文章目录
- 0. 前言
- 1. 建议在看这个文当前,先看看下面三个文档
- 1.1. PyTorch Distributed Overview
- 1.2. DistributedDataParallel API documents
- 1.3. DistributedDataParallel notes
- 2. DataParallel 和 DistributdDataParalle 对比
- 3. 基本使用
- 4. 其他
- 4.1. 处理速度差异
- 4.2. 保存与加载模型
- 4.3. 通过DDP实现模型并行
0. 前言
- 官方教程
- 主要内容:通过 DistributedDataParallel 实现模型并行、数据并行
1. 建议在看这个文当前,先看看下面三个文档
1.1. PyTorch Distributed Overview
- 链接
- 其实就是 PyTorch Distributed Tutorials(1) Overview
1.2. DistributedDataParallel API documents
- 链接
- 其实就是
torch.nn.parallel.DistributedDataParallel 的API介绍。
- 概述:该类实现的是 module 级别的数据并行,输入数据中就有一个
module 对象。
- 实现思路应该就是,将输入数据拆分为若干份,分别送给若干GPU进行前向处理,反向操作时会获取每个设备上的梯度并求平均。
- 建议使用
DistributedDataParallel而不是DataParallel
- 前者使用多进程,后者使用多线程。
- 前者速度快很多。
- 后者可能有一些意想不到的问题。
- 在使用该类前,要求
torch.distributed 已经初始化了。
- 初始化就是调用
torch.distributed.init_process_group()
- 基本使用方法:
- 对于每个节点有N个GPU,那就需要建立N个进程,每个进程对应一个GPU。
- 对于每个进程,都需要进行以下操作
- 如果想要对节点的所有进程进行操作,可以使用
torch.distributed.lauch 或 torch.multiprocessing.spawn
torch.distributed.init_process_group(backend='nccl', world_size=4, init_method='...')
model = DistributedDataParallel(model, device_ids=[i], output_device=i)
1.3. DistributedDataParallel notes
- 链接
- 目标:介绍
torch.nn.parallel.DistributedDataParallel 的基本使用以及实现细节。
- 简单样例
- 以全连接为例,实现一个简单的数据并行模型。
- 实现了最基本的前向、反向、计算损失函数、通过优化器优化。
- 疑问:
dist.init_process_group 的作用是什么world_size 是什么example 函数中有个 rank,是哪来的,有什么作用
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDP
def example(rank, world_size):
dist.init_process_group("gloo", rank=rank, world_size=world_size)
model = nn.Linear(10, 10).to(rank)
ddp_model = DDP(model, device_ids=[rank])
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
outputs = ddp_model(torch.randn(20, 10).to(rank))
labels = torch.randn(20, 10).to(rank)
loss_fn(outputs, labels).backward()
optimizer.step()
def main():
world_size = 2
mp.spawn(example,
args=(world_size,),
nprocs=world_size,
join=True)
if __name__=="__main__":
main()
- 内部设计(其实我没看懂)
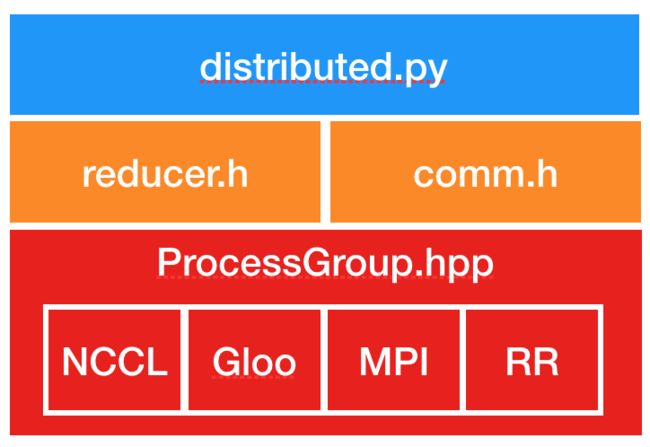
- 准备工作:DDP是通过c10d中的
ProcessGroup来实现通信的,所以必须在创建DDP前创建ProcessGroup对象。
- 创建过程:
- 通过本地module通过广播
state_dict,将模型复制到多个进程中(每个进程对应一个GPU)。
- 每个DDP进程创建一个
Reducer对象。
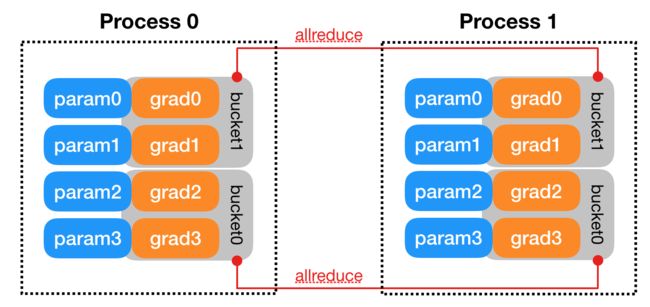
Reducer用来处理反向传播中的梯度同步。- 为了提高通信效率,
Reducer将参数的梯度组织起来,用 bucket 保存,每次reduce一个bucket。模型参数在bucket中保存的顺序差不多是 model.parameters() 的反序。
Reducer 中还有hook来处理反向传播,每个参数对应一个hook。
- 前向过程:看的不是很懂,unused parameters 到底是啥意思。
- 反向过程
- 反向过程是通过loss tensor的
backward() 方法引发的,不是DDP控制的。
- DDP 调用
backward() 主要就是通过在创建对象时注册的 autograd hooks 来实现。
- 当一个bucket的所有参数完成反向传播后,
Reducer 会异步调用该bucket对应的 allreduce 方法。当所有bucket的allreduce方法调用完后,梯度就会更新到 param.grad 变量中。
- 优化过程:从优化器的角度看,本质就是优化一个本地模型。所有DDP进程都拥有相同的初始状态,且每iteration都会得到相同的梯度,所以所有模型都保持了同步。
- 实现(源码层面)
2. DataParallel 和 DistributdDataParalle 对比
- 前者是单进程、多线程实现,只能用于一台机器。后者是多进程,可用于单台或多台机器。
- 前者的速度一般来说比后者慢。
- 前者不适用于模型并行,后者适用于模型并行。
3. 基本使用
- 要使用DDP模块,首先就要设置好 process groups
import os
import tempfile
import torch
import torch.distributed as dist
import torch.nn as nn
import torch.optim as optim
import torch.multiprocessing as mp
from torch.nn.parallel import DistributedDataParallel as DDP
def setup(rank, world_size):
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
dist.init_process_group("gloo", rank=rank, world_size=world_size)
def cleanup():
dist.destroy_process_group()
- 下面构建一个简单的模型,用过DDP包裹,导入一些随机生成的数据。
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net1 = nn.Linear(10, 10)
self.relu = nn.ReLU()
self.net2 = nn.Linear(10, 5)
def forward(self, x):
return self.net2(self.relu(self.net1(x)))
def demo_basic(rank, world_size):
print(f"Running basic DDP example on rank {rank}.")
setup(rank, world_size)
model = ToyModel().to(rank)
ddp_model = DDP(model, device_ids=[rank])
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
optimizer.zero_grad()
outputs = ddp_model(torch.randn(20, 10))
labels = torch.randn(20, 5).to(rank)
loss_fn(outputs, labels).backward()
optimizer.step()
cleanup()
def run_demo(demo_fn, world_size):
mp.spawn(demo_fn,
args=(world_size,),
nprocs=world_size,
join=True)
4. 其他
4.1. 处理速度差异
- DDP中,构造函数、前向、反向过程都是分布式过程中的同步点。
- 我们希望,不同的进程能大致利用相同的时间完成相同的任务,达到同步点。
- 但由于各种原因(网络延时、资源不够等),不同进程间不可避免地会出现处理速度不一致的问题。
- 为了解决这个问题,需要在
init_process_group 时设置足够大的 timeout 值。
4.2. 保存与加载模型
- DDP中保存模型的方法是:仅仅在一个进程中保存模型,然后将其加载到所有进程中,从而减少开销。
- 此时,需要确保在保存完成之前不要启动所有进程。
- 还需要提供适当的
map_location 参数,防止进程进入其他设备。
def demo_checkpoint(rank, world_size):
print(f"Running DDP checkpoint example on rank {rank}.")
setup(rank, world_size)
model = ToyModel().to(rank)
ddp_model = DDP(model, device_ids=[rank])
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
CHECKPOINT_PATH = tempfile.gettempdir() + "/model.checkpoint"
if rank == 0:
torch.save(ddp_model.state_dict(), CHECKPOINT_PATH)
dist.barrier()
map_location = {'cuda:%d' % 0: 'cuda:%d' % rank}
ddp_model.load_state_dict(
torch.load(CHECKPOINT_PATH, map_location=map_location))
optimizer.zero_grad()
outputs = ddp_model(torch.randn(20, 10))
labels = torch.randn(20, 5).to(rank)
loss_fn = nn.MSELoss()
loss_fn(outputs, labels).backward()
optimizer.step()
if rank == 0:
os.remove(CHECKPOINT_PATH)
cleanup()
4.3. 通过DDP实现模型并行
class ToyMpModel(nn.Module):
def __init__(self, dev0, dev1):
super(ToyMpModel, self).__init__()
self.dev0 = dev0
self.dev1 = dev1
self.net1 = torch.nn.Linear(10, 10).to(dev0)
self.relu = torch.nn.ReLU()
self.net2 = torch.nn.Linear(10, 5).to(dev1)
def forward(self, x):
x = x.to(self.dev0)
x = self.relu(self.net1(x))
x = x.to(self.dev1)
return self.net2(x)
- 实现模型并行
- 使用DDP修饰多GPU模型时,一般不会直接指定设备编号,一般会在forward()过程或在应用程序中设置。
- 在需要为一个搭模型训练大量数据时,特别有效。
def demo_model_parallel(rank, world_size):
print(f"Running DDP with model parallel example on rank {rank}.")
setup(rank, world_size)
dev0 = rank * 2
dev1 = rank * 2 + 1
mp_model = ToyMpModel(dev0, dev1)
ddp_mp_model = DDP(mp_model)
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_mp_model.parameters(), lr=0.001)
optimizer.zero_grad()
outputs = ddp_mp_model(torch.randn(20, 10))
labels = torch.randn(20, 5).to(dev1)
loss_fn(outputs, labels).backward()
optimizer.step()
cleanup()
if __name__ == "__main__":
n_gpus = torch.cuda.device_count()
if n_gpus < 8:
print(f"Requires at least 8 GPUs to run, but got {n_gpus}.")
else:
run_demo(demo_basic, 8)
run_demo(demo_checkpoint, 8)
run_demo(demo_model_parallel, 4)