大家好,我是阿里云数据库产品事业部的玄陵,真名郭超。
本次的分享大概分三个部分:Cassandra云数据库简介、Cassandra云数据库特性以及Q&A。
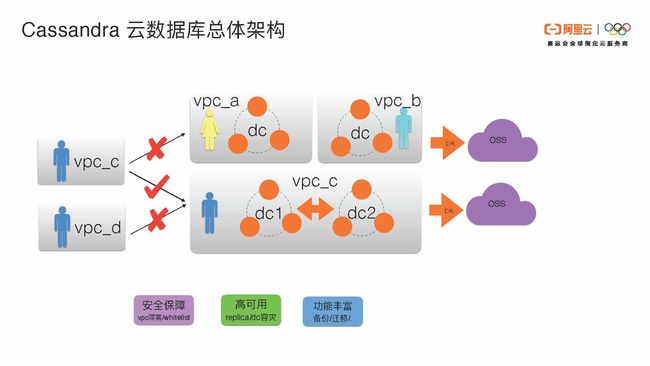
我们先了解一下Cassandra云数据库在阿里云上的部署和架构。首先这个架构主要反映了三个方向:
- 安全保障和VPC隔离:在阿里云上,Cassandra数据库的不同用户有不同的VPC。通过VPC隔离和白名单,可以保证在阿里云上用户之间的数据是相对安全的。因为每个用户有自己的VPC环境,在自己的VPC环境下只能访问自己的VPC数据。不同的VPC之间是不可以互相访问与之无关的VPC账号的数据的。在同VPC下,可以实现单DC或多DC容灾的部署。
- 高可用:阿里云上Cassandra的高可用性分为单DC之内replica级别的高可用以及DC之间容灾的高可用。
- 功能丰富:具有备份和迁移等功能。每个VPC环境下的用户的集群可以通过我们自己实现的系统备份到OSS上面。阿里云OSS可以提供极致的数据可靠性的服务。
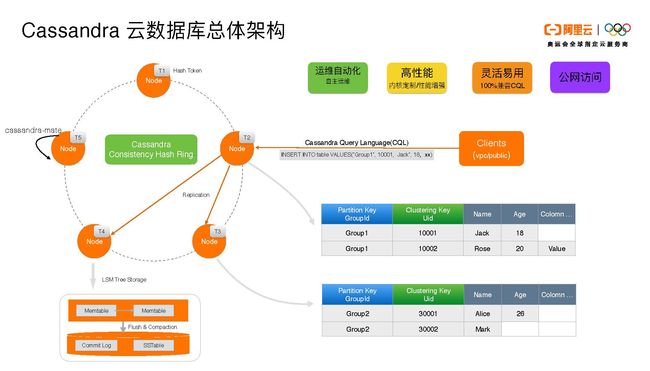
接下来我们深入了解一下单个DC和集群的情况。
- 运维自动化可以提供自主运维。我们自己实现的Cassandra-mate的服务可以实现一些运维的自动化,比如compaction的调优、节点扩容和增加节点、以及监控和报警。
- 为了追求高性能,我们在内核定制以及性能增强方面做了一些相关的改进。
- 灵活易用,我们的云服务是百分百兼容Apache Cassandra CQL的协议。
除此之外,我们其它的架构和Apache Cassandra几乎是一样的。

接下来我们介绍一下Cassandra云数据库的特性:
- 开箱即用:免除运维烦恼
- 弹性伸缩、线性扩展:在云环境下,利用云的资源可以进行快速的扩容和缩容,这点非常符合Cassandra现有的特性。
- 高可用、多活:多副本、持续可写、就近读取,这个是Cassandra自带的。
- 备份恢复:在Cassandra的基础上我们做了一些配置,比如全量和增量备份和恢复,从而保证相当高的数据可靠性,以防DBA的误操作(比如删库)造成数据不可用。
- 细粒度监控:能让性能数据一目了然。
即将上线的服务包括:
- 安全加固:SSL+TDE全链路加密
- 审计日志:访问记录、有据可查
- CloudDBA:自动诊断、智能优化
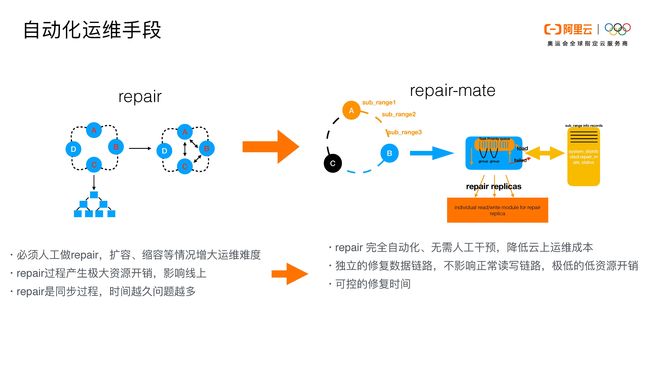
接下来,我们介绍一些我们在功能上做的优化。由于时间关系,我们只能重点介绍一部分功能优化。
第一点,我们做了一些自动化运维手段。
这个事情的背景是由于Cassandra是一个去中心化的数据库,社区建议用户做repair,目的主要是保证Cassandra三个或多个副本之间的一致性。Repair能够把副本上的数据做一个修复或者补齐,保证副本的数据是一致的。Repair是必须要做的,然而在我们的使用场景中,repair会引入一些问题:
- 扩容缩容会增加运维难度:在目前阿里云的部署环境下,一个用户对应一个或多个cluster,当用户增多,需要管理的集群规模或数量就非常多,这会给我们repair的运维带来比较大的困难。
- 当某个集群扩容或缩容时,我们需要对repair做一些相应的调整,这也会增大运维的难度。Repair的过程会产生极大的资源开销,会影响我们线上的一些服务。
- Repair是一个同步过程,当数据量很大或副本之间数据差异很多时,repair耗时较多。Repair时间越久,就越容易出现意想不到的问题。
在介绍我们的改进措施之前,我先来大概介绍一下repair的机制:在图中我们可以看到三个副本ABC,第一步repair会在三个副本上构建全量的Merkle Tree,第二步会比较ABC副本的Merkle Tree之间数据的差异,第三步再通过一个类似于Steaming的过程把数据补齐。
我们改进的目的是什么呢?
我们希望我们repair的过程是自动化的,不需要引入人工干预。这样当我们云上的集群越来越多或者用户扩容缩容的时候,我们不需要人工的干预,这样可以降低云上运维的复杂性,大大释放了人力资源。第二个目的是希望整个repair的过程是一个开销较小的过程,这样可以保证repair对线上服务的影响很小。
那么我们repair的大概原理是这样的:我们可以在图上看到ABC三个副本,每个副本节点上都会有一个primary range主范围。我们会把primary range切分成很小的组。每个node只会负责修复自己primary range的数据,它不会去管别的数据。比如说B这个节点,它有一个primary range是A到B,除此之外它也会有C到A的副本数据,但是这个部分节点B不管,它只管A到B的数据的修复。这样会降低我们修复的数据量。
节点B只管A到B的primary range,我们会把primary range切分成很小的段,这个部分是为了我们后面做断点续传。我们会针对每一个sub_range做修复。这个服务是在Cassandra的kernel里面,它是一个独立的修复模块。当Cassandra进程启动后,这个服务会首先会将primary range切分成sub_range。每一个sub_range会有一个自己的task,然后这些task会进行排列。这之后,我们会对所有的sub_ range从开头到结尾进行轮询scan。每次scan会把sub_range里的数据拿出来,现在我们设置的是每一次拿10条数据。我们独立实现的repair的module的读写链路和正常的读写链路是分开的,这样的好处是repair不会影响正常的读写链路。
除此之外,官方建议,一轮repair应该在gc_grace_seconds范围之内做完。那么我们可以通过流控控制每一个primary range修复的时间,也可以控制每一次服务对线上的影响。每一个sub-range做完之后,我们会在一个system表里面做记录。比如当我们修复到B节点的sub_range2时出现问题了,下一次B节点再启动时会通过system表断点续传到sub_range2,然后sub_range2继续完成任务。这样做的好处是很多过程可以完全自动化,独立的修复链路不会影响正常的读写链路,除此之外还可以降低对线上服务的影响以及有一个可控的修复时间。
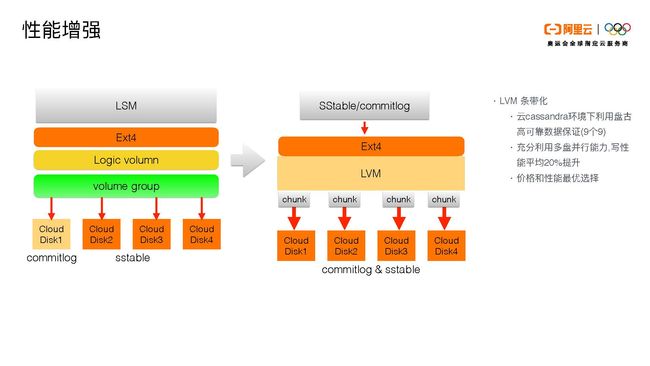
接下来我们就性能增强方面选一个点进行详细介绍。
我们的性能增强基于我们阿里云的部署形态,我们的底层使用的是盘古提供的块存储设备。我们可以看到Cassandra原有的架构是上面是LSM,底下是我们现在用的Ext4文件系统,然后是一些操作系统的处理(比如Logical Volume和Volume Group),最终落到下面是有一个单独的disk放commitlog,其他的disk会放sstable。这样的部署模式会引入一些问题:
- 我们看到写入链是先写入commitlog,再写入memtable,然后再返回给客户。那么当我们把一个commitlog部署在Cloud Disk 1上面,它的写入吞吐会受到Cloud Disk 1的限制。另外commitlog现在在社区也是不支持部署在多盘上面的。
- 第二个点是在我们这个云上面涉及到产品形态的设计。首先,commitlog这个盘对我们不会产生费用,我们只售卖sstable的文件存储。那么如果这样去设计的话,额外的commitlog存储会产生额外的费用,继而产生对客户的额外费用,这样对客户来说相对不太公平。
- 第三,如果我们有四块盘,我们拿出一块盘给commitlog,其它的给sstable,这样的资源利用也是不公平的。
那么我们的优化方式就是把底层通过LVM条带,可以把下层的cloud disk1-4 bind起来。这样当从上层写入时,不论是sstable还是commitlog,都可以充分利用四块盘的资源,而不是只有disk 1写commitlog,其它disk 2、3、4写sstable。我们是把四块盘的并发能力全用起来。当写入一个commitlog,它不只是被写入disk 1。通过LVM条带,commitlog和sstable会被分成chunk,并发地写入disk 1、2、3、4。
这样的好处一是可以利用LVM的条带化和多盘的并行能力提高写入性能。现在我们的写入性能比之前提高了20%以上,这是一个平均数,比较极致的提高会更多。第二,我们的四块盘既可以提供commitlog也可以提供sstable,我们就不需要额外的一块盘放commitlog,这样的性价比是最高的。另外,假设我们四块盘加起来的容量是80个G,它们对应的IOPS和一块80个G盘的IOPS是一样的,但是前者的价格会比后者低。通过这个方式,我们可以把整个Cassandra产品的价格降低。第三,我们底层所用的盘古可以提供比较极致的数据可靠性(9个9)。我们可以利用盘古的数据可靠性和LVM的条带化保证数据节点的数据可靠性,因为如果单块盘的数据可靠性不高时,LVM条带化是用不起来的。
除此之外,我们做了一些功能性的增强。
第一,我们支持全量和增量的备份恢复。原有的Cassandra并没有一个机制可以把增量的备份恢复做到同一的系统里面。我们现在能做到的是,假设原集群是三个节点,我们可以恢复到对应的三个节点。我们现在在云上的宗旨是恢复到对等节点。
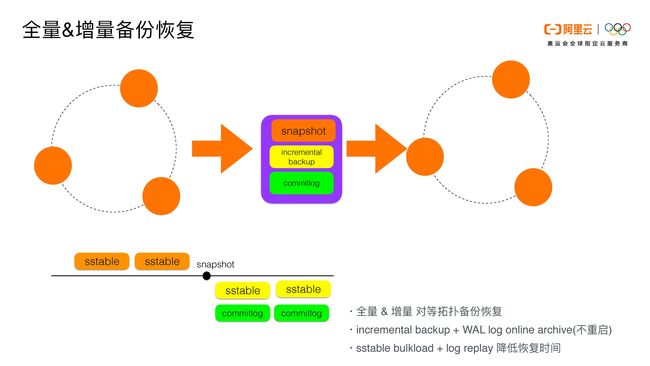
我们的备份和恢复分为两部分:全量的备份恢复和增量的备份恢复。
首先我们在图上有snapshot这个点,我们会对各个节点并发地做snapshot,做完snapshot我们会有一个全量的sstable。在打完snapshot这个时间点以后,我们会开始做增量的备份。增量的备份我们分两部分:一是incremental backup是社区已有的功能,我们在此基础上做了一个表级别的备份恢复的点。除此之外,我们还做了一个增量commitlog的数据备份恢复。
可能有的用户会问,增量的incremental backup和commitlog的数据其实是有重叠的,我们后面会对此做一些介绍,解释我们为什么这样做。
我们通过snapshot打完全量的快照以后,把每个节点的数据备份到阿里云的oss上面去。当用户选择恢复的时候,我们会对用户所有的sstable做对等拓扑的恢复,每个节点的token范围也是对等映射的。这样做的好处是可以不通过sstableloader的方式把sstable load进去,这样恢复的速度是最快的。我们只需要做一个对等拷贝,然后做一个单节点的nodetool refresh就可以了。
增量我们通过incremental backup及WAL log online archive来做。我们在云上做了这样的一个优化:每次从memtable flush下来的sstable会通过incremental backup产生hard link到对应的backups目录,同时扩容节点的时候,streaming生成的SSTable也会产生hard link。我们会把hard link对应的SSTable也备份。
除此之外,我们利用了Cassandra原有的archive功能,把每个节点写入的WAL log也做一个备份。当每个commitlog生成的时候,它都会把一个hard link到用户指定的地方。因为archive是需要重启集群和节点的,我们在这里做的一个优化使之无需重启。我们做了一个在线归档的功能,只要用户点击某个命令,开启incremental backup log的归档,我们会有对应的进程把log收到OSS上面去。因为我们的备份恢复是对等拓扑的,节点在恢复的时候都会对应到与它相关的token的节点上去。它恢复的时候可以做本节点的nodetool flush以及本节点的commitlog replay,并且这个replay是online replay。
这样的好处是备份恢复的时间是最短的。Incremental backup和commitlog的组合可以让恢复的时间是最短的,因为我们通过incremental backup的sstable筛选出需要恢复的WAL log/commitlog,然后做一个归档。这样的话可以避免log的replay的时间越来越多。
接下来我会介绍一下我们的数据迁移。
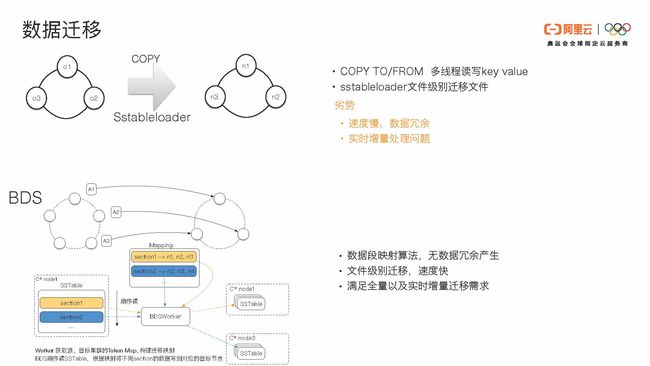
Cassandra原有的数据迁移分为COPY TO/FROM命令和文件级别的sstableloader两种。COPY TO/FROM是一个多线程读写key value的操作,当数据量比较大时,它的速度会比较慢。就sstableloader来说,O1、O2、O3节点上的数据都需要被load,load到新的集群时可能会有一些冗余。另外实时新增的数据可能处理得不会很融洽。
在这里,我们启动了阿里云的BDS服务。无论原集群和目标集群是对等或不对等拓扑,它们都可以通过BDS高效迁移。
原有的sstableloader方案中,原集群所有节点都需要进行一个类似于streaming的过程,并在目标集群进行一个拖数据的过程。原集群中节点o1的文件可能和目标集群中的节点n1、n2、n3都会有重叠。原集群o1中的文件复制到目标集群可能要有一个三副本的放大。当原集群有三个副本,目标集群也三个副本时,一份数据通过sstableloader可能会有九倍的放大。这会产生冗余。
当使用BDS,我们把原集群和目标集群做了数据范围的映射。原集群的primary range的数据我们只会迁移到目标集群的primary range,副本节点的数据会迁移到副本节点。我们的副本摆放策略默认使用SimpleStrategy,根据这个副本摆放策略我们做一个副本范围的一一映射。当某个sstable在目标集群上横跨了多个节点时,我们会对于这个sstable做一个切分,切分后需要把对应的数据复制到对应的节点上面去。这样可以避免数据的冗余。
除此之外,我们还做了文件级别的迁移,速度比较快。另外我们也支持增量数据的迁移,包括增量的commitlog和incremental backup。我们支持实时的增量数据的迁移需求,用户只需要通过我们的BDS服务,无需额外操作即可完成无缝迁移。
最后,我来介绍一下我们监控报警的大概模式。我们会分三个层面来介绍。
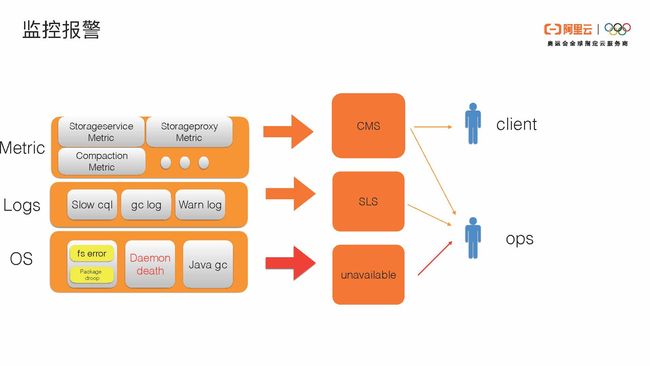
首先是OS操作系统层面。
因为Cassandra是share-nothing的架构,它是直接写本地的文件系统。对于本地的文件系统的error我们会做实时探测,对网络包package的异常处理我们也会做监控。在这里像file system error这样的相对比较重要的error,我们会通过unavailable这样的异常报给Ops服务。我们也会对Cassandra的daemon death进行实时监控,在Cassandra每一个进程的机制下面,我们都会有个单独的agent来发出system error,包括网络和内存的异常。另外Cassandra daemon的判活还有gc。关于gc,我们比较关注的是时间比较长的后续情况,超过500毫秒我们会通过发出unavailable异常报给Ops同学。
第二个层面是Logs层面异常的收集。
第一是slow cql,就是读的时候比较慢的cql,我们会收集。gc log是Cassandra自己的GCInspector的log,还有warn log比如large partition。这些我们会通过SLS收集,之后相关的报警也会告诉我们值班的同学,最上层是Cassandra自己的metric的信息。Metric信息我们会分两类进行处理。第一是展示给用户的Metric,比如容量、compaction等,是我们觉得用户会比较关心的,会通过CMS给用户。全量的80%的metric也会通过CMS链路报给我们自己的Ops同学。通过这种方式,我们可以对metric也设置一些报警。