python+正则表达式爬取京东商品数据信息
爬取数据的方式有很多种,正则表达式,scrapy,从接口中爬取动态网页的数据…今天我们讲的是用正则表达式来爬取京东一个大米商品的具体信息。
正则表达式的优点:可以精准的爬取我们想要的数据信息
缺点:爬取的速度会很慢,时间就会变得很长,就容易被反爬虫,封ip
若想爬取大量数据的信息,就需要分为三部分进行
1:爬取一个大米商品的具体信息(也就是下图中的蓝色部分)
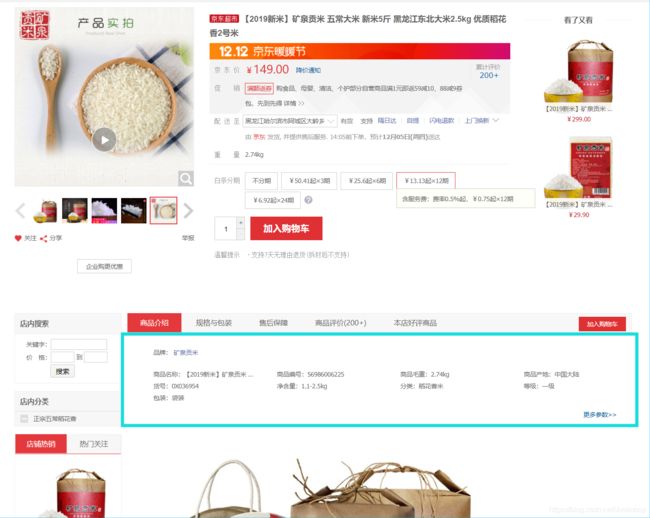
2:爬取一整个页面上的所有的商品的信息(也就是这个页面上所有的商品)
3:分页爬取(也就是下图中的蓝色部分,一共一百页)
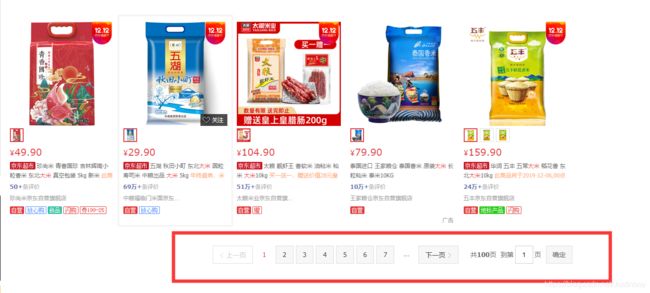
这次主要针对第一个爬取一个大米商品的具体信息进行讲解,剩下的两个爬取所有和分页爬取将到下一次进行讲解。
爬虫步骤:1:发送请求(request),获取响应内容。
2:解析内容
3:运行函数
下面我们就开始吧
我们爬取的网址是
https://item.jd.com/56986006225.html
一:导入相应的库
import re
from urllib import request
re库用来进行正则表达式匹配
request用来发送请求
库的安装都可以用以下指令来进行安装
pip install re
pip install urllib
二:建立一个spider类(因为我们的爬虫是在类里进行的),在类下写正则表达式
class Spider():
inform = '([\s\S]*?)'
dianming = 'target=\'_blank\'>([\s\S]*?)'
name ='商品名称:([\s\S]*?)\n'
bianhao = '商品编号:([\s\S]*?)\n'
maozhong = '商品毛重:([\s\S]*?)\n'
chaidi = '商品产地:([\s\S]*?)\n'
jinghanliang = '净含量:([\s\S]*?)\n'
fenlei = '分类:([\s\S]*?)\n'
baozhuang = '包装:([\s\S]*?)\n'
jiage = '([\s\S]*?)'
pinjia = '([\s\S]*?)'
正则表达式的匹配要学习的内容有很多,但是要说有没有一种正则表达式可以匹配数字或者文字。
([\s\S]*?)
其实是有的,只要在自己想匹配内容的位置上把内容删掉,然后换上([\s\S]*?)就可以了,这样就可以匹配到自己想要的内容。
【那么,正则表达式是怎么写的呢,有两种方式,第一种是在自己想爬的网站上按F12,就变成了这个样子
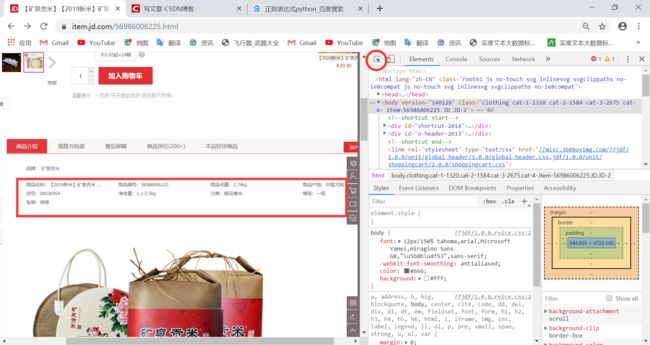
然后点上图的那个红色圆圈,就可以选取自己想爬取的内容,比如说我们想爬取商品名称,就选中商品名称就可以了,然后右边就会出现相应内容的源代码。
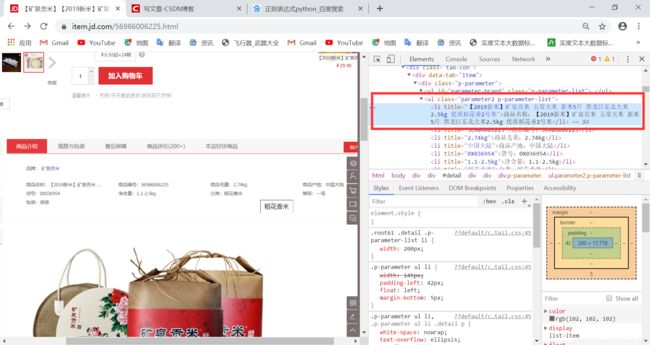
然后把内容去掉,换成正则表达式就可以了,**但是这样经常会匹配到空的字符串,因为网页上的源代码和发送给我们的源代码是不一样的,可能会有/n /r/n 等字符匹配不到。**第二种方式等到文章后面在讲,可以精确匹配到内容(在这里讲可能会有同学听不懂)】
三:发送请求(request),获取响应内容
def __fetch_content(self,url): #抓取网页地址
r = request.urlopen(url) #发送请求给浏览器
htmls = r.read() #读取浏览器的返回并赋值
htmls = str(htmls, encoding = 'gb18030') #把返回的html转换成字符串,并进行编码转换
return htmls #返回htmls
只要你想用正则表达式爬任何网站,这一段代码基本上就是不变的,起到了向网址发送请求的获取html的作用
四:解析内容
def __analysis(self,htmls):
infom_html = re.findall(Spider.inform,htmls)
for html in infom_html:
dianming_html = re.findall(Spider.dianming, html)
name_html = re.findall(Spider.name, html)
bianhao_html = re.findall(Spider.bianhao,html)
maozhong_html = re.findall(Spider.maozhong,html)
chaidi_html = re.findall(Spider.chaidi,html)
jinghualiang_html = re.findall(Spider.jinghanliang,html)
fenlei_html = re.findall(Spider.fenlei,html)
baozhuang_html = re.findall(Spider.baozhuang,html)
anchors = {'品牌':dianming_html,
'商品名称':name_html,
'商品编号':bianhao_html,
'商品毛重':maozhong_html,
'商品产地':chaidi_html,
'净含量':jinghualiang_html,
'分类':fenlei_html,
'包装':baozhuang_html}
print(anchors)
在这里我们用re库的findall来匹配内容,接受两个参数,一个是正则表达式(如Spider.inform…),另一个是在哪里匹配(如htmls)
在这里,infom_html的作用是在网页返回的htmls里缩小了匹配范围,更加容易匹配到内容
随后我定义了输出格式,anchors,以字典的形式输出来
五:运行函数
def go(self): #运行函数
url = 'https://item.jd.com/56986006225.html'
htmls = self.__fetch_content(url) #获取网址
anchors = self.__analysis(htmls) #用正则表达式匹配
这一步的作用是传递我们要爬的网址url,来运行以上定义的两个函数
六:实例化类对象,运行类
spider = Spider()
spider.go()
这里就不多说了,就是起到了运行class Spider 类的作用
全体代码:
import re
from urllib import request
class Spider():
inform = '([\s\S]*?)'
dianming = 'target=\'_blank\'>([\s\S]*?)'
name ='商品名称:([\s\S]*?)\n'
bianhao = '商品编号:([\s\S]*?)\n'
maozhong = '商品毛重:([\s\S]*?)\n'
chaidi = '商品产地:([\s\S]*?)\n'
jinghanliang = '净含量:([\s\S]*?)\n'
fenlei = '分类:([\s\S]*?)\n'
baozhuang = '包装:([\s\S]*?)\n'
jiage = '([\s\S]*?)'
pinjia = '([\s\S]*?)'
def __fetch_content(self,url):
r = request.urlopen(url)
htmls = r.read()
htmls = str(htmls,encoding='gb18030')
return htmls
def __analysis(self,htmls):
infom_html = re.findall(Spider.inform,htmls)
for html in infom_html:
dianming_html = re.findall(Spider.dianming, html)
name_html = re.findall(Spider.name, html)
bianhao_html = re.findall(Spider.bianhao,html)
maozhong_html = re.findall(Spider.maozhong,html)
chaidi_html = re.findall(Spider.chaidi,html)
jinghualiang_html = re.findall(Spider.jinghanliang,html)
fenlei_html = re.findall(Spider.fenlei,html)
baozhuang_html = re.findall(Spider.baozhuang,html)
anchors = {'品牌':dianming_html,
'商品名称':name_html,
'商品编号':bianhao_html,
'商品毛重':maozhong_html,
'商品产地':chaidi_html,
'净含量':jinghualiang_html,
'分类':fenlei_html,
'包装':baozhuang_html}
print(anchors)
def go(self): #运行函数
url = 'https://item.jd.com/56986006225.html'
htmls = self.__fetch_content(url) #获取网址输入
anchors = self.__analysis(htmls) #用正则表达式匹配
spider = Spider()
spider.go()
输出:

最后,讲解一下正则表达式匹配的第二种方式,
1:在def_analysis(self,htmls):里设置断点,然后进行调试
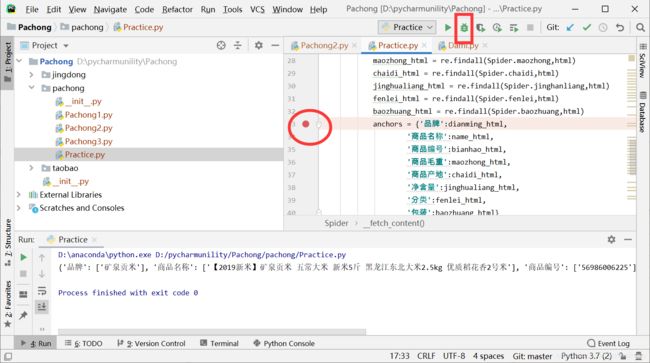
圆的为断点,长方形的为调试,等待一会后出现
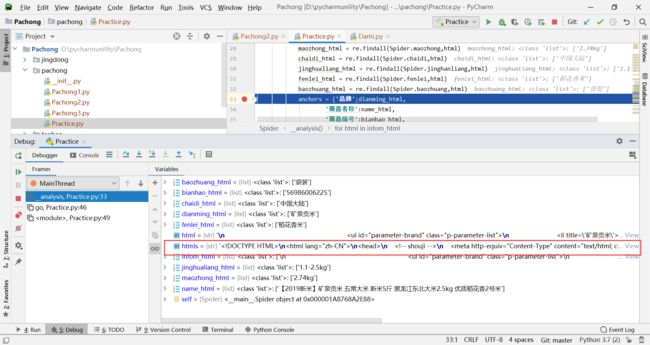
然后右边就会出现你匹配到的情况,在里面找到htmls,点view然后把里面的内容复制到一个word文档里,在里面进行匹配,一定可以匹配到自己想要的内容。
至此,爬取一个商品的具体信息已经结束了,接下来会讲解如何爬取一整个网页上的信息,和分页爬取。我们以后再见吧。