue;有意思的是:maximumPoolSize=Integer.MAX_VALUE,由于DelayedWorkQueue是无界队列,所以这个值是没有意义的。
public ScheduledThreadPoolExecutor(int corePoolSize,ThreadFactory threadFactory) {
super(corePoolSize,
Integer.MAX_VALUE,
0,
TimeUnit.NANOSECONDS,
new DelayedWorkQueue(),
threadFactory);
}使用实例:
ScheduledExecutorService scheduledThreadPool= Executors.newScheduledThreadPool(3);
//延迟3秒后执行任务;
scheduledThreadPool.schedule(new ThreadTask(1),1,TimeUnit.SECONDS);
//延迟1秒后,每3秒执行一次;
scheduledThreadPool.scheduleAtFixedRate(new ThreadTask(2),1,3,TimeUnit.SECONDS);CompletionService
如果你向Executor提交了一个批处理任务,并且希望在它们完成后获得结果。为此你可以将每个任务的Future保存进一个集合,然后循环这个集合调用Future的get()取出数据,但是但获取方式确实阻塞的,根据添加到线程池中的线程顺序,依次获取,获取不到就阻塞,为了解决这种情况,也可以采用轮询的做法。幸运的是CompletionService帮你做了这件事情。CompletionService整合了Executor和BlockingQueue的功能。提交给ExecutorCompletionService的任务,会被封装成一个QueueingFuture(一个FutureTask子类),此类的唯一作用就是在done()方法中,增加了将执行的FutureTask加入了内部队列,此时外部调用者,就可以take到相应的执行结束的任务,其take方法返回已完成的一个Callable任务对应的Future对象,然后通过get就可以拿到我们想要的数据了。 CompletionService的take返回的future是哪个先完成就先返回哪一个,而不是根据提交顺序。
CompletionService接口定义了一组任务管理接口:
- submit() - 提交任务
- take() - 获取任务结果
- poll() - 获取任务结果
| ExecutorCompletionService类是CompletionService接口的实现:
ExecutorCompletionService主要用与管理异步任务 (有结果的任务, 任务完成后要处理结果) |
具体实例:
public static void main(String[] args) throws InterruptedException {
//自定义线程池
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(2, 4, 3000,
TimeUnit.MILLISECONDS, new ArrayBlockingQueue<>(10));
//使用CompletionService实现任务
CompletionService completionService = new ExecutorCompletionService(threadPool);
//提交任务
for (int i = 0; i < 5; i++) {
int finalI = i;
//TODO 验证等所有的任务提交后才能获取,这点需要注意;容易阻塞大量的任务,队列过大容易引起OOM;
if(i == 4){
sleep(4000);
}
completionService.submit(new Callable() {
@Override
public Integer call() throws Exception {
//TODO 验证非阻塞的获取,与Future+ Callable对比;
if (finalI == 3){
sleep(3000);
}
return finalI;
}
});
}
//获取结果
for (int i = 0; i < 5; i++) {
try {
log.info("批量处理任务后返回的结果:{}", completionService.take().get());
} catch (Exception e) {
e.printStackTrace();
}
}
//关闭线程池
threadPool.shutdown();
} 运行结果:
 图八: CompletionService执行结果
图八: CompletionService执行结果
从上图可以看出,i=3的始终是最后执行完,通过CompletionService获取的结果是非阻塞的,那个任务先返回就返回那个。
线程池监控
如果系统大量使用线程池,且请求量较大,需要使用线程池的监控,更快的定位问题,更好的掌握系统的性能。具体有以下几个常用呢的参数需要注意:
- taskCount:线程池需要执行的任务数量。
- completedTaskCount:线程池在运行过程中已完成的任务数量,小于或等于taskCount。
- largestPoolSize:线程池里曾经创建过的最大线程数量。通过这个数据可以知道线程池是否曾经满过。如该数值等于线程池的最大大小,则表示线程池曾经满过。
- getPoolSize:线程池的线程数量。如果线程池不销毁的话,线程池里的线程不会自动销毁,所以这个大小只增不减。
- getActiveCount:获取活动的线程数。
@PostConstruct
public void init() {
scheduledExecutorService.scheduleAtFixedRate(() -> {
/**
* 线程池需要执行的任务数
*/
long taskCount = threadPoolExecutor.getTaskCount();
/**
* 线程池在运行过程中已完成的任务数
*/
long completedTaskCount = threadPoolExecutor.getCompletedTaskCount();
/**
* 曾经创建过的最大线程数
*/
long largestPoolSize = threadPoolExecutor.getLargestPoolSize();
/**
* 线程池里的线程数量
*/
long poolSize = threadPoolExecutor.getPoolSize();
/**
* 线程池里活跃的线程数量
*/
long activeCount = threadPoolExecutor.getActiveCount();
log.info("async-executor monitor. taskCount:{}, completedTaskCount:{}, largestPoolSize:{}, poolSize:{}, activeCount:{}",
taskCount, completedTaskCount, largestPoolSize, poolSize, activeCount);
}, 0, 10, TimeUnit.MINUTES);
}小结
自定义线程池需要根据业务的特性来决定,可以从以下几个角度来分析:
1、任务的性质:CPU密集型任务、IO密集型任务和混合型任务。
- CPU密集型任务应配置尽可能小的线程,如配置Ncpu+1个线程的线程池;
- 由于IO密集型任务线程并不是一直在执行任务,则应配置尽可能多的线程,最大线程数一般设为2Ncpu+1最好;
- 混合型的任务,如果可以拆分,将其拆分成一个CPU密集型任务和一个IO密集型任务,只要这两个任务执行的时间相差不是太大,那么分解后执行的吞吐量将高于串行执行的吞吐量。
- 如果这两个任务执行时间相差太大,则没必要进行分解。
2、任务的优先级:高、中和低。
根据优先级可依使用优先级队列;例如保证任务处理的顺序性;
3、任务的执行时间:长、中和短。
任务执行的时间比较长,不是cpu密集型,可以适当的增大线程数;
4、任务的依赖性:是否依赖其他系统资源,如数据库连接。
看任务场景,任务量不大可采取无界队列,如果任务量非常大,要用有界队列,有界队列能增加系统的稳定性和预警能力,防止产生过多的线程导致OOM及系统不可用;如果有依赖数据库的情况,处理比较耗时,可以适当增大线程数,更好的利用cpu;
ps:如果要获取任务执行结果,用CompletionService,但是注意,获取任务的结果的要重新开一个线程获取,如果在主线程获取,就要等任务都提交后才获取,就会阻塞大量任务结果,队列过大OOM,所以最好异步开个线程获取结果。
资料参考:
https://blog.csdn.net/qq_22771739/article/details/81462059
https://blog.csdn.net/wang_rrui/article/details/78541786
https://blog.csdn.net/xu__cg/article/details/52962991
https://blog.csdn.net/zhh1072773034/article/details/74240897
https://blog.csdn.net/xu__cg/article/details/52962991