美国人口普查数据预测收入sklearn算法汇总2: 特征编码, 特征选择, 降维, 递归特征消除
接<美国人口普查数据预测收入sklearn算法汇总1: 了解数据以及数据预处理>
六. 对特征进行编码
- pd.get_dummies()
one_hot_cols = dataset_bin.columns.drop('predclass')
dataset_bin_enc = pd.get_dummies(dataset_bin, columns=one_hot_cols)
print(dataset_bin_enc.shape)
dataset_bin_enc.head()
(48842, 105)

-
pd.factorize()
目的: 去掉NaN值, 便于数据编码
dataset_con_test = dataset_con
dataset_con_test['workclass'] = dataset_con['workclass'].factorize()[0]
dataset_con_test['occupation'] = dataset_con['occupation'].factorize()[0]
dataset_con_test['country'] = dataset_con['country'].factorize()[0]
dataset_con_test[dataset_con_test['workclass']==-1]
- factorize将类别映射为数字编码,跟pd.categorical()效果相似.
- 返回tuple(元组),第一个元素是array数字;第二个元素是Index类型,没有重复。
- factorize将NaN值映射为-1
from sklearn.preprocessing import LabelEncoder
# encoder_cols = dataset_con_test.columns
# for feature in encoder_cols:
# dataset_con_test[feature] = LabelEncoder().fit_transform(dataset_con_test[feature])
# dataset_con_test.head()
dataset_con_enc = dataset_con_test.apply(LabelEncoder().fit_transform)
dataset_con_enc.head()

七. 特征选择
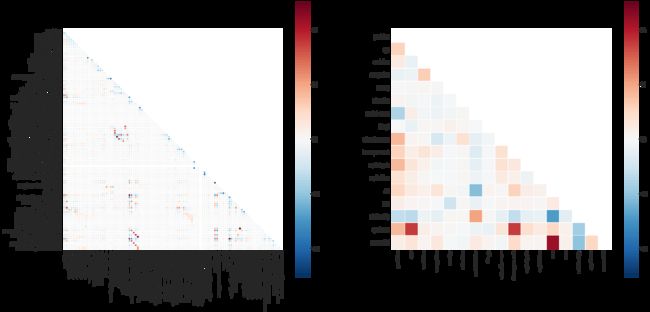
- 7.1 特征相关性
plt.figure(figsize = (30,14))
plt.subplot(1,2,1)
mask = np.zeros_like(dataset_bin_enc.corr(),dtype=np.bool)
mask[np.triu_indices_from(mask)] = True
sns.heatmap(dataset_bin_enc.corr(),vmin=-1,vmax=1,square=True,mask=mask,
cmap=sns.color_palette('RdBu_r', 100), linewidth=0.5)
plt.subplot(1,2,2)
mask = np.zeros_like(dataset_con_enc.corr(),dtype=np.bool)
mask[np.triu_indices_from(mask)] = True
sns.heatmap(dataset_con_enc.corr(),vmin=-1,vmax=1,square=True,mask=mask,
cmap=sns.color_palette('RdBu_r', 100), linewidth=0.5)
- 7.2 特征重要性
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier()
rfc.fit(dataset_con_enc.drop('predclass', axis=1), dataset_con_enc['predclass'])
importance = rfc.feature_importances_
importance = pd.DataFrame(importance, index=dataset_con_enc.drop('predclass',axis=1).columns, columns=['Importance'])
importance = importance.sort_values(by='Importance',ascending=False)
importance.plot(kind='barh',figsize=(20,len(importance)/1.5))

cumulative_importances = np.cumsum(importance['Importance'])
plt.figure(figsize = (20, 6))
plt.plot(list(range(len(importance.index))), cumulative_importances.values, 'b-')
plt.hlines(y=0.95, xmin=0, xmax=importance.shape[0], color='r', linestyles='dashed')
plt.xticks(list(range(len(importance.index))), importance.index, rotation=25)
plt.xlabel('Feature')
plt.ylabel('Cumulative Importance')
plt.title('Cumulative Importances')

print('Number of features for 95% importance:',np.where(cumulative_importances>0.95)[0][0]+1)
Number of features for 95% importance: 12
-
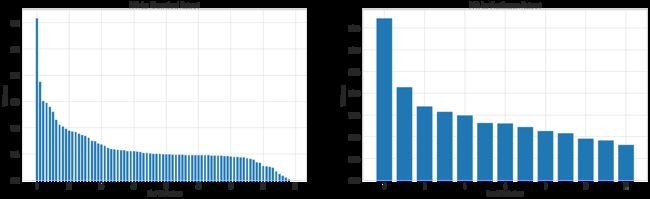
7.3 PCA降维
涉及参数:
- n_components:这个参数可以帮我们指定希望PCA降维后的特征维度数目。最常用的做法是直接指定降维到的维度数目,此时n_components是一个大于等于1的整数。当然,我们也可以指定主成分的方差和所占的最小比例阈值,让PCA类自己去根据样本特征方差来决定降维到的维度数,此时n_components是一个(0,1]之间的数
- whiten :判断是否进行白化。所谓白化,就是对降维后的数据的每个特征进行归一化,让方差都为1.对于PCA降维本身来说,一般不需要白化。如果你PCA降维后有后续的数据处理动作,可以考虑白化。默认值是False,即不进行白化。
- 除了这些输入参数外,有两个PCA类的成员值得关注。第一个是explained_variance_,它代表降维后的各主成分的方差值。方差值越大,则说明越是重要的主成分。第二个是explained_variance_ratio_,它代表降维后的各主成分的方差值占总方差值的比例,这个比例越大,则越是重要的主成分。
from sklearn import preprocessing
from sklearn.decomposition import PCA
X_bin = preprocessing.StandardScaler().fit_transform(dataset_bin_enc.drop('predclass',axis=1))
pca_bin = PCA(n_components = 80)
fit_bin = pca_bin.fit(X_bin)
X_con = preprocessing.StandardScaler().fit_transform(dataset_con_enc.drop('predclass',axis=1))
pca_con = PCA(n_components = 13)
fit_con = pca_con.fit(X_con)
plt.figure(figsize = (25, 7))
plt.subplot(1,2,1)
plt.bar(range(0,fit_bin.explained_variance_ratio_.size),fit_bin.explained_variance_ratio_)
plt.xlabel('Bin PCA Feature'); plt.ylabel('Variance'); plt.title('PCA for Discretised Dataset')
plt.subplot(1,2,2)
plt.bar(range(0,fit_con.explained_variance_ratio_.size),fit_con.explained_variance_ratio_)
plt.xlabel('Con PCA Feature'); plt.ylabel('Variance'); plt.title('PCA for Continuous Dataset')
y = dataset_con_enc['predclass']
target_names = ['<$50K','>$50K']
colors = ['navy', 'darkorange']
linewidth = 2
alpha = 0.3
from mpl_toolkits.mplot3d import Axes3D
plt.figure(figsize = (20,8))
plt.subplot(1, 2, 1)
pca = PCA(n_components = 2)
X_2 = pca.fit_transform(X_con)
for color,i,target_name in zip(colors, [0,1], target_names):
plt.scatter(X_2[y==i,0], X_2[y==i,1], color=color, alpha=alpha, lw=linewidth, label=target_name)
plt.legend(loc = 'best', shadow=False, scatterpoints=1)
plt.title('First two PCA directions')
ax = plt.subplot(1, 2, 2, projection='3d')
pca = PCA(n_components = 3)
X_3 = pca.fit_transform(X_con)
for color,i,target_name in zip(colors, [0,1], target_names):
ax.scatter(X_3[y==i,0], X_3[y==i,1], X_3[y==i,2], color=color, alpha=alpha,
linewidth=linewidth, label=target_name)
plt.legend(loc = 'best', shadow=False, scatterpoints=1)
ax.set_title('First three PCA directions')
ax.set_xlabel('1st eigenvector')
ax.set_ylabel('2nd eigenvector')
ax.set_zlabel('3rd eigenvector')
ax.view_init(30, 10)

- 7.4 递归特征消除
递归特征消除的主要思想是反复的构建模型(如SVM或者回归模型)然后选出最好的(或者最差的)的特征(可以根据系数来选),把选出来的特征放到一遍,然后在剩余的特征上重复这个过程,直到所有特征都遍历了。这个过程中特征被消除的次序就是特征的排序。因此,这是一种寻找最优特征子集的贪心算法。
from sklearn.feature_selection import RFECV
from sklearn.linear_model import LogisticRegression
selector = RFECV(LogisticRegression(), step=1, cv=5, n_jobs=-1)
selector = selector.fit(dataset_con_enc.drop('predclass',axis=1).values,dataset_con_enc['predclass'].values)
print('Feature Ranking For Non-Discretised: %s' % selector.ranking_)
print('Optimal number of features: %d' % selector.n_features_)
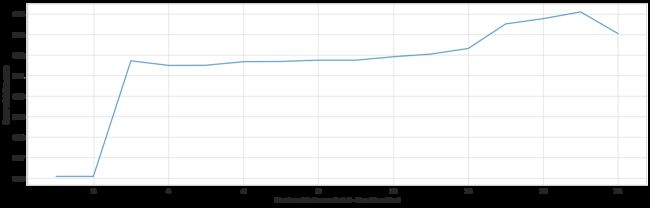
plt.figure(figsize = (20, 6))
plt.plot(range(1,len(selector.grid_scores_)+1), selector.grid_scores_)
plt.xlabel('Number of features selected - Non-Discretised')
plt.ylabel('Cross validation score')
Feature Ranking For Non-Discretised: [1 1 1 1 1 1 2 1 1 1 1 1 1 1 1 1]
Optimal number of features: 15
# 和传参对应,所选择的属性的个数
print(selector.n_features_)
# 打印的是相应位置上属性的排名
print(selector.ranking_)
# 属性选择的一种模糊表示,选择的是true,未选择的是false
print(selector.support_)
# 第1个属相的排名
print(selector.ranking_[1])
# 外部估计函数的相关信息
print(selector.estimator_)
15
[1 1 1 1 1 1 2 1 1 1 1 1 1 1 1 1]
[ True True True True True True False True True True True True True True True True]
1
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True, intercept_scaling=1, l1_ratio=None, max_iter=100, multi_class=‘warn’, n_jobs=None, penalty=‘l2’, random_state=None, solver=‘warn’, tol=0.0001, verbose=0, warm_start=False)
dataset_con_enc = dataset_con_enc[dataset_con_enc.columns[np.insert(selector.support_, 0, True)]]
dataset_con_enc.head()

- np.insert()可以有三个参数(arr,obj,values),也可以有4个参数(arr,obj,values,axis):
第一个参数arr是一个数组,可以是一维的也可以是多维的,在arr的基础上插入元素
第二个参数obj是元素插入的位置
第三个参数values是需要插入的数值
第四个参数axis是指示在哪一个轴上对应的插入位置进行插入
八. 选择数据集
selected_dataset = dataset_con_enc
selected_dataset = selected_dataset.dropna(axis=1)
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(selected_dataset.drop('predclass',axis=1),selected_dataset['predclass'],test_size=0.3,random_state=42)
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)
X_train.head()
(34189, 15)
(34189,)
(14653, 15)
(14653,)

未完待续…