1、 一个C++源文件从文本到可执行文件经历的过程
2、#include 的顺序以及尖叫括号和双引号的区别
3、进程和线程,为什么要有线程
4、C++11有哪些新特性
5、malloc的原理,brk系统调用干什么的,mmap呢
6、C++的内存管理方式,STL的allocator,最新版本默认使用的分配器
7、hash表的实现,包括STL中的哈希桶长度常数。
8、hash表如何rehash,怎么处理其中保存的资源
9、Redis的rehash怎么做的,为什么要渐进rehash,渐进rehash怎么实现的
10、Redis的定时机制怎么实现的,有哪些弊端,你将如何改进这个弊端
11、Redis是单线程的,为什么这么高效
12、Redis的数据类型有哪些,底层怎么实现
13、Redis和memcached的区别
14、TCP的模型,状态转移
15、用过哪些设计模式,单例模式,观察者模式的多线程安全问题
16、用过多线程吗,以前的多线程代码还能怎么优化,线程池的实现
17、epoll怎么实现的,reactor模型组成
18、线程间的同步方式,最好说出具体的系统调用
19、哈希表的桶个数为什么是质数,合数有何不妥?
答案分析:
1、 一个C++源文件从文本到可执行文件经历的过程
对于C/C++编写的程序,从源代码到可执行文件,一般经过下面四个步骤:
1).预处理,产生.ii文件
2).编译,产生汇编文件(.s文件)
3).汇编,产生目标文件(.o或.obj文件)
4).链接,产生可执行文件(.out或.exe文件)
2、#include 的顺序以及尖叫括号和双引号的区别
1. #include的顺序的区别:
头文件的引用顺序对于程序的编译还是有一定影响的。如果要在文件a.h中声明一个在文件b.h中定义的变量,而不引用b.h。那么要在a.c文件中引用b.h文件,并且要先引用b.h,后引用a.h,否则汇报变量类型未声明错误,也就是常见的某行少个“;”符号。
2. #include尖括号和双引号的区别:
1)#include<> ,认为该头文件是标准头文件。编译器将会在预定义的位置集查找该头文件,这些预定义的位置可以通过设置查找路径环境变量或者通过命令行选项来修改。使用的查找方式因编译器的不同而差别迥异。
2)#include"",认为它是非系统头文件,非系统头文件的查找通常开始于源文件所在的路径。查找范围大于<>。
3、进程和线程,为什么要有线程
1、和进程相比,它是一种非常"节俭"的多任务操作方式。在linux系统下,启动一个新的进程必须分配给它独立的地址空间,建立众多的数据表来维护它的代码段、堆栈段和数据段,这是一种"昂贵"的多任务工作方式。(资源)
2、运行于一个进程中的多个线程,它们之间使用相同的地址空间,而且线程间彼此切换所需时间也远远小于进程间切换所需要的时间。据统计,一个进程的开销大约是一个线程开销的30倍左右。(切换效率)
3、线程间方便的通信机制。对不同进程来说,它们具有独立的数据空间,要进行数据的传递只能通过进程间通信的方式进行,这种方式不仅费时,而且很不方便。线程则不然,由于同一进城下的线程之间贡献数据空间,所以一个线程的数据可以直接为其他线程所用,这不仅快捷,而且方便。
(通信) 除以上优点外,多线程程序作为一种多任务、并发的工作方式,还有如下优点:
1、使多CPU系统更加有效。操作系统会保证当线程数不大于CPU数目时,不同的线程运行于不同的CPU上。(CPU设计保证)
2、改善程序结构。一个既长又复杂的进程可以考虑分为多个线程,成为几个独立或半独立的运行部分,这样的程序才会利于理解和修改。(代码易维护)
4、C++11有哪些新特性
1)关键字及新语法:auto、nullptr、for
2)STL容器:std::array、std::forward_list、std::unordered_map、std::unordered_set
3)多线程:std::thread、std::atomic、std::condition_variable
4)智能指针内存管理:std::shared_ptr、std::weak_ptr
5)其他:std::function、std::bind和lamda表达式
5、malloc的原理,brk系统调用干什么的,mmap呢
malloc的实现方案:
1)malloc函数的实质是它有一个将可用的内存块连接为一个长长的列表的所谓空闲链表。
2)调用malloc()函数时,它沿着连接表寻找一个大到足以满足用户请求所需要的内存块。 然后,将该内存块一分为二(一块的大小与用户申请的大小相等,另一块的大小就是剩下来的字节)。 接下来,将分配给用户的那块内存存储区域传给用户,并将剩下的那块(如果有的话)返回到连接表上。
3)调用free函数时,它将用户释放的内存块连接到空闲链表上。
4)到最后,空闲链会被切成很多的小内存片段,如果这时用户申请一个大的内存片段, 那么空闲链表上可能没有可以满足用户要求的片段了。于是,malloc()函数请求延时,并开始在空闲链表上检查各内存片段,对它们进行内存整理,将相邻的小空闲块合并成较大的内存块。
brk和mmap:
从操作系统角度来看,进程分配内存有两种方式,分别由两个系统调用完成:brk和mmap(不考虑共享内存)。
1、brk是将数据段(.data)的最高地址指针_edata往高地址推;
2、mmap是在进程的虚拟地址空间中(堆和栈中间,称为文件映射区域的地方)找一块空闲的虚拟内存。
这两种方式分配的都是虚拟内存,没有分配物理内存。在第一次访问已分配的虚拟地址空间的时候,发生缺页中断,操作系统负责分配物理内存,然后建立虚拟内存和物理内存之间的映射关系。
在标准C库中,提供了malloc/free函数分配释放内存,这两个函数底层是由brk,mmap,munmap这些系统调用实现的。
6、C++的内存管理方式,STL的allocator,最新版本默认使用的分配器
C++的内存管理方式:
在c++中内存主要分为5个存储区:
栈(Stack):局部变量,函数参数等存储在该区,由编译器自动分配和释放.栈属于计算机系统的数据结构,进栈出栈有相应的计算机指令支持,而且分配专门的寄存器存储栈的地址,效率分高,内存空间是连续的,但栈的内存空间有限。
堆(Heap):需要程序员手动分配和释放(new,delete),属于动态分配方式。内存空间几乎没有限制,内存空间不连续,因此会产生内存碎片。操作系统有一个记录空间内存的链表,当收到内存申请时遍历链表,找到第一个空间大于申请空间的堆节点,将该节点分配给程序,并将该节点从链表中删除。一般,系统会在该内存空间的首地址处记录本次分配的内存大小,用于delete释放该内存空间。
全局/静态存储区:全局变量,静态变量分配到该区,到程序结束时自动释放,包括DATA段(全局初始化区)与BSS段(全局未初始化段)。其中,初始化的全局变量和静态变量存放在DATA段,未初始化的全局变量和静态变量存放在BSS段。BSS段特点:在程序执行前BSS段自动清零,所以未初始化的全局变量和静态变量在程序执行前已经成为0.
文字常量区:存放常量,而且不允许修改。程序结束后由系统释放。程序代码区:存放程序的二进制代码
SGI 版本STL的默认配置器std::alloc参见:
《STL源码剖析》
1)考虑到小型区块所可能造成的内存碎片问题,SGI设计了双层配置器。第一级配置器直接使用malloc()和free();第二级则视情况采取不同的策略:当配置区块超过128bytes时,视为“足够大”,便调用第一级配置器;当配置区块小于128bytes时,视之为“过小”,为了降低额外负担,便采用memory pool(内存池)整理方式,而不在求助于第一级配置器。
2)内存池的核心:内存池和16个自由链表(各自管理8,16,...,128bytes的小额区块)。在分配一个小区块时,首先在所属自由链表中寻找,如果找到,直接抽出分配;若所属自由链表为空,则请求内存池为所属自由链表分配空间;默认情况下,为该自由链表分配20个区块,若内存池剩余容量不足,则分配可分配的最大容量;若内存池连一个区块都无法分配,则调用chunk_alloc为内存池分配一大块区块;若内存不足,则尝试调用malloc分配,否则返回bad_alloc异常。
7、hash表的实现,包括STL中的哈希桶长度常数。
hash表的实现主要涉及两个问题:散列函数和碰撞处理。1)hash function (散列函数)。最常见的散列函数:f(x) = x % TableSize .
2)碰撞问题(不同元素的散列值相同)。解决碰撞问题的方法有许多种,包括线性探测、二次探测、开链等做法。SGL版本使用开链法,使用一个链表保持相同散列值的元素。虽然开链法并不要求表格大小必须为质数,但SGI STL仍然以质数来设计表格大小,并且将28个质数(逐渐呈现大约两倍的关系)计算好,以备随时访问,同时提供一个函数,用来查询在这28个质数之中,“最接近某数并大于某数”的质数。
8、hash表如何rehash,怎么处理其中保存的资源
先想想为什么需要rehash:
因为,当loadFactor(负载因子)<=1时,hash表查找的期望复杂度为O(1). 因此,每次往hash表中添加元素时,我们必须保证是在loadFactor <1的情况下,才能够添加。
模仿C++的vector扩容方式,Hash表中每次发现loadFactor==1时,就开辟一个原来桶数组的两倍空间(称为新桶数组),然后把原来的桶数组中元素全部转移过来到新的桶数组中。注意这里转移是需要元素一个个重新哈希到新桶中的。
9、Redis的rehash怎么做的,为什么要渐进rehash,渐进rehash怎么实现的
为了避免rehash对服务器造成影响,服务器不是一次将ht[0]里面的所有键值对全部rehash到ht[1],而是分多次、渐进式地将ht[0]里面的键值对慢慢地rehash到ht[1].
以下是哈希表渐进式rehash的详细步骤:
为 ht[1] 分配空间, 让字典同时持有 ht[0] 和 ht[1] 两个哈希表。
在字典中维持一个索引计数器变量 rehashidx , 并将它的值设置为 0 , 表示rehash工作正式开始。
在rehash进行期间, 每次对字典执行添加、删除、查找或者更新操作时, 程序除了执行指定的操作以外, 还会顺带将 ht[0] 哈希表在 rehashidx 索引上的所有键值对rehash到 ht[1] , 当rehash工作完成之后, 程序将 rehashidx 属性的值增一。
随着字典操作的不断执行, 最终在某个时间点上, ht[0] 的所有键值对都会被rehash至 ht[1] , 这时程序将 rehashidx 属性的值设为 -1 , 表示rehash操作已完成。
渐进式rehash的好处在于它采取分而治之的方式, 将rehash键值对所需的计算工作均滩到对字典的每个添加、删除、查找和更新操作上, 从而避免了集中式rehash而带来的庞大计算量。
10、Redis的定时机制怎么实现的,有哪些弊端,你将如何改进这个弊端
Redis服务器是一个事件驱动程序,服务器需要处理以下两类事件:文件事件(服务器对套接字操作的抽象)和时间事件(服务器对定时操作的抽象)。Redis的定时机制就是借助时间事件实现的。
一个时间事件主要由以下三个属性组成:id:时间事件标识号;when:记录时间事件的到达时间;timeProc:时间事件处理器,当时间事件到达时,服务器就会调用相应的处理器来处理时间。一个时间事件根据时间事件处理器的返回值来判断是定时事件还是周期性事件。
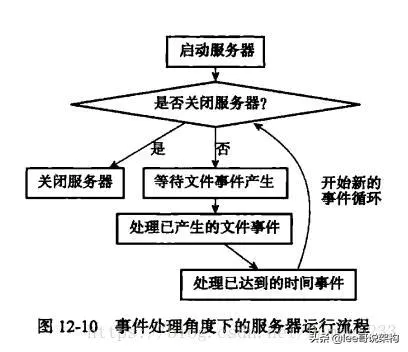
弊端:Redis对时间事件的实际处理时间并不准时,通常会比时间事件设定的到达事件稍晚一些。
改进:多线程?一个处理文件事件,一个处理时间事件? (不确定)。
11、Redis是单线程的,为什么这么高效
虽然Redis文件事件处理器以单线程方式运行,但是通过使用I/O多路复用程序来监听多个套接字,文件事件处理器既实现了高性能的网络通信模型,又可以很好地与Redis服务器中其他同样以单线程运行的模块进行对接,这保持了Redis内部单线程设计的简单性。
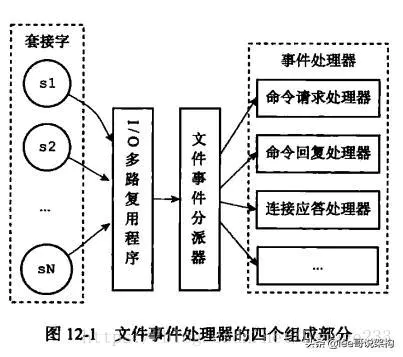
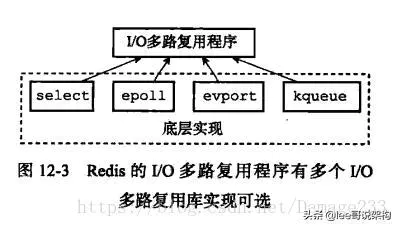
12、Redis的数据类型有哪些,底层怎么实现
1)字符串:整数值、embstr编码的简单动态字符串、简单动态字符串(SDS)
2)列表:压缩列表、双端链表
3)哈希:压缩列表、字典
4)集合:整数集合、字典
5)有序集合:压缩列表、跳跃表和字典
13、Redis和memcached的区别
Redis和memcached的区别:
1)数据类型 :redis数据类型丰富,支持set liset等类型;memcache支持简单数据类型,需要客户端自己处理复杂对象
2)持久性:redis支持数据落地持久化存储;memcache不支持数据持久存储。
3)分布式存储:redis支持master-slave复制模式;memcache可以使用一致性hash做分布式。
4)value大小不同:memcache是一个内存缓存,key的长度小于250字符,单个item存储要小于1M,不适合虚拟机使用
5)数据一致性不同:redis使用的是单线程模型,保证了数据按顺序提交;memcache需要使用cas保证数据一致性。CAS(Check and Set)是一个确保并发一致性的机制,属于“乐观锁”范畴;原理很简单:拿版本号,操作,对比版本号,如果一致就操作,不一致就放弃任何操作
6)cpu利用:redis单线程模型只能使用一个cpu,可以开启多个redis进程
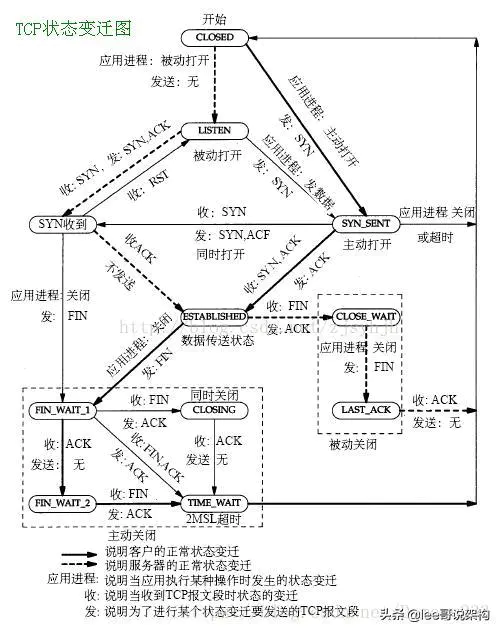
14、TCP的模型,状态转移
TCP四层模型:

状态转移:
熟悉三次握手 和 四次释放的TCP状态转移。
15、用过哪些设计模式,单例模式,观察者模式的多线程安全问题
设计模式
1)TemplateMethod模式:《effectivec++》 条款35 :借助Non-virtualInterface手法实现TemplateMethod模式
2)Strategy模式:《effectivec++》 条款35:借助FunctionPointers实现Strategy模式、借助std::function完成Strategy模式、古典Strategy模式
16、用过多线程吗,以前的多线程代码还能怎么优化,线程池的实现
线程的创建
#include
int pthread_create(pthread_t *restrict thread,
const pthread_attr_t *restrict attr,
void *(*start_routine)(void*),
void *restrict arg);
线程终止:
从线程函数return。这种方法对主线程不适用,从main函数return相当于调用exit。
一个线程可以调用pthread_cancel终止同一进程中的另一个线程。
线程可以调用pthread_exit终止自己。
线程池的实现:https://pan.baidu.com/s/1qHUhyCLFzHuHaio7-PAYiQ 密码:emmq
17、epoll怎么实现的,reactor模型组成
epoll实现:
第一步:epoll_create()系统调用。此调用返回一个句柄,之后所有的使用都依靠这个句柄(eventpoll的对象)来标识。
structeventpoll{
....
/*红黑树的根节点,这颗树中存储着所有添加到epoll中的需要监控的事件*/
structrb_rootrbr;
/*双链表中则存放着将要通过epoll_wait返回给用户的满足条件的事件*/
structlist_headrdlist;
....
};
第二步:epoll_ctl()系统调用。通过此调用向epoll对象中添加、删除、修改感兴趣的事件,返回0标识成功,返回-1表示失败。
第三部:epoll_wait()系统调用。通过此调用收集收集在epoll监控中已经发生的事件。
Reactor模型:
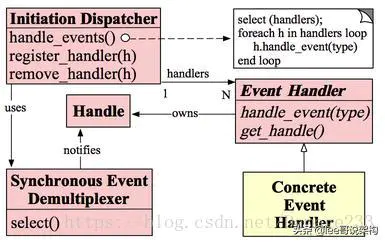
1)Handle:即操作系统中的句柄,是对资源在操作系统层面上的一种抽象,它可以是打开的文件、一个连接(Socket)、Timer等。由于Reactor模式一般使用在网络编程中,因而这里一般指Socket Handle,即一个网络连接。
2)Synchronous Event Demultiplexer(同步事件复用器):阻塞等待一系列的Handle中的事件到来,如果阻塞等待返回,即表示在返回的Handle中可以不阻塞的执行返回的事件类型。这个模块一般使用操作系统的select来实现。
3)Initiation Dispatcher:用于管理EventHandler,即EventHandler的容器,用以注册、移除EventHandler等;另外,它还作为Reactor模式的入口调用SynchronousEventDemultiplexer的select方法以阻塞等待事件返回,当阻塞等待返回时,根据事件发生的Handle将其分发给对应的EventHandler处理,即回调EventHandler中的handle_event()方法。
4)EventHandler:定义事件处理方法:handle_event(),以供InitiationDispatcher回调使用。
5)ConcreteEventHandler:事件EventHandler接口,实现特定事件处理逻辑。
18、线程间的同步方式,最好说出具体的系统调用
1)互斥量(mutex)
#include
int pthread_mutex_destroy(pthread_mutex_t *mutex); //销毁
int pthread_mutex_init(pthread_mutex_t *restrict mutex,
const pthread_mutexattr_t *restrict attr); //初始化
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
int pthread_mutex_lock(pthread_mutex_t *mutex); //上锁
int pthread_mutex_trylock(pthread_mutex_t *mutex); //尝试上锁
int pthread_mutex_unlock(pthread_mutex_t *mutex);
2)条件变量(Condition Variable)
#include
int pthread_cond_destroy(pthread_cond_t *cond); //销毁
int pthread_cond_init(pthread_cond_t *restrict cond,
const pthread_condattr_t *restrict attr); //初始化
pthread_cond_t cond = PTHREAD_COND_INITIALIZER;
int pthread_cond_timedwait(pthread_cond_t *restrict cond,
pthread_mutex_t *restrict mutex,
const struct timespec *restrict abstime);
int pthread_cond_wait(pthread_cond_t *restrict cond,
pthread_mutex_t *restrict mutex);
int pthread_cond_broadcast(pthread_cond_t *cond);
int pthread_cond_signal(pthread_cond_t *cond);
3)信号量(Semaphore)
#include
int sem_init(sem_t *sem, int pshared, unsigned int value);
int sem_wait(sem_t *sem);
int sem_trywait(sem_t *sem);
int sem_post(sem_t * sem);
int sem_destroy(sem_t * sem);
————————————————
调用sem_wait()可以获得资源,使semaphore的值减1,如果调用sem_wait()时semaphore的值已经是0,则挂起等待。如果不希望挂起等待,可以调用sem_trywait()。调用sem_post()可以释放资源,使semaphore的值加1,同时唤醒挂起等待的线程。
19、哈希表的桶个数为什么是质数,合数有何不妥
质数比合数更容易避免冲撞,也就是说使用质数时,哈希效果更好,原始数据经哈希后分布更均匀。
作者:Yt_cc
链接:https://www.jianshu.com/p/d601ace77c9b
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。