模型压缩之Distilling Knowledge From a Deep Pose Regressor Network
Distilling Knowledge From a Deep Pose Regressor Network
文章目录
- Distilling Knowledge From a Deep Pose Regressor Network
- 主要工作
- 主要结构
- 损失函数
- 原始的蒸馏
- 使用student&imitation loss最小值
- 将Imitation loss作为辅助损失
- 将teacher loss作为损失的上界
- 使用probabilistic imitation loss(PIL)
- 使用attentive imitation loss(AIL)
- 学习教师网络的中间表达
- 实验细节
- 结果
- 相关链接

原始文档:https://www.yuque.com/lart/gw5mta/nnqdlk#j7uhw
主要工作
本文使用知识蒸馏来做pose regression的. 考虑到适用于分类的知识蒸馏依赖于"dark knowledge", 而这样的知识对于pose regression是not available的(?), 并且教师的预测并不总是准确的, 所以这里提出了一种基于对老师模型的结果的"信任"程度来附加蒸馏损失的方案. 这通过计算教师模型的预测与真值之间的差异作为其在监督中重要性的依据.
关于蒸馏主要使用了两点两个损失:
- attentive imitation loss(AIL)
- attentive hint training(AHT)(在FitNet的基础上使用了类似AIL的加权方式)
似乎这篇文章是第一篇将蒸馏用到了pose regression中的论文.
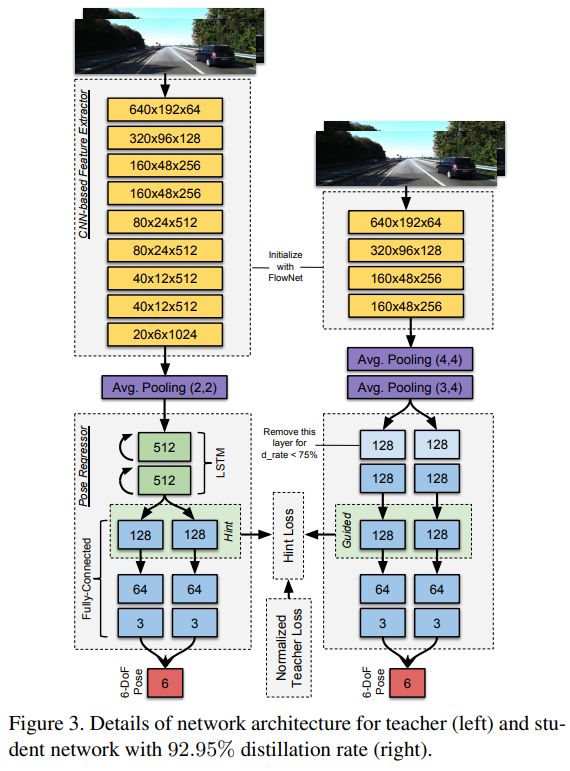
主要结构
损失函数
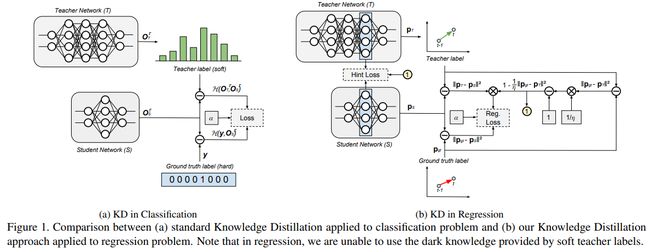
关于损失的构造, 这篇文章比较有意思的是给出了不同的蒸馏损失构造的考量. 接下来顺着来一遍. 不过最终是按照了上面图中b所示的结果进行了构造.
原始的蒸馏
- 教师网络T输出表示为:
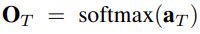 , 其中的aT表示教师网络的logits, 也就是softmax之前的输出(pre-softmax output)
, 其中的aT表示教师网络的logits, 也就是softmax之前的输出(pre-softmax output) - 学生网络S输出表示为:
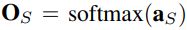 , 其中的aS表示学生网络的logits
, 其中的aS表示学生网络的logits - 由于OT通常非常接近于分类标签的one-hot编码形式, 所以一般会使用一个温度参数t>1, 来软化T的输出分布, 同样, 学生网络也使用相同的温度参数, 也就是有:
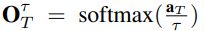 和
和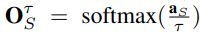 . 但在测试的时候使用t=1
. 但在测试的时候使用t=1 - 最终的损失表示为式子1所示, 其中H表示交叉熵损失, y表示one-hot编码的真值, 也就是图1a中所示的情况
![]()
因为对于传统的知识蒸馏而言, 这样的设定是为了利用来自教师模型的带有一定不准确信息相对概率, 以便于更好的泛化到新的数据上, 但是对于回归问题而言, 这个优势并不存在. 从图1b中可以看到, 教师和真值标签有着相同的特征(这里应该是在说对于分类任务而言, 教师的预测和真值的表示实际上还是不一样的, 毕竟一个是soft target一个是hard target, 而对于回归问题, 值都是连续的, 所以传统蒸馏的这种设定出发点就站不住了).
所以更愿意直接最小化学生网络关于真值的损失, 因为教师模型结果是被未知的误差分布影响的. 然而直接使用真值来训练S的实现效果也不是太好. 所以还是要探索如何更合适的使用蒸馏手段来处理.
为了进一步探索整流技术使用方法, 这里进行了多种尝试, 其中将学生预测关于真值的损失记作student loss, 关于教师模型的预测的损失记作imitation loss, 教师模型关于真值的损失记作teacher loss.
使用student&imitation loss最小值
- 假设T在所有条件下都有着很好的预测准确率, 这种情况下, T的预测就很接近真值了, 对于最小化S关于真值还是T没有太大区别
- 处于"简单"的原则, 直接最小化student loss和imitation loss中的最小值, 损失也就可以表示为式子2中的情况
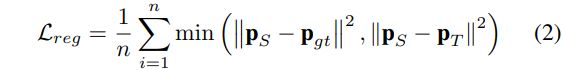
这里的PS, Pgt, PT分别表示学生网络的预测, 真值, 教师网络的预测.
将Imitation loss作为辅助损失
- 这种情况下, 不去专门寻找二者的最小值, 而是直接将imitation loss作为一个辅助损失来对student loss进行补充
- 这种情况下, imitation loss实际上可以看做是一种对于网络的正则化的方式, 可以在一定程度上阻止网络的过拟合
- 目标函数最终变成了式子3所示的样子, 这个形式实际上和原始针对分类的蒸馏的表达(式子1)是相似的, 除了原始的交叉熵被替换成了回归损失(regression loss)
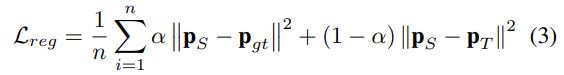
将teacher loss作为损失的上界
- 等式2和3实际上都需求教师模型T在大多数情况下都要有着良好的泛化能力, 这在实际中很难的, T可能会有很多误导, 在不利环境中, T可能预测相机姿态和真值是相反的
- 不在直接最小化S关于T的损失, 而是利用T作为S的上界, 这意味着S的预测应该尽可能接近真值, 但是当它性能超过T的时候, 不会收到额外的约束(损失)
- 这种情况下, 损失函数就变成了类似式子4和5的情况
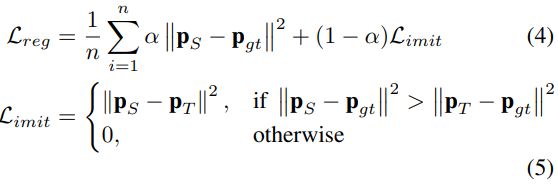
使用probabilistic imitation loss(PIL)
- 正如前所述, T并不总是准确的. 因此T的预测是包含一些不确定性的, 这可以显式利用参数分布来模拟这个不确定性
- 可以使用Laplace分布来模拟imitation loss, 如式子6所示, 这里的 σ \sigma σ是一个S应该预测的额外的数
- 这种情况下, imitation loss可以转化为最小化式子6的负对数似然来表达, 如式子7所示
- 最终的目标函数通过使用式子7来替换式子4中的Limit实现.对于S来说, 可以将式子7看作是学习合适的系数(通过 σ \sigma σ)来对于不可靠的T的预测进行向下加权(down-weight)的一种方式
- 这里的参数分布也可以使用高斯分布
- 可以看式子7中的表达, 对于PS和PT相近的时候, 得到imitation loss就会被放大, 而差异较大的时候(可以认为这种情况下是教师模型的输出的误差太大了), 损失因为这种形式的表现, 结果反而影响不会太大
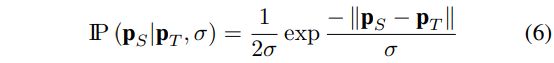
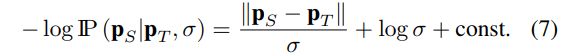
使用attentive imitation loss(AIL)
- 从PIL形式的imitation loss可以看出来, 这里对于不确定性使用一个参数分布来进行模拟, 可能并不能准确的反映出T的预测的误差分布
- 这里不再依赖S来学习一个数量 σ \sigma σ来对于T的预测进行down-weight, 而是使用T的预测关于真值的经验误差(empirical error)来做这件事
- 目标函数最终变成了如同式子8的形式
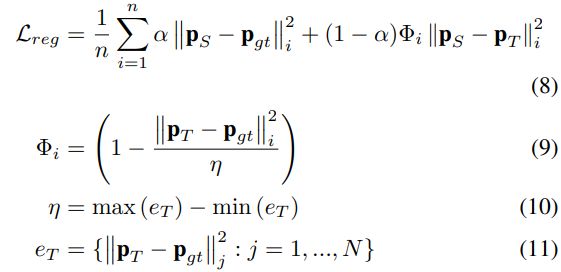
这里的 Φ i \Phi_i Φi表示对于每个样本i的归一化教师损失, 其中的 e i e_i ei表示来自整个训练数据的教师损失集合, 并且其中的 η \eta η是一个归一化参数. 注意其中的 ∣ ∣ ⋅ ∣ ∣ i & ∣ ∣ ⋅ ∣ ∣ j || \cdot ||_i \& || \cdot ||_j ∣∣⋅∣∣i&∣∣⋅∣∣j并不表示p-norm, 其中的i表示对于来自一个batch样本的索引(i=1, …n), 而j表好似对于整个训练数据集中样本的索引(j=1, …, N).
图1b中的结构展示了如何将式子8表达出来. 此时的 Φ i \Phi_i Φi更多的是表达着相对的重要性, 所以被称为"attentive". 整个损失还可以被重新表达为: L r e g = α n ∑ i = 1 n ∣ ∣ p S − p g t ∣ ∣ i 2 + 1 − α n ∑ i = 1 n Φ i ∣ ∣ p S − p T ∣ ∣ i 2 L_{reg}=\frac{\alpha}{n}\sum^n_{i=1}||\mathbf{p}_S-\mathbf{p}_{gt}||^2_i+\frac{1-\alpha}{n}\sum^n_{i=1}\Phi_i||\mathbf{p}_S-\mathbf{p}_T||^2_i Lreg=nα∑i=1n∣∣pS−pgt∣∣i2+n1−α∑i=1nΦi∣∣pS−pT∣∣i2. 这样一来, 在知识迁移过程汇总, imitation loss更多的会依赖T更擅长的样本数据.
学习教师网络的中间表达
这里有些类似与FitNet的构思. 旨在通过Hint Training(HT)这样的训练方式, 使得S可以mimicT的潜在表达(latent representation), 这被设计为原始知识蒸馏的一种扩展. 对于原始的FitNet的设定, 通过将T的知识迁移到有着更深但是会更瘦的S上, 甚至可以取得超越T的效果. 这里将这样的方法用到了较浅的回归网络中. HT可以看做是另一种正则化S的方法, 可以更好地mimic模型T的泛化能力.
对于原始FitNet的方法, 这里只需要直接优化![]() 即可, 但是这个式子没有考虑T可能并不是一个完美的函数估计器, 并且可能给S误导.
即可, 但是这个式子没有考虑T可能并不是一个完美的函数估计器, 并且可能给S误导.
借鉴自式子8, 这里同样的使用"attentive"的方法, 来作为改进(attentive hint training):
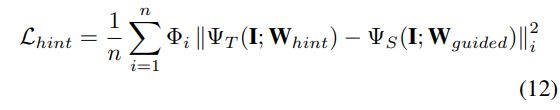
这里的 Φ i \Phi_i Φi是归一化的teacher loss, 同式子9中是一样的.
实验细节
虽然8和12可以一起训练, 但是发现分开单独训练可以产生更好的效果:
- The 1st stage trains S up to the guided layer with (12) as the objective.
- 如图3中所示, 选择T的第一个FC层作为hint, 并且S的第三个FC层作为guided层(或者是drate<75%的时候对应第二个FC层)
- 使用T的FC层作为hint, 不只是为训练S提供一个更容易的引导(因为对于T和S的FC层有着相同的分布), 而且也是为了迁移T学习相机姿势的长期运动动力学(long-term motion dynamics of camera poses), 因为T的FC层是位于RNN-LSTM层后的
- The 2nd stage trains the remaining layer of S (from guided until the last layer) with (8) as the objective.
- 第二阶段中冻结第一阶段训练出来的那部分权重, 只训练剩下的层
- We implemented T and S in Keras. We employed NVIDIA TITAN V GPU for training and NVIDIA Jetson TX2 for testing.
- The training for each stage goes up to 30 epochs.
- For both training stages
- we utilize Adam Optimizer with 1e-4 learning rate.
- We also applied Dropout with 0.25 dropout rate for regularizing the network.
- For the data, we used KITTI and Malaga odometry dataset.
- We utilized KITTI Seq 00-08 for training and Seq 09-10 for testing.
- Before training, we reduced the KITTI image dimension to 192 × 640.
- We only use Malaga dataset for testing the model that has been trained on KITTI.
- For this purpose, we cropped the Malaga images to the KITTI image size.
- Since there is no ground truth in Malaga dataset, we perform qualitative evaluation against GPS data.
结果
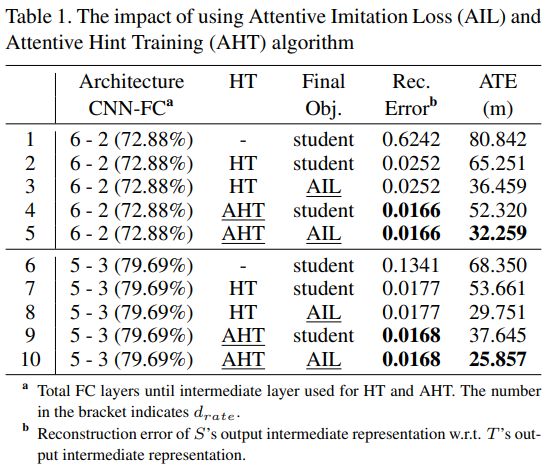
- HT 表示使用的hint training方法
- Final Obj. 表示最终使用的目标函数
- Rec. Error 表示在hint training中的重建误差
- ATE 表示Absolute Trajectory Error(绝对轨迹误差), ATE表示的是估计出来的轨迹与ground truth之间的绝对距离(评估之前使用相似变换进行alignment)
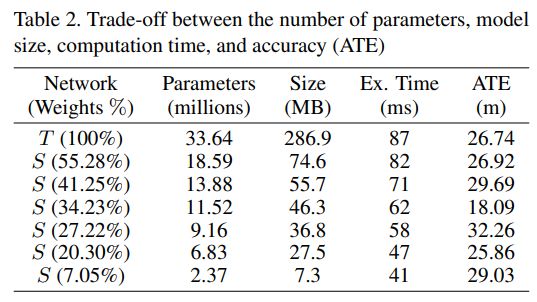
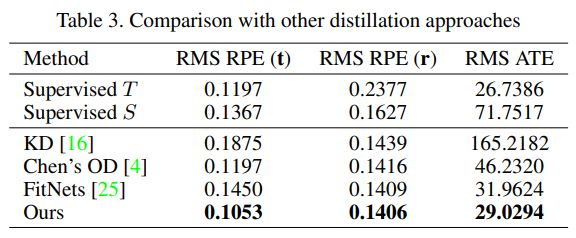
- RMS: Root Mean Square
- RPE: Relative Pose Error (RPE). RPE表示的是在一个固定长度的间隔内, 所估计的相机姿态到ground truth的平均误差
- ATE: 表示Absolute Trajectory Error(绝对轨迹误差), ATE表示的是估计出来的轨迹与ground truth之间的绝对距离(评估之前使用相似变换进行alignment)
相关链接
- 论文: https://arxiv.org/pdf/1908.00858.pdf