文章目录
- 0. 前言
- 1. 实现模型并行最直接的方式
- 2. 已有模型实现模型并行
- 3. 通过Pipelining加速
0. 前言
- 官方教程
- 目标:模型并行的单机多卡教程。
- 数据并行与模型并行的区别
- 数据并行:每个GPU上都有完整的模型,但将输入数据分为若干份,每个GPU处理不同的输入数据。
- 模型并行:每个GPU上都是模型的一部分,但都处理所有数据。
1. 实现模型并行最直接的方式
- 与实现单GPU的模型非常类似,
backward与torch.optim等不需要额外编程,自动会处理。
- 在定义模型的时候就手动指定数据所在的gpu位置。
import torch
import torch.nn as nn
import torch.optim as optim
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net1 = torch.nn.Linear(10, 10).to('cuda:0')
self.relu = torch.nn.ReLU()
self.net2 = torch.nn.Linear(10, 5).to('cuda:1')
def forward(self, x):
x = self.relu(self.net1(x.to('cuda:0')))
return self.net2(x.to('cuda:1'))
2. 已有模型实现模型并行
- 首先举了个ResNet的例子,其实也就是改写stage的GPU,重写前向过程。
from torchvision.models.resnet import ResNet, Bottleneck
num_classes = 1000
class ModelParallelResNet50(ResNet):
def __init__(self, *args, **kwargs):
super(ModelParallelResNet50, self).__init__(
Bottleneck, [3, 4, 6, 3], num_classes=num_classes, *args, **kwargs)
self.seq1 = nn.Sequential(
self.conv1,
self.bn1,
self.relu,
self.maxpool,
self.layer1,
self.layer2
).to('cuda:0')
self.seq2 = nn.Sequential(
self.layer3,
self.layer4,
self.avgpool,
).to('cuda:1')
self.fc.to('cuda:1')
def forward(self, x):
x = self.seq2(self.seq1(x).to('cuda:1'))
return self.fc(x.view(x.size(0), -1))
- 上面这种写法肯定会导致inference time增加,毕竟每次只在一个GPU上运行,还增加了数据转移时间。
- 下面的inference time的测试代码。
import torchvision.models as models
num_batches = 3
batch_size = 120
image_w = 128
image_h = 128
def train(model):
model.train(True)
loss_fn = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.001)
one_hot_indices = torch.LongTensor(batch_size) \
.random_(0, num_classes) \
.view(batch_size, 1)
for _ in range(num_batches):
inputs = torch.randn(batch_size, 3, image_w, image_h)
labels = torch.zeros(batch_size, num_classes) \
.scatter_(1, one_hot_indices, 1)
optimizer.zero_grad()
outputs = model(inputs.to('cuda:0'))
labels = labels.to(outputs.device)
loss_fn(outputs, labels).backward()
optimizer.step()
- 下面是两种方式的测试代码
- 主要就是通过
timeit来计算运行时间,还提供了画图结果。
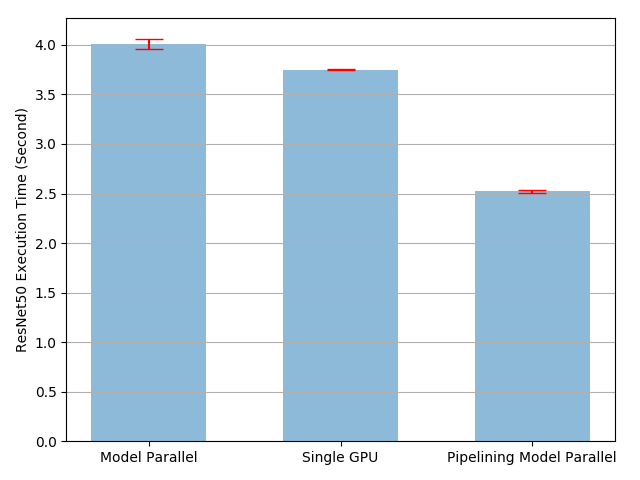
- 从结果上看,的确是没有使用模型并行速度更快一些。
num_repeat = 10
stmt = "train(model)"
setup = "model = ModelParallelResNet50()"
mp_run_times = timeit.repeat(
stmt, setup, number=1, repeat=num_repeat, globals=globals())
mp_mean, mp_std = np.mean(mp_run_times), np.std(mp_run_times)
setup = "import torchvision.models as models;" + \
"model = models.resnet50(num_classes=num_classes).to('cuda:0')"
rn_run_times = timeit.repeat(
stmt, setup, number=1, repeat=num_repeat, globals=globals())
rn_mean, rn_std = np.mean(rn_run_times), np.std(rn_run_times)
def plot(means, stds, labels, fig_name):
fig, ax = plt.subplots()
ax.bar(np.arange(len(means)), means, yerr=stds,
align='center', alpha=0.5, ecolor='red', capsize=10, width=0.6)
ax.set_ylabel('ResNet50 Execution Time (Second)')
ax.set_xticks(np.arange(len(means)))
ax.set_xticklabels(labels)
ax.yaxis.grid(True)
plt.tight_layout()
plt.savefig(fig_name)
plt.close(fig)
plot([mp_mean, rn_mean],
[mp_std, rn_std],
['Model Parallel', 'Single GPU'],
'mp_vs_rn.png')
3. 通过Pipelining加速
- 基本思路就是:
- PyTorch是通过异步调用CUDA操作的,不需要多线程/多进程就能实现并行。
- 将输入数据分为若干份。
- 在前向过程中分批处理。
- 实现方式:
- 改写Model实现pipeline。
- 这才两个GPU都这么麻烦了,不知道更多GPU是不是工作更多。
- 注意事项:
- 在streams间的设备间tensor copy操作是同步的,写代码的时候需要注意。
class PipelineParallelResNet50(ModelParallelResNet50):
def __init__(self, split_size=20, *args, **kwargs):
super(PipelineParallelResNet50, self).__init__(*args, **kwargs)
self.split_size = split_size
def forward(self, x):
splits = iter(x.split(self.split_size, dim=0))
s_next = next(splits)
s_prev = self.seq1(s_next).to('cuda:1')
ret = []
for s_next in splits:
s_prev = self.seq2(s_prev)
ret.append(self.fc(s_prev.view(s_prev.size(0), -1)))
s_prev = self.seq1(s_next).to('cuda:1')
s_prev = self.seq2(s_prev)
ret.append(self.fc(s_prev.view(s_prev.size(0), -1)))
return torch.cat(ret)
setup = "model = PipelineParallelResNet50()"
pp_run_times = timeit.repeat(
stmt, setup, number=1, repeat=num_repeat, globals=globals())
pp_mean, pp_std = np.mean(pp_run_times), np.std(pp_run_times)
plot([mp_mean, rn_mean, pp_mean],
[mp_std, rn_std, pp_std],
['Model Parallel', 'Single GPU', 'Pipelining Model Parallel'],
'mp_vs_rn_vs_pp.png')
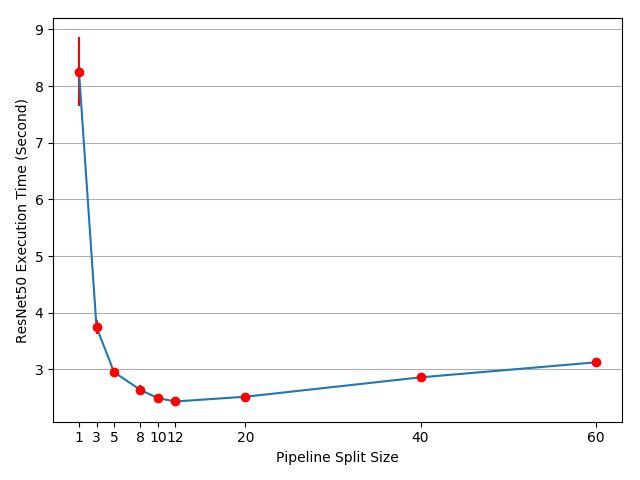
- 放个官方结果
- 关于
split_size 的选择
- 直观上看,数值小可以利用更多的cuda kernel,数值大则会最开始与最末尾的split之间的idle times增加。
- 下面的代码计算了split sizes 的最佳取值。
- 当前最佳实践是2.43ms,比单GPU的3.75ms提高了
(3.75/2.43-1)=54%,比理论上的100%还查了不少。
means = []
stds = []
split_sizes = [1, 3, 5, 8, 10, 12, 20, 40, 60]
for split_size in split_sizes:
setup = "model = PipelineParallelResNet50(split_size=%d)" % split_size
pp_run_times = timeit.repeat(
stmt, setup, number=1, repeat=num_repeat, globals=globals())
means.append(np.mean(pp_run_times))
stds.append(np.std(pp_run_times))
fig, ax = plt.subplots()
ax.plot(split_sizes, means)
ax.errorbar(split_sizes, means, yerr=stds, ecolor='red', fmt='ro')
ax.set_ylabel('ResNet50 Execution Time (Second)')
ax.set_xlabel('Pipeline Split Size')
ax.set_xticks(split_sizes)
ax.yaxis.grid(True)
plt.tight_layout()
plt.savefig("split_size_tradeoff.png")
plt.close(fig)