Kibana: 运用Data Visualizer来分析CSV数据
在我之前的文章“运用Elastic Stack分析COVID-19数据并进行可视化分析”,我使用了Beats来导入COVID-19数据到Elasticsearch。在那篇文章中,我们使用了pipeline的processors来分析数据。在那篇文章中,我们也同时指出了我们可以使用Kibana所提供的Data Visualizer来分析我们的数据。在今天的教程中,我们来展示如何使用。
首先我们打开Kibana:
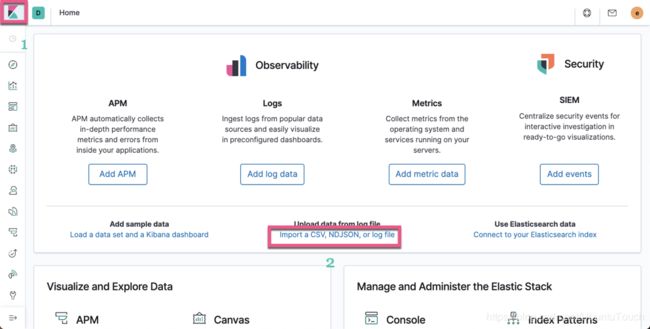
我们点击上面的Import a CSV, NDJSON, or log file:

点击Select or drag and drop a file:
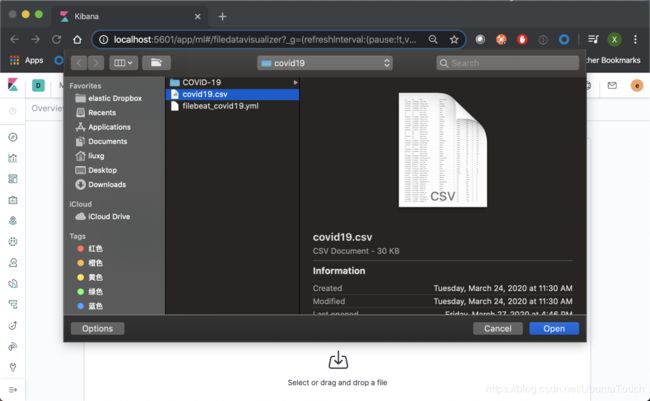
选择我们的CSV文档:
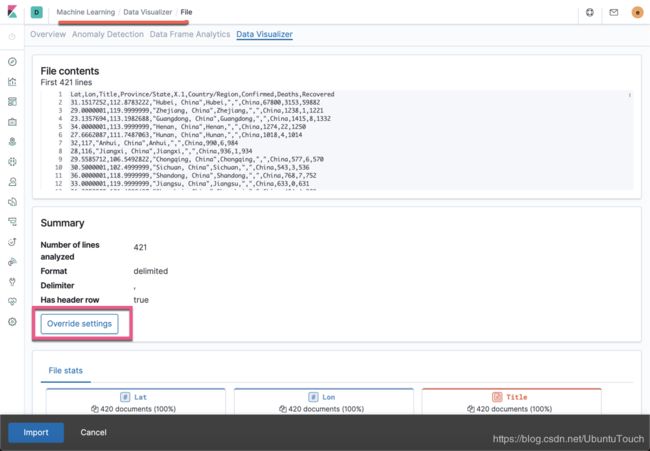
在上面我们可以看到被导入的所有的文档,也可以看到Elastic利用机器学习对数据的分析及统计情况:
我们点击上面页面中的Override settings,并修改相应的字段的名称:
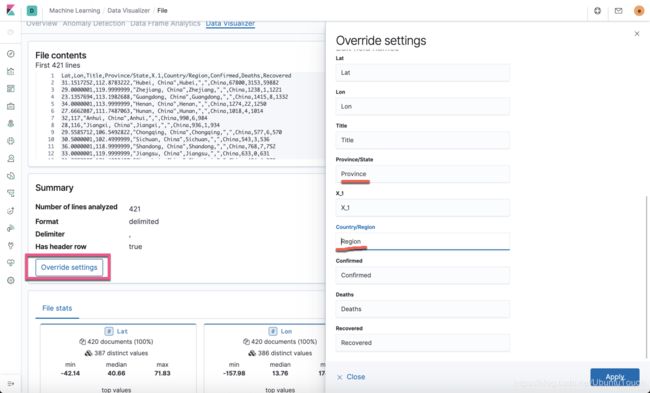
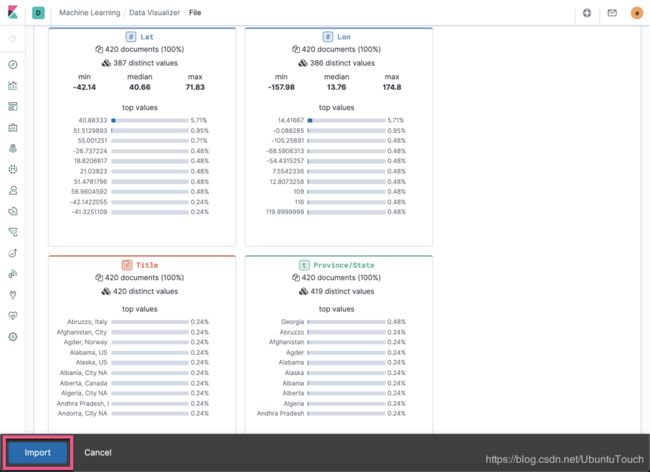
点击上面的import:

我们输入index name为covid,并点击Advanced
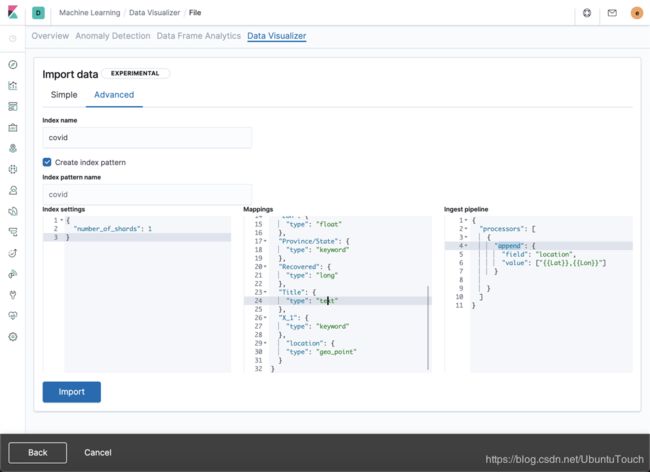
我们在Mappings里修改Lat及Lon的数据类型为float,及添加一个叫做location的字段。Mappings的内容如下:
{
"Confirmed": {
"type": "long"
},
"Region": {
"type": "keyword"
},
"Deaths": {
"type": "long"
},
"Lat": {
"type": "float"
},
"Lon": {
"type": "float"
},
"Province": {
"type": "keyword"
},
"Recovered": {
"type": "long"
},
"Title": {
"type": "text"
},
"X_1": {
"type": "keyword"
},
"location": {
"type": "geo_point"
}
}由于location是新增加的字段,那么我们需要ingest pipelines来对它进行处理:
{
"processors": [
{
"append": {
"field": "location",
"value": ["{{Lat}},{{Lon}}"]
}
}
]
}在上面我们可以看出来location的值为Lat及Lon两个字段的值组成的。
我们点击上面的Import按钮:
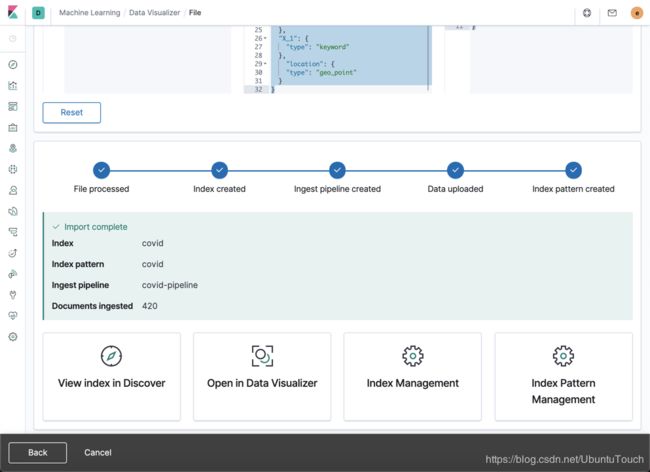
上面显示我们的数据已经被成功地导入进Elasticsearch。
我们可以在Kibana中查看我们的数据:
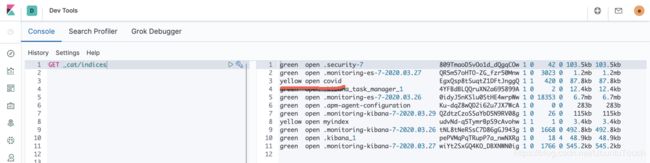
我们可以看见新生成的叫做covid的一个索引。我们再来查看一下它的mapping:
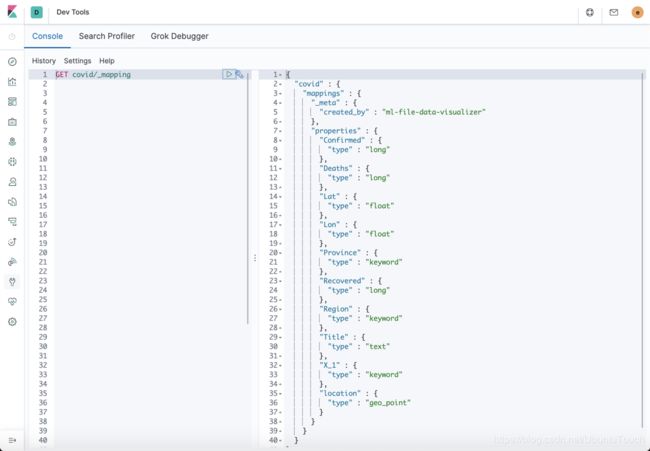
在上面我们可以看出来我们希望的索引的mapping是正确的。我们可以通过如下的指令来查看我们的数据:
GET covid/_search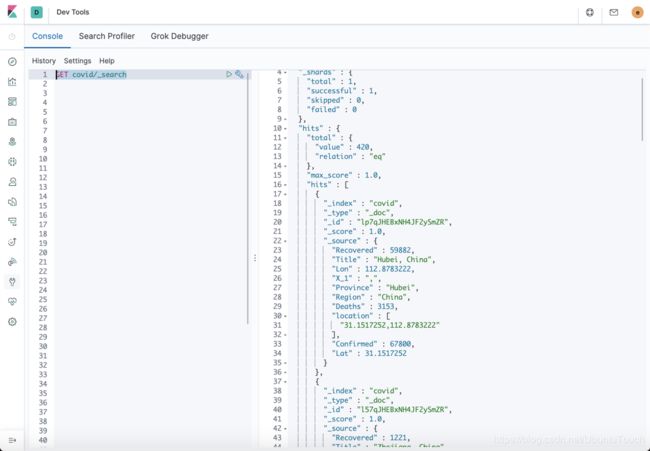
在Kibana的Discover中,我们也可以查看到所有的数据:
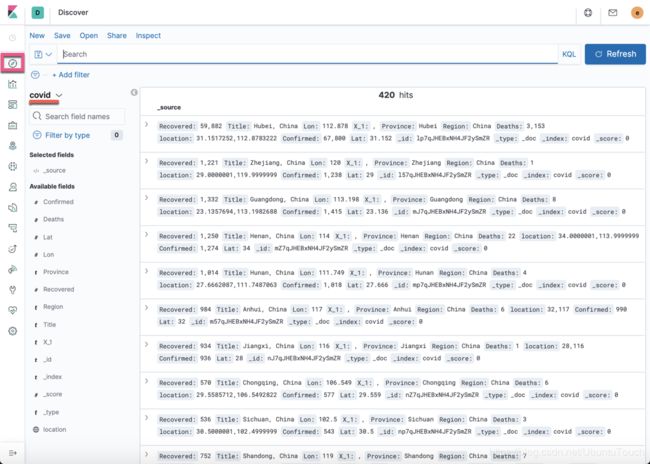
一旦数据进入到Elasticsearch中,我们可以仿照我们之前在文章“Beats:运用Elastic Stack分析COVID-19数据并进行可视化分析”介绍的方法来对数据进行展示和分析。这个练习就留给大家了。
更进一步
在上面的processor设计部分,我们只添加了一个location的字段。针对本次的设计我们是使用了其中的一天的csv文件。事实上,我们可以对每一天的数据都进行同样的处理。在这种情况下,我们需要多添加一个叫做@timestamp的字段,这样我们可以形成一个时间系列的索引数据,从而更好地分析每一天的数据。为此,我们需要修改我们的processor为:
{
"processors": [
{
{
"set": {
"field": "@timestamp",
"value": "2020-03-15"
}
},
"append": {
"field": "location",
"value": ["{{Lat}},{{Lon}}"]
}
}
]
}在上面,我们添加了一个叫做@timestamp的时间戳,表明当前数据的时间。这样我们就可以对这个时间系列的数据进行分析了。这个练习就留个大家来完成。