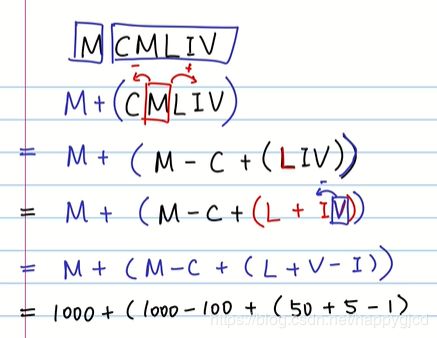最适合【小白】的力扣字符串题目精选(附详细解法)持续更新
文章目录
- 有效的括号
- 实现strStr()【双指针+字符串】
- 分割平衡字符串(使用计数)
- “气球”的最大数量(使用计数)
- IP地址无效化(充分使用python特性)(替换类)
- 字符串的第一个唯一字符(哈希表)
- 反转字符串(双指针)
- 找字符串中的第一个唯一字符
- 罗马数字转整数
有效的括号
给定一个只包括 ‘(’,’)’,’{’,’}’,’[’,’]’ 的字符串,判断字符串是否有效。
有效字符串需满足:
左括号必须用相同类型的右括号闭合。
左括号必须以正确的顺序闭合。
注意空字符串可被认为是有效字符串。
示例 1:
输入: "()"
输出: true
示例 2:
输入: "()[]{}"
输出: true
示例 3:
输入: "(]"
输出: false
示例 4:
输入: "([)]"
输出: false
示例 5:
输入: "{[]}"
输出: true
代码:
class Solution:
def isValid(self, s: str) -> bool:
d = {'{':'}','[':']','(':')'}
res = []
if len(s) == 1:
return False
for i in s:
# 如果是开括号就放到栈里面
if i in d.keys():
res.append(i)
# 如果是闭括号,而且栈不为空,弹出栈顶元素
elif res:
# 如果栈顶元素与s的元素相同,继续循环
if i == d[res.pop()]:
continue
# 如果不相同返回False
else:
return False
# 其他情况返回false,比如()[
else:
return False
return True if not res else False
实现strStr()【双指针+字符串】
给定一个 haystack 字符串和一个 needle 字符串,在 haystack 字符串中找出 needle 字符串出现的第一个位置 (从0开始)。如果不存在,则返回 -1。
示例 1:
输入: haystack = "hello", needle = "ll"
输出: 2
示例 2:
输入: haystack = "aaaaa", needle = "bba"
输出: -1
这题我用了比较暴力的解法,报了字符串超界,以及没有通过"",""的情况,通过了测试样例
class Solution:
def strStr(self, haystack: str, needle: str) -> int:
if len(needle) == "":
return 0
if len(haystack) < len(needle):
return -1
p,i = 0,0 # 双指针
while haystack[p] != needle[i] and p < len(haystack)-1:
p += 1
t = p
while haystack[p] == needle[i] and p < len(haystack)-1 and i < len(haystack):
p += 1
i += 1
if i == len(needle):
return t
return -1
正确解法使用了一个偏移表:
- 题解1(使用一个偏移表)
- 题解2(使用了三种方法,其中一种是暴力法)
- 暴力解法:
class Solution:
def strStr(self, haystack: str, needle: str) -> int:
for i in range(len(haystack) - len(needle)+1):
if haystack[i:i+len(needle)] == needle:
return i
return -1
分割平衡字符串(使用计数)
在一个「平衡字符串」中,‘L’ 和 ‘R’ 字符的数量是相同的。
给出一个平衡字符串 s,请你将它分割成尽可能多的平衡字符串。
返回可以通过分割得到的平衡字符串的最大数量。
示例 1:
输入:s = "RLRRLLRLRL"
输出:4
解释:s 可以分割为 "RL", "RRLL", "RL", "RL", 每个子字符串中都包含相同数量的 'L' 和 'R'。
示例 2:
输入:s = "RLLLLRRRLR"
输出:3
解释:s 可以分割为 "RL", "LLLRRR", "LR", 每个子字符串中都包含相同数量的 'L' 和 'R'。
示例 3:
输入:s = "LLLLRRRR"
输出:1
解释:s 只能保持原样 "LLLLRRRR".
提示:
1 <= s.length <= 1000
s[i] = ‘L’ 或 ‘R’
题解(和我的思路一致)
思路是遍历字符串,然后遇到R计数器加1,遇到L计数器减1,当计数器为0的时候num+1,最后返回num
class Solution:
def balancedStringSplit(self, s: str) -> int:
if not s:
return 0
count,num = 0,0
for i in s:
if i == 'R':
count += 1
elif i == 'L':
count -= 1
if count == 0:
num += 1
return num
“气球”的最大数量(使用计数)
给你一个字符串 text,你需要使用 text 中的字母来拼凑尽可能多的单词 “balloon”(气球)。
字符串 text 中的每个字母最多只能被使用一次。请你返回最多可以拼凑出多少个单词 “balloon”。
示例 1:
输入:text = "nlaebolko"
输出:1
示例 2:
输入:text = "loonbalxballpoon"
输出:2
示例 3:
输入:text = "leetcode"
输出:0
提示:
1 <= text.length <= 10^4
text 全部由小写英文字母组成
我的错误尝试:
class Solution:
def maxNumberOfBalloons(self, text: str) -> int:
a = list(text)
target = 'balloon'
target = list(target)
count, num = 0,0
for i in range(len(target)):
if target[i] in a:
a.remove(target)
count += 1
if count == 7:
num += 1
break
return num
正确的解法应该是:求出text里面气球的字母的最小数字的个数,这个个数就是气球的最大数量,注意’o’和’l’这两个字母要除以2,因为出现了两次。
参考:参考这个题解
代码如下:
class Solution:
def maxNumberOfBalloons(self, text: str) -> int:
t = min([text.count(i) if i not in ['l','o'] else text.count(i)/2 for i in list(set(list(text)))])
if t<1:
return 0
return int(t)
IP地址无效化(充分使用python特性)(替换类)
给你一个有效的 IPv4 地址 address,返回这个 IP 地址的无效化版本。
所谓无效化 IP 地址,其实就是用 “[.]” 代替了每个 “.”。
示例 1:
输入:address = "1.1.1.1"
输出:"1[.]1[.]1[.]1"
示例 2:
输入:address = "255.100.50.0"
输出:"255[.]100[.]50[.]0"
提示:
给出的 address 是一个有效的 IPv4 地址
代码:
class Solution(object):
def defangIPaddr(self, address = ''):
"""
:type address: str
:rtype: str
"""
# 1. 规则.join(list)
# print '[.]'.join(address.split('.'))
# 2. replace(之前格式, 之后格式)
return address.replace('.', '[.]')
给定一个字符串,你需要反转字符串中每个单词的字符顺序,同时仍保留空格和单词的初始顺序。
示例 1:
输入: "Let's take LeetCode contest"
输出: "s'teL ekat edoCteeL tsetnoc"
注意:在字符串中,每个单词由单个空格分隔,并且字符串中不会有任何额外的空格。
字符串的第一个唯一字符(哈希表)
给定一个字符串,找到它的第一个不重复的字符,并返回它的索引。如果不存在,则返回 -1。
案例:
s = "leetcode"
返回 0.
s = "loveleetcode",
返回 2.
力扣官方题解
反转字符串(双指针)
编写一个函数,其作用是将输入的字符串反转过来。输入字符串以字符数组 char[] 的形式给出。
不要给另外的数组分配额外的空间,你必须原地修改输入数组、使用 O(1) 的额外空间解决这一问题。
你可以假设数组中的所有字符都是 ASCII 码表中的可打印字符。
示例 1:
输入:["h","e","l","l","o"]
输出:["o","l","l","e","h"]
示例 2:
输入:["H","a","n","n","a","h"]
输出:["h","a","n","n","a","H"]
1.双指针
class Solution:
def reverseString(self, s: List[str]) -> None:
"""
Do not return anything, modify s in-place instead.
"""
# double pointer
i,j = 0,len(s)-1
while i<j:
s[i],s[j] = s[j],s[i]
i+=1;j-=1
2.递归
class Solution:
def reverseString_v0(self, s: List[str]) -> None:
"""
Do not return anything, modify s in-place instead.
"""
# recursion, but the recursion depth exceede
def recur(tmps: List[str]) -> str:
if len(tmps)<=1:
return tmps
else:
return recur(tmps[1:])+[tmps[0]]
s[:] = recur(s)
3.一步法
class Solution:
def reverseString(self, s: List[str]) -> None:
"""
Do not return anything, modify s in-place instead.
"""
# one step by python
s[:] = s[::-1]
找字符串中的第一个唯一字符
给定一个字符串,找到它的第一个不重复的字符,并返回它的索引。如果不存在,则返回 -1。
案例:
s = "leetcode"
返回 0.
s = "loveleetcode",
返回 2.
class Solution(object):
def firstUniqChar(self, s: str) -> int:
# 先假设最小索引为最后的字符索引
min_unique_char_index = len(s)
# 已知字符串由小写字母构成,则遍历a-z
for c in "abcdefghijklmnopqrstuvwxyz":
i = s.find(c)
# 分别从目标的字符串头和字符串尾查找对应字母的索引;如果两索引相等,则说明是单一字符
if i != -1 and i == s.rfind(c):
# 更新最新的最小索引
min_unique_char_index = min(min_unique_char_index, i)
# 如果返回值不为最后字符的索引,则返回最小索引值
# 否则,根据题意,返回-1
return min_unique_char_index if min_unique_char_index != len(s) else -1
来源于评论区丰富的题解
罗马数字转整数
刚开始我的思路:
class Solution:
def romanToInt(self, s: str) -> int:
a = {'I':1, 'V':5, 'X':10, 'L':50,
'C':100, 'D':500, 'M':1000}
ans=0
for i in range(len(s)):
# 遍历s里面的字母
if i<len(s)-1 and a[s[i]]<a[s[i+1]]:
# 如果s中左边的字母对应的阿拉伯数字比较小
ans-=a[s[i]]
else:
ans+=a[s[i]]
return ans
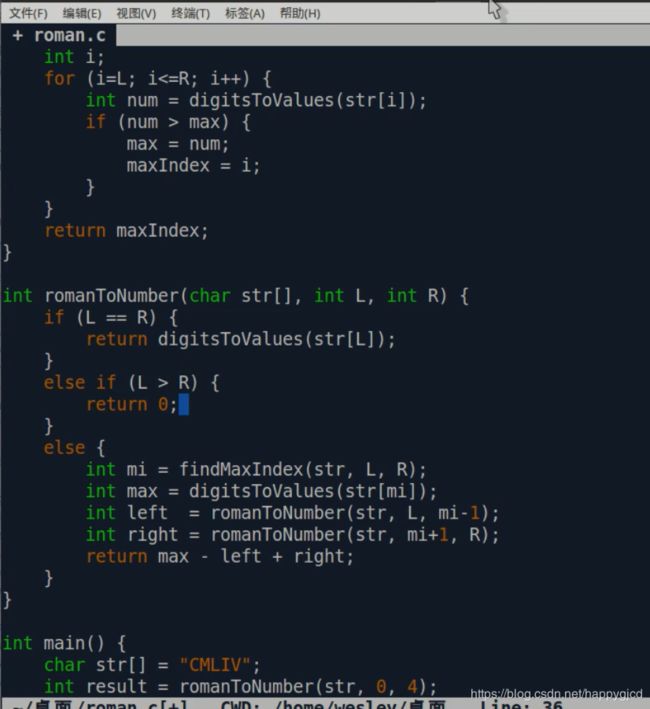
- 思路是找到罗马数字里面最大数字对应的字母,然后减掉左边的罗马数字对应的数字,再加上右边的罗马数字对应的数字,即为最终的数字。这里我们需要编写三个函数,
- 实现:首先编写一个查找罗马数字的单个字母与阿拉伯数字的对应关系的函数(用字典就行),然后还要编写一个找出字母对应的最大数字的函数,最后编写一个递归函数,这个函数用来实现减去右边罗马数字对应的阿拉伯数字,加上左边罗马数字对应的阿拉伯数字
- 罗马数字的书写规则,根据这些规则,很容易写出代码。