SparkSQL快速入门系列(6)

上一篇《SparkCore快速入门系列(5)》,下面给大家更新一篇SparkSQL入门级的讲解。
文章目录
- 第一章 Spark SQL概述
- 1.1 Spark SQL官方介绍
- 1.2 ●Spark SQL 的特点
- 1.3 SQL优缺点
- 1.4 Hive和SparkSQL
- 1.5 Spark SQL数据抽象
- 1.5.1 DataFrame
- 1.5.2 DataSet
- 1.5.3 RDD、DataFrame、DataSet的区别
- 第二章 Spark SQL初体验
- 2.1. 入口-SparkSession
- 2.2. 创建DataFrame
- 2.2.1. 创读取文本文件
- 2.2.2. 读取json文件
- 2.2.3. 读取parquet文件
- 2.3. 创建DataSet
- 2.4. 两种查询风格[先了解]
- 2.4.1. 准备工作
- 2.4.2. DSL风格
- 2.4.3. SQL风格
- 2.5. 总结
- 第三章 使用IDEA开发Spark SQL
- 3.1. 创建DataFrame/DataSet
- 3.1.1. 指定列名添加Schema
- 3.1.2. StructType指定Schema-了解
- 3.1.3. 反射推断Schema--掌握
- 3.2. 花式查询
- 3.3. 相互转化
- 3.4. Spark SQL完成WordCount
- 3.4.1. SQL风格
- 3.4.2. DSL风格
- 第四章 Spark SQL多数据源交互
- 4.1. 写数据
- 4.2. 读数据
- 4.3. 总结
- 第五章 Spark SQL自定义函数
- 5.1. 自定义函数分类
- 5.2. 自定义UDF
- 5.3. 自定义UDAF[了解]
- 第六章 扩展:开窗函数
- 6.1. 概述
- 6.2. 准备工作
- 6.3. 聚合开窗函数
- 6.4. 排序开窗函数
- 6.4.1. ROW_NUMBER顺序排序
- 6.4.2. RANK跳跃排序
- 6.4.3. DENSE_RANK连续排序
- 6.4.4. NTILE分组排名[了解]
- 第七章 Spark-On-Hive
- 7.1. 概述
- 7.2. Hive开启MetaStore服务
- 7.3. SparkSQL整合Hive MetaStore
- 7.4. 使用SparkSQL操作Hive表
第一章 Spark SQL概述
1.1 Spark SQL官方介绍
●官网
http://spark.apache.org/sql/
Spark SQL是Spark用来处理结构化数据的一个模块。
Spark SQL还提供了多种使用方式,包括DataFrames API和Datasets API。但无论是哪种API或者是编程语言,它们都是基于同样的执行引擎,因此你可以在不同的API之间随意切换,它们各有各的特点。
1.2 ●Spark SQL 的特点
1.易整合
可以使用java、scala、python、R等语言的API操作。
2.统一的数据访问
连接到任何数据源的方式相同。
3.兼容Hive
支持hiveHQL的语法。
兼容hive(元数据库、SQL语法、UDF、序列化、反序列化机制)
4.标准的数据连接
可以使用行业标准的JDBC或ODBC连接。
1.3 SQL优缺点
●SQL的优点
表达非常清晰, 比如说这段 SQL 明显就是为了查询三个字段,条件是查询年龄大于 10 岁的
难度低、易学习。
●SQL的缺点
复杂分析,SQL嵌套较多:试想一下3层嵌套的 SQL维护起来应该挺力不从心的吧
机器学习较难:试想一下如果使用SQL来实现机器学习算法也挺为难的吧
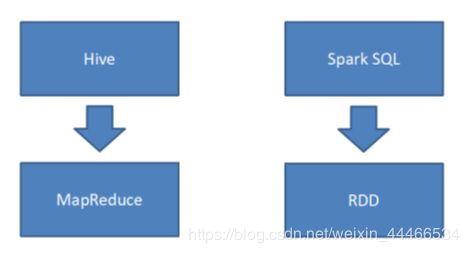
1.4 Hive和SparkSQL
Hive是将SQL转为MapReduce
SparkSQL可以理解成是将SQL解析成'RDD' + 优化再执行
1.5 Spark SQL数据抽象
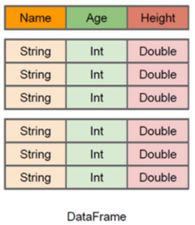
1.5.1 DataFrame
什么是DataFrame?
DataFrame是一种以RDD为基础的带有Schema元信息的分布式数据集,类似于传统数据库的二维表格 。
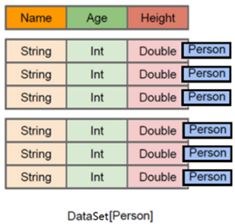
1.5.2 DataSet
什么是DataSet?
DataSet是保存了更多的描述信息,类型信息的分布式数据集。
与RDD相比,保存了更多的描述信息,概念上等同于关系型数据库中的二维表。
与DataFrame相比,保存了类型信息,是强类型的,提供了编译时类型检查,
调用Dataset的方法先会生成逻辑计划,然后被spark的优化器进行优化,最终生成物理计划,然后提交到集群中运行!
DataSet包含了DataFrame的功能,
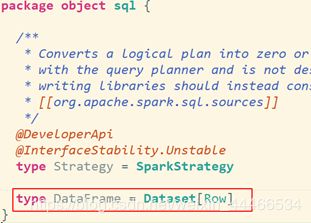
Spark2.0中两者统一,DataFrame表示为DataSet[Row],即DataSet的子集。
DataFrame其实就是Dateset[Row]
1.5.3 RDD、DataFrame、DataSet的区别
●结构图解
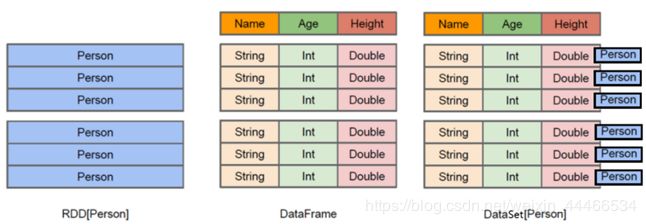

RDD[Person]
以Person为类型参数,但不了解 其内部结构。
DataFrame
提供了详细的结构信息schema列的名称和类型。这样看起来就像一张表了
DataSet[Person]
不光有schema信息,还有类型信息
第二章 Spark SQL初体验
2.1. 入口-SparkSession
●在spark2.0版本之前
SQLContext是创建DataFrame和执行SQL的入口
HiveContext通过hive sql语句操作hive表数据,兼容hive操作,hiveContext继承自SQLContext。
●在spark2.0之后
SparkSession 封装了SqlContext及HiveContext所有功能。通过SparkSession还可以获取到SparkConetxt。
SparkSession可以执行SparkSQL也可以执行HiveSQL.
2.2. 创建DataFrame
2.2.1. 创读取文本文件
1.在本地创建一个文件,有id、name、age三列,用空格分隔,然后上传到hdfs上
vim /root/person.txt
1 zhangsan 20
2 lisi 29
3 wangwu 25
4 zhaoliu 30
5 tianqi 35
6 kobe 40
上传数据文件到HDFS上:
hadoop fs -put /root/person.txt /
2.在spark shell执行下面命令,读取数据,将每一行的数据使用列分隔符分割
打开spark-shell
/export/servers/spark/bin/spark-shell
创建RDD
val lineRDD= sc.textFile("hdfs://node01:8020/person.txt").map(_.split(" "))
//RDD[Array[String]]
3.定义case class(相当于表的schema)
case class Person(id:Int, name:String, age:Int)
4.将RDD和case class关联
val personRDD = lineRDD.map(x => Person(x(0).toInt, x(1), x(2).toInt))
//RDD[Person]
5.将RDD转换成DataFrame
val personDF = personRDD.toDF
//DataFrame
6.查看数据和schema
personDF.show
+---+--------+---+
| id| name|age|
+---+--------+---+
| 1|zhangsan| 20|
| 2| lisi| 29|
| 3| wangwu| 25|
| 4| zhaoliu| 30|
| 5| tianqi| 35|
| 6| kobe| 40|
+---+--------+---+
personDF.printSchema
7.注册表
personDF.createOrReplaceTempView("t_person")
8.执行SQL
spark.sql("select id,name from t_person where id > 3").show
9.也可以通过SparkSession构建DataFrame
val dataFrame=spark.read.text("hdfs://node01:8020/person.txt")
dataFrame.show //注意:直接读取的文本文件没有完整schema信息
dataFrame.printSchema
2.2.2. 读取json文件
1.数据文件
使用spark安装包下的json文件
more /export/servers/spark/examples/src/main/resources/people.json
{"name":"Michael"}
{"name":"Andy", "age":30}
{"name":"Justin", "age":19}
2.在spark shell执行下面命令,读取数据
val jsonDF= spark.read.json("file:///export/servers/spark/examples/src/main/resources/people.json")
3.接下来就可以使用DataFrame的函数操作
jsonDF.show
//注意:直接读取json文件有schema信息,因为json文件本身含有Schema信息,SparkSQL可以自动解析
2.2.3. 读取parquet文件
1.数据文件
使用spark安装包下的parquet文件
more /export/servers/spark/examples/src/main/resources/users.parquet
2.在spark shell执行下面命令,读取数据
val parquetDF=spark.read.parquet("file:///export/servers/spark/examples/src/main/resources/users.parquet")
3.接下来就可以使用DataFrame的函数操作
parquetDF.show
//注意:直接读取parquet文件有schema信息,因为parquet文件中保存了列的信息
2.3. 创建DataSet
1.通过spark.createDataset创建Dataset
val fileRdd = sc.textFile("hdfs://node01:8020/person.txt") //RDD[String]
val ds1 = spark.createDataset(fileRdd) //DataSet[String]
ds1.show
2.通RDD.toDS方法生成DataSet
case class Person(name:String, age:Int)
val data = List(Person("zhangsan",20),Person("lisi",30)) //List[Person]
val dataRDD = sc.makeRDD(data)
val ds2 = dataRDD.toDS //Dataset[Person]
ds2.show
3.通过DataFrame.as[泛型]转化生成DataSet
case class Person(name:String, age:Long)
val jsonDF= spark.read.json("file:///export/servers/spark/examples/src/main/resources/people.json")
val jsonDS = jsonDF.as[Person] //DataSet[Person]
jsonDS.show
4.DataSet也可以注册成表进行查询
jsonDS.createOrReplaceTempView("t_person")
spark.sql("select * from t_person").show
2.4. 两种查询风格[先了解]
2.4.1. 准备工作
读取文件并转换为DataFrame或DataSet
val lineRDD= sc.textFile("hdfs://node01:8020/person.txt").map(_.split(" "))
case class Person(id:Int, name:String, age:Int)
val personRDD = lineRDD.map(x => Person(x(0).toInt, x(1), x(2).toInt))
val personDF = personRDD.toDF
personDF.show
//val personDS = personRDD.toDS
//personDS.show
2.4.2. DSL风格
SparkSQL提供了一个领域特定语言(DSL)以方便操作结构化数据
1.查看name字段的数据
personDF.select(personDF.col("name")).show
personDF.select(personDF("name")).show
personDF.select(col("name")).show
personDF.select("name").show
2.查看 name 和age字段数据
personDF.select("name", "age").show
3.查询所有的name和age,并将age+1
personDF.select(personDF.col("name"), personDF.col("age") + 1).show
personDF.select(personDF("name"), personDF("age") + 1).show
personDF.select(col("name"), col("age") + 1).show
personDF.select("name","age").show
//personDF.select("name", "age"+1).show
personDF.select($"name",$"age",$"age"+1).show
4.过滤age大于等于25的,使用filter方法过滤
personDF.filter(col("age") >= 25).show
personDF.filter($"age" >25).show
5.统计年龄大于30的人数
personDF.filter(col("age")>30).count()
personDF.filter($"age" >30).count()
6.按年龄进行分组并统计相同年龄的人数
personDF.groupBy("age").count().show
2.4.3. SQL风格
DataFrame的一个强大之处就是我们可以将它看作是一个关系型数据表,然后可以通过在程序中使用spark.sql() 来执行SQL查询,结果将作为一个DataFrame返回
如果想使用SQL风格的语法,需要将DataFrame注册成表,采用如下的方式:
personDF.createOrReplaceTempView("t_person")
spark.sql("select * from t_person").show
1.显示表的描述信息
spark.sql("desc t_person").show
2.查询年龄最大的前两名
spark.sql("select * from t_person order by age desc limit 2").show
3.查询年龄大于30的人的信息
spark.sql("select * from t_person where age > 30 ").show
4.使用SQL风格完成DSL中的需求
spark.sql("select name, age + 1 from t_person").show
spark.sql("select name, age from t_person where age > 25").show
spark.sql("select count(age) from t_person where age > 30").show
spark.sql("select age, count(age) from t_person group by age").show
2.5. 总结
1.DataFrame和DataSet都可以通过RDD来进行创建
2.也可以通过读取普通文本创建–注意:直接读取没有完整的约束,需要通过RDD+Schema
3.通过josn/parquet会有完整的约束
4.不管是DataFrame还是DataSet都可以注册成表,之后就可以使用SQL进行查询了! 也可以使用DSL!
第三章 使用IDEA开发Spark SQL
3.1. 创建DataFrame/DataSet
Spark会根据文件信息尝试着去推断DataFrame/DataSet的Schema,当然我们也可以手动指定,手动指定的方式有以下几种:
第1种:指定列名添加Schema
第2种:通过StructType指定Schema
第3种:编写样例类,利用反射机制推断Schema
3.1.1. 指定列名添加Schema
package cn.itcast.sql
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SparkSession}
object CreateDFDS {
def main(args: Array[String]): Unit = {
//1.创建SparkSession
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("SparkSQL").getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//2.读取文件
val fileRDD: RDD[String] = sc.textFile("D:\\data\\person.txt")
val linesRDD: RDD[Array[String]] = fileRDD.map(_.split(" "))
val rowRDD: RDD[(Int, String, Int)] = linesRDD.map(line =>(line(0).toInt,line(1),line(2).toInt))
//3.将RDD转成DF
//注意:RDD中原本没有toDF方法,新版本中要给它增加一个方法,可以使用隐式转换
import spark.implicits._
val personDF: DataFrame = rowRDD.toDF("id","name","age")
personDF.show(10)
personDF.printSchema()
sc.stop()
spark.stop()
}
}
3.1.2. StructType指定Schema-了解
package cn.itcast.sql
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types._
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
object CreateDFDS2 {
def main(args: Array[String]): Unit = {
//1.创建SparkSession
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("SparkSQL").getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//2.读取文件
val fileRDD: RDD[String] = sc.textFile("D:\\data\\person.txt")
val linesRDD: RDD[Array[String]] = fileRDD.map(_.split(" "))
val rowRDD: RDD[Row] = linesRDD.map(line =>Row(line(0).toInt,line(1),line(2).toInt))
//3.将RDD转成DF
//注意:RDD中原本没有toDF方法,新版本中要给它增加一个方法,可以使用隐式转换
//import spark.implicits._
val schema: StructType = StructType(Seq(
StructField("id", IntegerType, true),//允许为空
StructField("name", StringType, true),
StructField("age", IntegerType, true))
)
val personDF: DataFrame = spark.createDataFrame(rowRDD,schema)
personDF.show(10)
personDF.printSchema()
sc.stop()
spark.stop()
}
}
3.1.3. 反射推断Schema–掌握
package cn.itcast.sql
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SparkSession}
object CreateDFDS3 {
case class Person(id:Int,name:String,age:Int)
def main(args: Array[String]): Unit = {
//1.创建SparkSession
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("SparkSQL")
.getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//2.读取文件
val fileRDD: RDD[String] = sc.textFile("D:\\data\\person.txt")
val linesRDD: RDD[Array[String]] = fileRDD.map(_.split(" "))
val rowRDD: RDD[Person] = linesRDD.map(line =>Person(line(0).toInt,line(1),line(2).toInt))
//3.将RDD转成DF
//注意:RDD中原本没有toDF方法,新版本中要给它增加一个方法,可以使用隐式转换
import spark.implicits._
//注意:上面的rowRDD的泛型是Person,里面包含了Schema信息
//所以SparkSQL可以通过反射自动获取到并添加给DF
val personDF: DataFrame = rowRDD.toDF
personDF.show(10)
personDF.printSchema()
sc.stop()
spark.stop()
}
}
3.2. 花式查询
package cn.itcast.sql
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SparkSession}
object QueryDemo {
case class Person(id:Int,name:String,age:Int)
def main(args: Array[String]): Unit = {
//1.创建SparkSession
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("SparkSQL")
.getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//2.读取文件
val fileRDD: RDD[String] = sc.textFile("D:\\data\\person.txt")
val linesRDD: RDD[Array[String]] = fileRDD.map(_.split(" "))
val rowRDD: RDD[Person] = linesRDD.map(line =>Person(line(0).toInt,line(1),line(2).toInt))
//3.将RDD转成DF
//注意:RDD中原本没有toDF方法,新版本中要给它增加一个方法,可以使用隐式转换
import spark.implicits._
//注意:上面的rowRDD的泛型是Person,里面包含了Schema信息
//所以SparkSQL可以通过反射自动获取到并添加给DF
val personDF: DataFrame = rowRDD.toDF
personDF.show(10)
personDF.printSchema()
//=======================SQL方式查询=======================
//0.注册表
personDF.createOrReplaceTempView("t_person")
//1.查询所有数据
spark.sql("select * from t_person").show()
//2.查询age+1
spark.sql("select age,age+1 from t_person").show()
//3.查询age最大的两人
spark.sql("select name,age from t_person order by age desc limit 2").show()
//4.查询各个年龄的人数
spark.sql("select age,count(*) from t_person group by age").show()
//5.查询年龄大于30的
spark.sql("select * from t_person where age > 30").show()
//=======================DSL方式查询=======================
//1.查询所有数据
personDF.select("name","age")
//2.查询age+1
personDF.select($"name",$"age" + 1)
//3.查询age最大的两人
personDF.sort($"age".desc).show(2)
//4.查询各个年龄的人数
personDF.groupBy("age").count().show()
//5.查询年龄大于30的
personDF.filter($"age" > 30).show()
sc.stop()
spark.stop()
}
}
3.3. 相互转化
RDD、DF、DS之间的相互转换有很多(6种),但是我们实际操作就只有2类:
1)使用RDD算子操作
2)使用DSL/SQL对表操作
package cn.itcast.sql
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
object TransformDemo {
case class Person(id:Int,name:String,age:Int)
def main(args: Array[String]): Unit = {
//1.创建SparkSession
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("SparkSQL").getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//2.读取文件
val fileRDD: RDD[String] = sc.textFile("D:\\data\\person.txt")
val linesRDD: RDD[Array[String]] = fileRDD.map(_.split(" "))
val personRDD: RDD[Person] = linesRDD.map(line =>Person(line(0).toInt,line(1),line(2).toInt))
//3.将RDD转成DF
//注意:RDD中原本没有toDF方法,新版本中要给它增加一个方法,可以使用隐式转换
import spark.implicits._
//注意:上面的rowRDD的泛型是Person,里面包含了Schema信息
//所以SparkSQL可以通过反射自动获取到并添加给DF
//=========================相互转换======================
//1.RDD-->DF
val personDF: DataFrame = personRDD.toDF
//2.DF-->RDD
val rdd: RDD[Row] = personDF.rdd
//3.RDD-->DS
val DS: Dataset[Person] = personRDD.toDS()
//4.DS-->RDD
val rdd2: RDD[Person] = DS.rdd
//5.DF-->DS
val DS2: Dataset[Person] = personDF.as[Person]
//6.DS-->DF
val DF: DataFrame = DS2.toDF()
sc.stop()
spark.stop()
}
}
3.4. Spark SQL完成WordCount
3.4.1. SQL风格
package cn.itcast.sql
import org.apache.spark.SparkContext
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
object WordCount {
def main(args: Array[String]): Unit = {
//1.创建SparkSession
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("SparkSQL").getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//2.读取文件
val fileDF: DataFrame = spark.read.text("D:\\data\\words.txt")
val fileDS: Dataset[String] = spark.read.textFile("D:\\data\\words.txt")
//fileDF.show()
//fileDS.show()
//3.对每一行按照空格进行切分并压平
//fileDF.flatMap(_.split(" ")) //注意:错误,因为DF没有泛型,不知道_是String
import spark.implicits._
val wordDS: Dataset[String] = fileDS.flatMap(_.split(" "))//注意:正确,因为DS有泛型,知道_是String
//wordDS.show()
/*
+-----+
|value|
+-----+
|hello|
| me|
|hello|
| you|
...
*/
//4.对上面的数据进行WordCount
wordDS.createOrReplaceTempView("t_word")
val sql =
"""
|select value ,count(value) as count
|from t_word
|group by value
|order by count desc
""".stripMargin
spark.sql(sql).show()
sc.stop()
spark.stop()
}
}
3.4.2. DSL风格
package cn.itcast.sql
import org.apache.spark.SparkContext
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
object WordCount2 {
def main(args: Array[String]): Unit = {
//1.创建SparkSession
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("SparkSQL").getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//2.读取文件
val fileDF: DataFrame = spark.read.text("D:\\data\\words.txt")
val fileDS: Dataset[String] = spark.read.textFile("D:\\data\\words.txt")
//fileDF.show()
//fileDS.show()
//3.对每一行按照空格进行切分并压平
//fileDF.flatMap(_.split(" ")) //注意:错误,因为DF没有泛型,不知道_是String
import spark.implicits._
val wordDS: Dataset[String] = fileDS.flatMap(_.split(" "))//注意:正确,因为DS有泛型,知道_是String
//wordDS.show()
/*
+-----+
|value|
+-----+
|hello|
| me|
|hello|
| you|
...
*/
//4.对上面的数据进行WordCount
wordDS.groupBy("value").count().orderBy($"count".desc).show()
sc.stop()
spark.stop()
}
}
第四章 Spark SQL多数据源交互
Spark SQL可以与多种数据源交互,如普通文本、json、parquet、csv、MySQL等
1.写入不同数据源
2.读取不同数据源
4.1. 写数据
package cn.itcast.sql
import java.util.Properties
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
object WriterDataSourceDemo {
case class Person(id:Int,name:String,age:Int)
def main(args: Array[String]): Unit = {
//1.创建SparkSession
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("SparkSQL")
.getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//2.读取文件
val fileRDD: RDD[String] = sc.textFile("D:\\data\\person.txt")
val linesRDD: RDD[Array[String]] = fileRDD.map(_.split(" "))
val rowRDD: RDD[Person] = linesRDD.map(line =>Person(line(0).toInt,line(1),line(2).toInt))
//3.将RDD转成DF
//注意:RDD中原本没有toDF方法,新版本中要给它增加一个方法,可以使用隐式转换
import spark.implicits._
//注意:上面的rowRDD的泛型是Person,里面包含了Schema信息
//所以SparkSQL可以通过反射自动获取到并添加给DF
val personDF: DataFrame = rowRDD.toDF
//==================将DF写入到不同数据源===================
//Text data source supports only a single column, and you have 3 columns.;
//personDF.write.text("D:\\data\\output\\text")
personDF.write.json("D:\\data\\output\\json")
personDF.write.csv("D:\\data\\output\\csv")
personDF.write.parquet("D:\\data\\output\\parquet")
val prop = new Properties()
prop.setProperty("user","root")
prop.setProperty("password","root")
personDF.write.mode(SaveMode.Overwrite).jdbc(
"jdbc:mysql://localhost:3306/bigdata?characterEncoding=UTF-8","person",prop)
println("写入成功")
sc.stop()
spark.stop()
}
}
4.2. 读数据
package cn.itcast.sql
import java.util.Properties
import org.apache.spark.SparkContext
import org.apache.spark.sql.SparkSession
object ReadDataSourceDemo {
def main(args: Array[String]): Unit = {
//1.创建SparkSession
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("SparkSQL")
.getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//2.读取文件
spark.read.json("D:\\data\\output\\json").show()
spark.read.csv("D:\\data\\output\\csv").toDF("id","name","age").show()
spark.read.parquet("D:\\data\\output\\parquet").show()
val prop = new Properties()
prop.setProperty("user","root")
prop.setProperty("password","root")
spark.read.jdbc(
"jdbc:mysql://localhost:3306/bigdata?characterEncoding=UTF-8","person",prop).show()
sc.stop()
spark.stop()
}
}
4.3. 总结
1.SparkSQL写数据:
DataFrame/DataSet.write.json/csv/jdbc
2.SparkSQL读数据:
SparkSession.read.json/csv/text/jdbc/format
第五章 Spark SQL自定义函数
5.1. 自定义函数分类
类似于hive当中的自定义函数, spark同样可以使用自定义函数来实现新的功能。
spark中的自定义函数有如下3类
1.UDF(User-Defined-Function)
输入一行,输出一行
2.UDAF(User-Defined Aggregation Funcation)
输入多行,输出一行
3.UDTF(User-Defined Table-Generating Functions)
输入一行,输出多行
5.2. 自定义UDF
●需求
有udf.txt数据格式如下:
Hello
abc
study
small
通过自定义UDF函数将每一行数据转换成大写
select value,smallToBig(value) from t_word
●代码演示
package cn.itcast.sql
import org.apache.spark.SparkContext
import org.apache.spark.sql.{Dataset, SparkSession}
object UDFDemo {
def main(args: Array[String]): Unit = {
//1.创建SparkSession
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("SparkSQL").getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//2.读取文件
val fileDS: Dataset[String] = spark.read.textFile("D:\\data\\udf.txt")
fileDS.show()
/*
+----------+
| value|
+----------+
|helloworld|
| abc|
| study|
| smallWORD|
+----------+
*/
/*
将每一行数据转换成大写
select value,smallToBig(value) from t_word
*/
//注册一个函数名称为smallToBig,功能是传入一个String,返回一个大写的String
spark.udf.register("smallToBig",(str:String) => str.toUpperCase())
fileDS.createOrReplaceTempView("t_word")
//使用我们自己定义的函数
spark.sql("select value,smallToBig(value) from t_word").show()
/*
+----------+---------------------+
| value|UDF:smallToBig(value)|
+----------+---------------------+
|helloworld| HELLOWORLD|
| abc| ABC|
| study| STUDY|
| smallWORD| SMALLWORD|
+----------+---------------------+
*/
sc.stop()
spark.stop()
}
}
5.3. 自定义UDAF[了解]
●需求
有udaf.json数据内容如下
{"name":"Michael","salary":3000}
{"name":"Andy","salary":4500}
{"name":"Justin","salary":3500}
{"name":"Berta","salary":4000}
求取平均工资
●继承UserDefinedAggregateFunction方法重写说明
inputSchema:输入数据的类型
bufferSchema:产生中间结果的数据类型
dataType:最终返回的结果类型
deterministic:确保一致性,一般用true
initialize:指定初始值
update:每有一条数据参与运算就更新一下中间结果(update相当于在每一个分区中的运算)
merge:全局聚合(将每个分区的结果进行聚合)
evaluate:计算最终的结果
●代码演示
package cn.itcast.sql
import org.apache.spark.SparkContext
importorg.apache.spark.sql.expressions{MutableAggregationBuffer,UserDefinedAggregateFunction}
import org.apache.spark.sql.types._
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
object UDAFDemo {
def main(args: Array[String]): Unit = {
//1.获取sparkSession
val spark: SparkSession = SparkSession.builder().appName("SparkSQL").master("local[*]").getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//2.读取文件
val employeeDF: DataFrame = spark.read.json("D:\\data\\udaf.json")
//3.创建临时表
employeeDF.createOrReplaceTempView("t_employee")
//4.注册UDAF函数
spark.udf.register("myavg",new MyUDAF)
//5.使用自定义UDAF函数
spark.sql("select myavg(salary) from t_employee").show()
//6.使用内置的avg函数
spark.sql("select avg(salary) from t_employee").show()
}
}
class MyUDAF extends UserDefinedAggregateFunction{
//输入的数据类型的schema
override def inputSchema: StructType = {
StructType(StructField("input",LongType)::Nil)
}
//缓冲区数据类型schema,就是转换之后的数据的schema
override def bufferSchema: StructType = {
StructType(StructField("sum",LongType)::StructField("total",LongType)::Nil)
}
//返回值的数据类型
override def dataType: DataType = {
DoubleType
}
//确定是否相同的输入会有相同的输出
override def deterministic: Boolean = {
true
}
//初始化内部数据结构
override def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0) = 0L
buffer(1) = 0L
}
//更新数据内部结构,区内计算
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
//所有的金额相加
buffer(0) = buffer.getLong(0) + input.getLong(0)
//一共有多少条数据
buffer(1) = buffer.getLong(1) + 1
}
//来自不同分区的数据进行合并,全局合并
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1(0) =buffer1.getLong(0) + buffer2.getLong(0)
buffer1(1) = buffer1.getLong(1) + buffer2.getLong(1)
}
//计算输出数据值
override def evaluate(buffer: Row): Any = {
buffer.getLong(0).toDouble / buffer.getLong(1)
}
}
第六章 扩展:开窗函数
6.1. 概述
https://www.cnblogs.com/qiuting/p/7880500.html
●介绍
开窗函数的引入是为了既显示聚集前的数据,又显示聚集后的数据。即在每一行的最后一列添加聚合函数的结果。
开窗用于为行定义一个窗口(这里的窗口是指运算将要操作的行的集合),它对一组值进行操作,不需要使用 GROUP BY 子句对数据进行分组,能够在同一行中同时返回基础行的列和聚合列。
●聚合函数和开窗函数
聚合函数是将多行变成一行,count,avg…
开窗函数是将一行变成多行;
聚合函数如果要显示其他的列必须将列加入到group by中
开窗函数可以不使用group by,直接将所有信息显示出来
●开窗函数分类
1.聚合开窗函数
聚合函数(列) OVER(选项),这里的选项可以是PARTITION BY 子句,但不可以是 ORDER BY 子句。
2.排序开窗函数
排序函数(列) OVER(选项),这里的选项可以是ORDER BY 子句,也可以是 OVER(PARTITION BY 子句 ORDER BY 子句),但不可以是 PARTITION BY 子句。
6.2. 准备工作
/export/servers/spark/bin/spark-shell --master
spark://node01:7077,node02:7077
case class Score(name: String, clazz: Int, score: Int)
val scoreDF = spark.sparkContext.makeRDD(Array(
Score("a1", 1, 80),
Score("a2", 1, 78),
Score("a3", 1, 95),
Score("a4", 2, 74),
Score("a5", 2, 92),
Score("a6", 3, 99),
Score("a7", 3, 99),
Score("a8", 3, 45),
Score("a9", 3, 55),
Score("a10", 3, 78),
Score("a11", 3, 100))
).toDF("name", "class", "score")
scoreDF.createOrReplaceTempView("scores")
scoreDF.show()
+----+-----+-----+
|name|class|score|
+----+-----+-----+
| a1| 1| 80|
| a2| 1| 78|
| a3| 1| 95|
| a4| 2| 74|
| a5| 2| 92|
| a6| 3| 99|
| a7| 3| 99|
| a8| 3| 45|
| a9| 3| 55|
| a10| 3| 78|
| a11| 3| 100|
+----+-----+-----+
6.3. 聚合开窗函数
●示例1
OVER 关键字表示把聚合函数当成聚合开窗函数而不是聚合函数。
SQL标准允许将所有聚合函数用做聚合开窗函数。
spark.sql("select count(name) from scores").show
spark.sql("select name, class, score, count(name) over() name_count from scores").show
查询结果如下所示:
+----+-----+-----+----------+
|name|class|score|name_count|
+----+-----+-----+----------+
| a1| 1| 80| 11|
| a2| 1| 78| 11|
| a3| 1| 95| 11|
| a4| 2| 74| 11|
| a5| 2| 92| 11|
| a6| 3| 99| 11|
| a7| 3| 99| 11|
| a8| 3| 45| 11|
| a9| 3| 55| 11|
| a10| 3| 78| 11|
| a11| 3| 100| 11|
+----+-----+-----+----------+
●示例2
OVER 关键字后的括号中还可以添加选项用以改变进行聚合运算的窗口范围。
如果 OVER 关键字后的括号中的选项为空,则开窗函数会对结果集中的所有行进行聚合运算。
开窗函数的 OVER 关键字后括号中的可以使用 PARTITION BY 子句来定义行的分区来供进行聚合计算。与 GROUP BY 子句不同,PARTITION BY 子句创建的分区是独立于结果集的,创建的分区只是供进行聚合计算的,而且不同的开窗函数所创建的分区也不互相影响。
下面的 SQL 语句用于显示按照班级分组后每组的人数:
OVER(PARTITION BY class)表示对结果集按照 class 进行分区,并且计算当前行所属的组的聚合计算结果。
spark.sql(“select name, class, score, count(name) over(partition by class) name_count from scores”).show
查询结果如下所示:
+----+-----+-----+----------+
|name|class|score|name_count|
+----+-----+-----+----------+
| a1| 1| 80| 3|
| a2| 1| 78| 3|
| a3| 1| 95| 3|
| a6| 3| 99| 6|
| a7| 3| 99| 6|
| a8| 3| 45| 6|
| a9| 3| 55| 6|
| a10| 3| 78| 6|
| a11| 3| 100| 6|
| a4| 2| 74| 2|
| a5| 2| 92| 2|
+----+-----+-----+----------+
6.4. 排序开窗函数
6.4.1. ROW_NUMBER顺序排序
row_number() over(order by score) as rownum 表示按score 升序的方式来排序,并得出排序结果的序号
注意:
在排序开窗函数中使用 PARTITION BY 子句需要放置在ORDER BY 子句之前。
●示例1
spark.sql("select name, class, score, row_number() over(order by score) rank from scores").show()
+----+-----+-----+----+
|name|class|score|rank|
+----+-----+-----+----+
| a8| 3| 45| 1|
| a9| 3| 55| 2|
| a4| 2| 74| 3|
| a2| 1| 78| 4|
| a10| 3| 78| 5|
| a1| 1| 80| 6|
| a5| 2| 92| 7|
| a3| 1| 95| 8|
| a6| 3| 99| 9|
| a7| 3| 99| 10|
| a11| 3| 100| 11|
+----+-----+-----+----+
spark.sql("select name, class, score, row_number() over(partition by class order by score) rank from scores").show()
+----+-----+-----+----+
|name|class|score|rank|
+----+-----+-----+----+
| a2| 1| 78| 1|
| a1| 1| 80| 2|
| a3| 1| 95| 3|
| a8| 3| 45| 1|
| a9| 3| 55| 2|
| a10| 3| 78| 3|
| a6| 3| 99| 4|
| a7| 3| 99| 5|
| a11| 3| 100| 6|
| a4| 2| 74| 1|
| a5| 2| 92| 2|
+----+-----+-----+----+
6.4.2. RANK跳跃排序
rank() over(order by score) as rank表示按 score升序的方式来排序,并得出排序结果的排名号。
这个函数求出来的排名结果可以并列(并列第一/并列第二),并列排名之后的排名将是并列的排名加上并列数
简单说每个人只有一种排名,然后出现两个并列第一名的情况,这时候排在两个第一名后面的人将是第三名,也就是没有了第二名,但是有两个第一名
●示例2
spark.sql("select name, class, score, rank() over(order by score) rank from scores").show()
+----+-----+-----+----+
|name|class|score|rank|
+----+-----+-----+----+
| a8| 3| 45| 1|
| a9| 3| 55| 2|
| a4| 2| 74| 3|
| a10| 3| 78| 4|
| a2| 1| 78| 4|
| a1| 1| 80| 6|
| a5| 2| 92| 7|
| a3| 1| 95| 8|
| a6| 3| 99| 9|
| a7| 3| 99| 9|
| a11| 3| 100| 11|
+----+-----+-----+----+
spark.sql("select name, class, score, rank() over(partition by class order by score) rank from scores").show()
+----+-----+-----+----+
|name|class|score|rank|
+----+-----+-----+----+
| a2| 1| 78| 1|
| a1| 1| 80| 2|
| a3| 1| 95| 3|
| a8| 3| 45| 1|
| a9| 3| 55| 2|
| a10| 3| 78| 3|
| a6| 3| 99| 4|
| a7| 3| 99| 4|
| a11| 3| 100| 6|
| a4| 2| 74| 1|
| a5| 2| 92| 2|
+----+-----+-----+----+
6.4.3. DENSE_RANK连续排序
dense_rank() over(order by score) as dense_rank 表示按score 升序的方式来排序,并得出排序结果的排名号。
这个函数并列排名之后的排名是并列排名加1
简单说每个人只有一种排名,然后出现两个并列第一名的情况,这时候排在两个第一名后面的人将是第二名,也就是两个第一名,一个第二名
●示例3
spark.sql("select name, class, score, dense_rank() over(order by score) rank from scores").show()
+----+-----+-----+----+
|name|class|score|rank|
+----+-----+-----+----+
| a8| 3| 45| 1|
| a9| 3| 55| 2|
| a4| 2| 74| 3|
| a2| 1| 78| 4|
| a10| 3| 78| 4|
| a1| 1| 80| 5|
| a5| 2| 92| 6|
| a3| 1| 95| 7|
| a6| 3| 99| 8|
| a7| 3| 99| 8|
| a11| 3| 100| 9|
+----+-----+-----+----+
spark.sql("select name, class, score, dense_rank() over(partition by class order by score) rank from scores").show()
+----+-----+-----+----+
|name|class|score|rank|
+----+-----+-----+----+
| a2| 1| 78| 1|
| a1| 1| 80| 2|
| a3| 1| 95| 3|
| a8| 3| 45| 1|
| a9| 3| 55| 2|
| a10| 3| 78| 3|
| a6| 3| 99| 4|
| a7| 3| 99| 4|
| a11| 3| 100| 5|
| a4| 2| 74| 1|
| a5| 2| 92| 2|
+----+-----+-----+----+
6.4.4. NTILE分组排名[了解]
ntile(6) over(order by score)as ntile表示按 score 升序的方式来排序,然后 6 等分成 6 个组,并显示所在组的序号。
●示例4
spark.sql("select name, class, score, ntile(6) over(order by score) rank from scores").show()
+----+-----+-----+----+
|name|class|score|rank|
+----+-----+-----+----+
| a8| 3| 45| 1|
| a9| 3| 55| 1|
| a4| 2| 74| 2|
| a2| 1| 78| 2|
| a10| 3| 78| 3|
| a1| 1| 80| 3|
| a5| 2| 92| 4|
| a3| 1| 95| 4|
| a6| 3| 99| 5|
| a7| 3| 99| 5|
| a11| 3| 100| 6|
+----+-----+-----+----+
spark.sql("select name, class, score, ntile(6) over(partition by class order by score) rank from scores").show()
+----+-----+-----+----+
|name|class|score|rank|
+----+-----+-----+----+
| a2| 1| 78| 1|
| a1| 1| 80| 2|
| a3| 1| 95| 3|
| a8| 3| 45| 1|
| a9| 3| 55| 2|
| a10| 3| 78| 3|
| a6| 3| 99| 4|
| a7| 3| 99| 5|
| a11| 3| 100| 6|
| a4| 2| 74| 1|
| a5| 2| 92| 2|
+----+-----+-----+----+
第七章 Spark-On-Hive
7.1. 概述
●官网
http://spark.apache.org/docs/latest/sql-data-sources-hive-tables.html
Configuration of Hive is done by placing your hive-site.xml, core-site.xml (for security configuration), and hdfs-site.xml (for HDFS configuration) file in conf/.
●Hive查询流程及原理
执行HQL时,先到MySQL元数据库中查找描述信息,然后解析HQL并根据描述信息生成MR任务
Hive将SQL转成MapReduce执行速度慢
使用SparkSQL整合Hive其实就是让SparkSQL去加载Hive 的元数据库,然后通过SparkSQL执行引擎去操作Hive表内的数据
所以首先需要开启Hive的元数据库服务,让SparkSQL能够加载元数据
7.2. Hive开启MetaStore服务
1: 修改 hive/conf/hive-site.xml 新增如下配置
hive.metastore.warehouse.dir
/user/hive/warehouse
hive.metastore.local
false
hive.metastore.uris
thrift://node01:9083
2: 后台启动 Hive MetaStore服务
nohup /export/servers/hive/bin/hive --service metastore 2>&1 >> /var/log.log &
7.3. SparkSQL整合Hive MetaStore
Spark 有一个内置的 MateStore,使用 Derby 嵌入式数据库保存数据,但是这种方式不适合生产环境,因为这种模式同一时间只能有一个 SparkSession 使用,所以生产环境更推荐使用 Hive 的 MetaStore
SparkSQL 整合 Hive 的 MetaStore 主要思路就是要通过配置能够访问它, 并且能够使用 HDFS 保存 WareHouse,所以可以直接拷贝 Hadoop 和 Hive 的配置文件到 Spark 的配置目录
hive-site.xml 元数据仓库的位置等信息
core-site.xml 安全相关的配置
hdfs-site.xml HDFS 相关的配置
使用IDEA本地测试直接把以上配置文件放在resources目录即可
7.4. 使用SparkSQL操作Hive表
package cn.itcast.sql
import org.apache.spark.sql.SparkSession
object HiveSupport {
def main(args: Array[String]): Unit = {
//创建sparkSession
val spark = SparkSession
.builder()
.appName("HiveSupport")
.master("local[*]")
//.config("spark.sql.warehouse.dir", "hdfs://node01:8020/user/hive/warehouse")
//.config("hive.metastore.uris", "thrift://node01:9083")
.enableHiveSupport()//开启hive语法的支持
.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
//查看有哪些表
spark.sql("show tables").show()
//创建表
spark.sql("CREATE TABLE person (id int, name string, age int) row format delimited fields terminated by ' '")
//加载数据,数据为当前SparkDemo项目目录下的person.txt(和src平级)
spark.sql("LOAD DATA LOCAL INPATH 'SparkDemo/person.txt' INTO TABLE person")
//查询数据
spark.sql("select * from person ").show()
spark.stop()
}
}
SparkSQL入门就到这里了。大家仔细的跟着步骤去练习一下吧。
不懂的可以私信我哦!!!!
咱们下期Spark Streaming见咯!!!
