Spark SQL与DataFrame详解以及使用
Spark一站式的解决方案使得大数据技术快速发展,其中,最核心的部分当然也包括Spark SQL,它简单,常用,高效。与Spark Core中类似的,Spark SQL中最核心的部分是DataFrame抽象模型,本篇文章主要介绍Spark SQL的核心内容以及其简单使用。
转载请标明原文地址:原文链接
Spark SQL是Spark的一个结构化数据处理模块,提供一个DataFrame编程模型抽象,可以看做是一个分布式SQL查询引擎。Spark SQL主要由Catalyst优化,Spark SQL内核,Hive支持三部分组成。
Catalyst优化处理查询语句的整个过程,包括解析,绑定,优化,物理计划等,主要由关系代数,表达式以及查询优化组成。
Spark SQL内核处理数据的输入输出,从不同的数据源(结构化Parquet文件和JSON文件,Hive表,外部数据库,创建RDD)获取数据,执行查询,并将结果输出成DataFrame。
Hive支持是值对Hive数据的处理,主要包括HiveSQL,MetaStore,SerDes,UDFS等。
Spark SQL架构
Spark SQL对SQL语句的处理和关系型数据库SQL处理类似,将SQL语句解析成一颗数(Tree),然后通过规则(rule)的模式匹配,对树进行绑定,优化等,然后得到查询结果。
Tree的具体操作是通过TreeNode实现的;Rule是一个抽象类,是通过RuleExecutor完成的,应用与Spark SQL的Analyzer,Optimizer,Spark Planner等组件中,可以简便,模块化地对Tree进行Transform操作。
在整个SQL语句执行的过程中,主要依赖了优化框架Catalyst,把SQL语句解析,绑定,优化等,最终将逻辑计划优化后并且转换为物理执行计划,最后变成DataFrame模型。
Spark SQL的整个架构图如下所示:
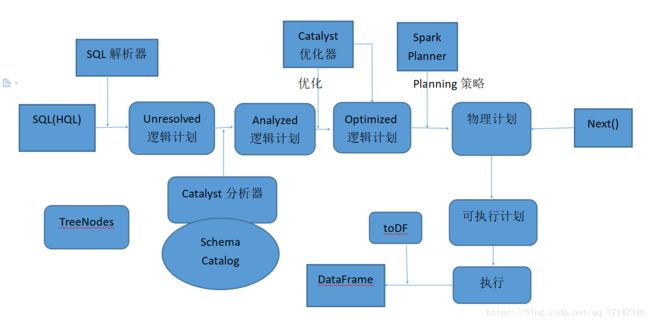
- 使用SqlParser对SQL语句进行解析,生成Unresolved逻辑计划(没有提取schema信息)。
- 使用Catalyst分析器,结合数据字典(catalog)进行绑定,生成Analyzed逻辑计划,在此过程中,Schema Catalog则要提取schema信息。
- 使用Catalyst优化器对Analyzed逻辑计划进行优化,按照优化规则得到Optimized逻辑计划。
- 接着和Spark Planner交互,使用相应的策略将逻辑计划转换为物理计划,然后调用next函数,生成可执行物理计划。
- 调用toDF,最后生成DataFrame。
Spark SQL有以下几点特征:
1.兼容多种数据格式,如上面所说的parquet文件,HIve表,JSON文件等等。
2.方便扩展,它的优化器,解析器都可以重新定义。
3.性能优化方面:采用了内存列式存储,动态字节码生成等技术,还采用了内存缓存数据。
4.支持多种语言操作,包括JAVA,SCALA,PYTHON,R语言等。
Spark SQL性能
1.内存列式存储
Spark SQL内部使用内存列式模式缓存表,仅扫描需要的列,并且自动调整压缩比使内存使用率和GC压力最小化,如果缓存了数据,则下次执行时不需要重复读取数据。
2.动态代码生成和字节码生成技术
对于一个简单的查询,如:
select a+b from table这个查询,在传统的方式中,会将SQL语句生成一个表达树,然后调用虚函数确认Add两边的数据类型,然后再调用虚函数计算装箱最后返回结果,计算时需要多次涉及虚函数的使用,打断了CPU的利用,减缓了执行效率。
因此,使用字节码技术会将表达式使用特定的代码动态 编译,为每一个查询生成自定义字节码,然后运行。最后需要说明的是DataFrame也是惰性的,在遇见Action操作的时候才会真正的去执行。
创建DataFrame
创建一个json格式文件,内容如下所示;
{"name":"Mirckel"}
{"name":"Andy","age":30}
{"name":"Jsutin","age":13}创建以及相关操作如下代码所示:
val sqlContext=new sql.SQLContext(sc)
val df=sqlContext.jsonFile("file:///F:/spark-2.0.0/SparkApp/src/cn/just/shinelon/txt/SparkSql01.json")
println(df.show()) //打印表数据
println(df.printSchema()) //以树的形式打印DataFrame的Schema
println(df.select(df("name"),df("age")+1).show())下面有两种方式来操作RDD数据源,即将现有的RDD转化为DataFrame。
操作的文件内容格式如下:
shinelon,19
mike,20
wangwu,251.以反射机制推断RDD模式
主要分下面三个步骤:
- 必须创建case类,只有case类才能隐式转换为DataFrame。
- 必须生成DataFrame,进行注册临时表操作。
- 必须在内存中register成临时表,才能供查询使用。
val conf=new SparkConf()
.setMaster("local")
.setAppName("SparkSqlDemo01")
val sc=new SparkContext(conf)
val sqlContext=new sql.SQLContext(sc)
//使用case定义Schema(不能超过22个属性),实现Person接口
//只有case类才能隐式转换为一个DataFrame
case class Person(name:String,age:Int)
//使用前缀hdfs://来标识HDFS存储系统的文件
val people=sc.textFile("file:///F:/spark-2.0.0/SparkApp/src/cn/just/shinelon/txt/SparkSql02.txt")
.map(_.split(",")).map(p=>Person(p(0),p(1).trim.toInt)).toDF
//DataFrame注册临时表
people.refisterTempTable("person")
//使用sql运行SQL表达式
val result=sqlContext.sql("SELECT name,age from person WHERE age>=19")
println(result.map(t=>"Name:"+t(0)).collect())
println(result.map(t=>"Name:"+t.getAs[String](1)).collect())
2.以编程方式定义RDD模型
主要分三个步骤:
- 从原始RDD中创建一个Rows的RDD。
- 创建一个表示为StructType类型的Schema,匹配在第一步创建的RDD的Rows的结构。
- 通过SQLContext提供的createDataFrame方法,应用Schema到Rows的RDD。
代码如下所示:
val conf=new SparkConf()
.setMaster("local")
.setAppName("SparkSqlDemo01")
val sc=new SparkContext(conf)
val sqlContext=new sql.SQLContext(sc)
val sqlContext=new sql.SQLContext(sc)
//使用case定义Schema(不能超过22个属性),实现Person接口
//只有case类才能隐式转换为一个DataFrame
case class Person(name:String,age:Int)
//使用前缀hdfs://来标识HDFS存储系统的文件
val people=sc.textFile("file:///F:/spark-2.0.0/SparkApp/src/cn/just/shinelon/txt/SparkSql02.txt")
.map(_.split(",")).map(p=>Person(p(0),p(1).trim.toInt)).toDF
//DataFrame注册临时表
people.refisterTempTable("person")
//使用sql运行SQL表达式
val result=sqlContext.sql("SELECT name,age from person WHERE age>=19")
println(result.map(t=>"Name:"+t(0)).collect())
println(result.map(t=>"Name:"+t.getAs[String](1)).collect())至此,就介绍了Spark SQL的基本原理以及初步使用,Spark SQL凭借着内存的快速访问快速在大数据界发展,有人说它取代了HIVE,这种说法过于狭隘,Hive还是应用广泛,只能说代替了Hive的 部分功能,并不能完全代替Hive来使用。谢谢阅读!!!