文献阅读:Improving Multi-Task Deep Neural Networks via Knowledge Distillation for Natural Language Under
0.背景
机构:微软亚洲研究院 NLP 组与 SDRG(微软雷德蒙德语音对话研究组)
作者:Xiaodong Liu、Pengcheng He
发布地方:arxiv
面向任务:知识蒸馏
论文地址:https://arxiv.org/abs/1904.09482
论文代码:https://github.com/namisan/mt-dnn
0.摘要
尽管集成学习能够提升模型性能,且目前已被广泛地应用在NLU任务中,不过,集成学习通常由数十至数百种不同的神经网路模型组成,因此运算和部署成本相当高。本文通过知识蒸馏法,改善和提升多任务深度神经网路(Multi-Task Deep Neural Network, MT-DNN),打造出更稳固且通用的自然语言理解模型。其核心是将集成学习后(ensembled )的模型,通过知识蒸馏法,训练出单一个稳固且通用的MT-DNN。为每个task,训练一个由不同MT-DNNs所组成的集成学习模型(即teacher模型,该模型比任何单一模型更优秀),再通过多任务学习从多个集成学习模型(ensemble teachers)中蒸馏训练一个单一的MT-DNN(student模型)。蒸馏出来的MT-DNN在GLUE(9个任务)中的7个任务上超越了原始的MT-DNN,并将GLUE的benchmark(单模型)提升到83.7%(提升了1.5%),相对于BERT有3.2%提升。
1.介绍
本文将原始的知识蒸馏方法(Hinton et al., 2015) 拓展到了多任务学习上。在训练阶段,先选取一些tasks,每个task的训练集都是可训练的,即带有标注结果,输入 x x x,correct target记为 y y y。每个task,我们训练一个MT-DNN的集成学习模型(teacher),PS:此时的集成学习模型(teacher)是无法在线上部署的,所以我们在离线下进行蒸馏。对于训练集中的每个 x x x,集成学习模型(teacher)会有一系列的soft targets。比如,对于分类任务,集成学习模型输出的是其多个不同模型的在某个分类上的概率平均值。接着,在teacher模型的帮助下,通过多任务学习训练一个MT-DNN(student)模型。期间,联合使用了teacher模型提供的 soft targets和已知的correct targets。实验结果表明,知识蒸馏能够有效地将teachers所具有的泛化能力迁移到student模型。
2.MT-DNN
详情请见上一篇关于MT-DNN的介绍。
通过多任务学习训练MT-DNN之后,可以在下游具体任务上可以进行微调。
知识蒸馏
对多任务学习进行知识蒸馏的过程如下图所示:

首先,挑选数个有标注数据的tasks,对每个task,训练多个神经网络模型为一个集成学习模型,即teacher模型。每个神经网络模型都是Section 2中介绍的MT-DNN。每个神经网络模型都在特定任务的训练集上做微调,其共享层参数的初始化是MT-DNN通过多任务学习在GLUE数据集上预训练的结果,如Algorithm 1所示:

task-specific输出层的参数是随机初始化的。
对于每个task中的每个训练样本,teacher产生一个soft targets集合。以文本分类为例,一个神经网络模型通常使用softmax层生成各个分类的概率值,如公式1所示:
P r ( c ∣ X ) = s o f t m a x ( W t ⋅ x ) P_r (c|X)=softmax(\mathbf W_t \cdot \mathbf x) Pr(c∣X)=softmax(Wt⋅x)
集成学习模型中第k个单模型的分类结果记为 Q k Q^k Qk,teacher模型通过对各个网络模型的分类概率值进行平均,产生的soft targets:
Q = a v g ( [ Q 1 , Q 2 , . . . , Q K ] ) Q=avg([Q^1,Q^2,...,Q^K]) Q=avg([Q1,Q2,...,QK])
我们的目标是采用一个student模型来近似teacher模型,student模型对于相同任务的softmax输出 P r ( c ∣ X ) P_r(c|X) Pr(c∣X)(如方程1所示),因此采用标准的交叉熵损失:
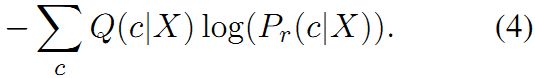
注意:上述的损失函数与论文中的Eq.2的差别在于前者使用的是soft targets Q ( c ∣ X ) Q(c|X) Q(c∣X),而后者使用的是hard correct target(即0-1分类器)。
Eq.2如下所示:

Hinton et al. (2015)曾指出,使用teacher的soft targets在将其泛化能力迁移到student模型中是至关重要的。teacher所产生的labels的相对概率值已经包含了teacher该如何泛化的信息。例如,句子“I really enjoyed the conversation with Tom”中的情感被分类器视为负向情感的概率很低,但是句子“Tom
and I had an interesting conversation”也可能是正向也有可能是负向,这主要取决于其上下文(如果上下文可用)。这就导致teacher的soft targets的熵较高。这种情况下,每个训练样本的soft targets能够比hard targets提供更多信息,同时在训练样本之间梯度的方差更低。基于teacher所产生的soft targets,进一步优化student模型,我们所期望的是student是能够学会teacher的泛化能力。在本文中,每个task-specific的teacher是其所组成的各个模型的均值,所以具有较好的泛化能力。我们所希望的是单个MT-DNN(student)在test data能够比vanilla MT-DNN(该模型在同样的训练集上以常规方式训练)表现更好。
此外,我们还发现当correct targets已知,联合soft和hard targets训练一个蒸馏模型可以以显著提升性能。本文为每个task定义了一个带权重的损失函数,其权重是在Eq.2 和Eq.4之间做均衡。Eq.2是correct targets的交叉熵损失,Eq.4是soft targets的交叉熵损失。Hinton et al. (2015) 建议第一个损失项的权重取低一些,但是在本文的实验中,我们没有观察到对这两个损失项分别使用不同的权重有任何显著差异。
最后,对给定的多任务训练集的soft targets,student模型可以通过Algorithm 1中的流程进行多任务学习。有所不同的是,task t t t有一个teacher,在Algorithm 1中的Line 3中的task-specific 损失是2个目标函数的均值。其中一个是correct targets,另一个是teacher所产生的soft targets。
实验
每个task都需要从多个不同的模型中集成出一个teacher,我们先训练6个MT-DNN单模型,每个MT-DNN都是以Csee/Uncased BERT模型进行初始化的;不同MT-DNN之间dropout rate不同,在 0.1 , 0.2 , 0.3 {0.1,0.2,0.3} 0.1,0.2,0.3中选择;共享层上的其他超参数参数与之前提到的一致。在训练结束后,根据在MNLI 和 RTE development datasets上的表现,选出3个最优模型。最后,在4个task数据集:MNLI, QQP, RTE and QNLI 上微调出4个集成学习模型。即每个task的集成学习模型都是由3个MT-DNN组成。每个teacher对其特定的任务根据 Q = a v g ( [ Q 1 , Q 2 , . . . , Q K ] ) Q=avg([Q^1,Q^2,...,Q^K]) Q=avg([Q1,Q2,...,QK]) 产生soft stargets。本文这里训练teachers的仅选择GLUE(有9个任务)中的4个任务,研究 M T − D N N K D \rm MT-DNN_{KD} MT−DNNKD的泛化能力,即在有/无teacher下的性能。
本文实验过程采用的对比模型(即baseline):
B E R T L A R G E \rm BERT_{LARGE} BERTLARGE : 就是Devlin et al. (2018)中的 l a r g e − B E R T large-BERT large−BERT。 B E R T L A R G E BERT_{LARGE} BERTLARGE在每个GLUE任务的dev set上进行微调,以获得最佳性能。
M T − D N N \rm MT-DNN MT−DNN : 即Section 2 和Liu et al. (2019)所介绍的MT-DNN。采用预训练的 B E R T L A R G E BERT_{LARGE} BERTLARGE初始化共享层,再利用GLUE的多任务数据训练共享层参数。最后,使用GLUE中的每个task的数据集进行整体微调。
M T − D N N K D \rm MT-DNN_{KD} MT−DNNKD : 是Section 3中所介绍的对于MT-DNN进行知识蒸馏后的模型。 M T − D N N K D \rm MT-DNN_{KD} MT−DNNKD与MT-DNN在架构上相同,但是前者的训练受助于4个teachers(即4个task对应集成学习模型)。 M T − D N N K D \rm MT-DNN_{KD} MT−DNNKD的优化是对多个tasks的目标函数,每个task的目标函数又由hard correct targets和soft targets组成。再通过多任务学习对teachers进行知识蒸馏,得到student。再对 M T − D N N K D \rm MT-DNN_{KD} MT−DNNKD在每个task的数据集上进行微调,最后在blind test data上对GLUE上各个task的预测结果进行评估。
在GLUE test set上的实验结果:
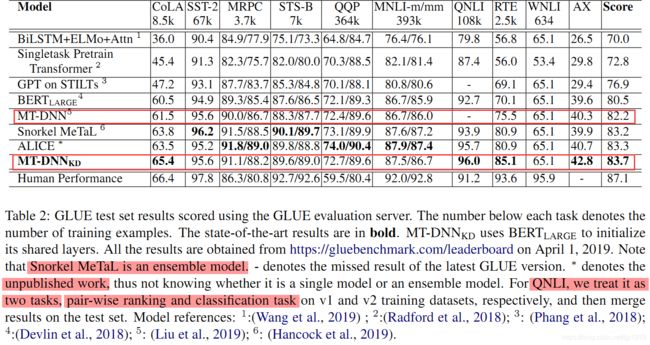
从table 2也可以看出, M T − D N N K D \rm MT-DNN_{KD} MT−DNNKD不仅仅在整体score上优于MT-DNN,还体现在GLUE中的7个任务。这还包括了没有teacher的task。

上述结果表明基于多任务的知识蒸馏是提升模型性能上是有效的,包括有teacher的task和没有teacher的task。同时在少样本下性能提升更显著。
消融研究

蓝色部分表示其不作为teacher。从中可以看出,基于多任务学习的知识蒸馏,在是否有teacher下都能够有效提升模型,同时在少训练数据下,优势越明显。MRPC, CoLa, SST-2, STS-B对应的集成学习模型在训练 M T − D N N K D \rm MT-DNN_{KD} MT−DNNKD的时候是没有teacher的,其结果表明基于多任务的知识蒸馏在没有teacher下也是能够提升模型性能。
总结
本文将知识蒸馏拓展到多任务学习以训练MT-DNN,从而提升其自然语言理解的能力。实验结果也表明知识蒸馏能够将集成学习模型的能力迁移到单模型(即单MT-DNN模型)。在GLUE数据集上,蒸馏出来的MT-DNN在7个任务中刷新了记录,其中包括没有使用teacher的多任务蒸馏模型。最终将GLUE benchmark(单模型)的score提升到83.7%。
未来方向:
(1)soft targets和hard correct targets的联合方式
(2)在无标注数据上使用teacher模型预测soft targets,再用该结果训练一个更好的student模型。从概念上,与半监督学习类似
(3)除了将复杂模型蒸馏为简单模型,知识蒸馏还能够在忽略模型复杂度下提升性能。在机器学习的场景下,如自学习(self-learning),其teacher和student都是相同模型。