基于深度学习的关系抽取综述
论文:https://arxiv.org/pdf/1705.03645.pdf
一、介绍
信息抽取是NLP的一个基本任务,从非结构化文本中抽取机器或程序能够理解的结构化知识。信息抽取包括以下子任务:NER、关系抽取、事件抽取等等。本文中,我们着重关注于深度学习在关系抽取任务的应用。
IE可以应用在无监督或半监督领域,以OpenIE的形式,我们不用预定义好本体或关系类,我们从数据中直接抽取事实和关系短语。在有监督领域中,关系抽取和分类就是预定义好关系集合号,然后在包含实体对的文档中识别实体对之间的关系,可以视为多分类或二分类问题。
对于关系抽取任务,传统的非深度学习方法可以分为两类:基于特征的方法和基于kernel的方法。在两类方法中,提取的特征和精心设计的kernel使用预先存在的NLP系统,这导致各个模块在下游累积的错误。另外,自动构造的特征可能无法捕捉所有相关的信息。通过深度学习自动构建特征,可以消除对手动工程师功能的这种需求。
有监督学习需要大量标注数据用于训练。手工标注数据耗费大量人力。Mintz et al.(2009)提出了远程监督的方法用于生成大量数据。这样大的数据集可以训练复杂的模型,如CNN。通过远程监督生成的数据集中存在的噪声也需要特殊的方法来建模问题,如后续章节中讨论的多示例学习。
二、数据集
2.1 有监督训练
- ACE 2005 dataset Automatic Content Extraction数据集包含599篇与新闻和电子邮件相关的文档,7种关系类型。其中,6种主要关系类型包含足够的实例(每种关系类型平均700个实例),用于训练和测试。
- SemEval-2010 Task 8 dataset 由Hendrickx et al. (2009)提供的免费数据集,包含10717个样本,8000个样本用于训练,2717个样本用于测试。包含9种关系类型,关系是有序的。关系的方向性有效地使关系的数量加倍,因为只有当顺序也正确时,才认为实体对被正确标记。所以最终存在19个关系(2*9+1 other class)
2.2 远程监督
为了减少标注数据的大量人力,Mintz et al.(2009)提出远程监督方法自动地生成大量训练数据。如果知识库中的实体对存在某种关系,那么包含该实体对的每篇文档都存在该关系。 很明显,远程监督这种假设太绝对了,包含实体对的每个文档不可能都表达这种关系。比如知识库中 的三元组(Microsoft, Founder of, Microsoft),文档“Bill Gatess turn to philanthropy was linked to the antitrust problems Microsoft had in the U.S. and the European union”,该文档并没有表示“Founder of”关系,即使存在该实体对。
为了缓解上述问题和降低噪音,Riedel et al. (2010)放松了远程监督假设,将问题建模为多示例学习问题。
三、基本概念
3.1 Word Embedding
词向量是词的分布式表示,用一个低维向量表示。词向量旨在捕捉词的句法和语义信息。词向量通过在大规模的无标签语料中使用无监督方法训练得到。
3.2 Positional Embedding
在关系抽取任务中,不只有词向量,位置向量也作为模型的输入来编码每个词到实体的相对距离。这有助于网络跟踪每个单词与每个实体的接近程度。这个想法是靠近目标实体的单词通常包含关于关系类更多有用信息。位置向量包括当前单词与实体的相对距离。
3.3 CNN
为了进一步编码句子,关系抽取的深度学习模型使用CNN模型来捕捉n-gram特征。
四、CNN用于监督学习
将关系抽取任务视为多分类问题,对每个包含实体对的句子设置一个关系标签。
4.1 Simple CNN model(Liu et al.,2013)
这个工作是最早用CNN来自动提取特征,代替了手工特征。它构造了一个端到端的网络,将输入句子用词向量和词法特征进行编码,然后接卷积层、全连接层、softmax层。
该模型使用同义词向量代替了词向量,通过为每个同义词类指定单个向量而不是为每个单词提供向量。但是,它无法利用单词嵌入的真实表征能力。同义词训练不是在语料库上以无监督的方式训练,而是随机分配给每个同义词类。此外,该模型还尝试使用单词列表,POS列表和实体类型列表来合并一些词法特征。在ACE 2005数据集上比STOA 的基于kernel的方法F1提高了9个点。
4.2 CNN model with max-pooling (Zeng et al., 2014)
与上篇论文不同,作者使用了预训练的词向量,同时是早期首个使用Position Embedding的。本篇论文的一个重要贡献是在CNN层后使用了最大池化层。
4.3 CNN with multi-sized window kernels (Nguyen and Grishman, 2015)
模型完全摈弃了词法特征,让CNN自动学习特征。通过多窗口卷积不同尺度的n-gram信息。
五、Multi-instance learning models with distant supervision
之前也提到了远程监督的局限性,Riedel et al.(2010)放松了远程监督假设,将任务建模为多示例学习问题。这样他们就可以利用远程监督创建的大型训练数据,同时对标签中的噪声具有鲁棒性。多示例学习是有监督学习的一种形式,对一个包进行标注,而不是对一个实例。在关系抽取中,每个实体对定义为一个包,包由存在该实体对的所有句子组成。并不是对每个句子打关系标签,而是对整个包。如果实体对存在某种关系,那么包中至少有一个句子反映了该关系。
5.1 Piecewise Convolutional Neural Networks (Zeng et al., 2015)
PCNNs模型通过多实例学习范例,使用神经网络模型在远程监督数据中训练关系提取器。模型结构与之前的类似,重要贡献是提出了piecewise max-pooling。作者声称最大池化层大大减小了隐藏层的大小,也不足以捕获句子中实体之间的结构。这可以通过句子的不同段而不是整个句子中的最大池来避免。每个句子根据两个实体可以分为三部分。通过在每个段内执行分段最大池化,我们可以获得更丰富的表示,同时仍然保持与输入句子长度无关的向量。
此模型中的一个缺点是稍后在未来模型中解决的问题:在损失函数中设置多实例问题的方式。多示例学习假设至少存在一篇文档表示了实体间的关系。该模型在训练和预测时只利用了包中最大概率的文档,这意味着模型忽略了包中大量有用的数据。即使并非包中的所有句子都表达了实体对之间的正确关系,但仅使用单个句子是非常严格的约束。
5.2 Selective Attention over Instances (Lin et al., 2016)
为了解决PCNN只利用了包中最相关的句子的问题,Lin et al使用了attention,对包中的每个句子计算一个权重。当使用包中所有实例的这种注意加权表示找到损失时,模型能够固有地识别来自噪声的重要句子,并且利用包中的所有信息来进行关系类预测。
5.3 Multi-instance Multi-label CNNs (Jiang et al., 2016)
本文的作者通过使用跨文档的最大池化层解决了Zeng et al. (2015) 的信息损失问题。像上述的attention模型,对包i的每个句子 d i j d^j_i dij首先会找到一个向量表示 r i j r^j_i rij。然后通过采用句子向量的维数最大值来找到句子包的最终向量表示。包中句子最终的特征向量表示为:
( r i ) k = max j = 1 , 2... q i ( r i j ) k ; k = 1 , 2... D (r_i)_k=\max_{j=1,2...q_i}(r^j_i)_k;k=1,2...D (ri)k=j=1,2...qimax(rij)k;k=1,2...D
这使得最终特征向量的每个特征都来自于最相关的文档,而不是整个特征向量来自于包中最相关的一个文档。本文同时也解决了关系抽取的多标签问题。到现在为止,所有模型预测一个实体对的关系时,都是多分类做的。但其实实体对可能同时有多个关系(关系重叠)。于是作者在最终的分类层将softmax改为了sigmoid。
六、Result
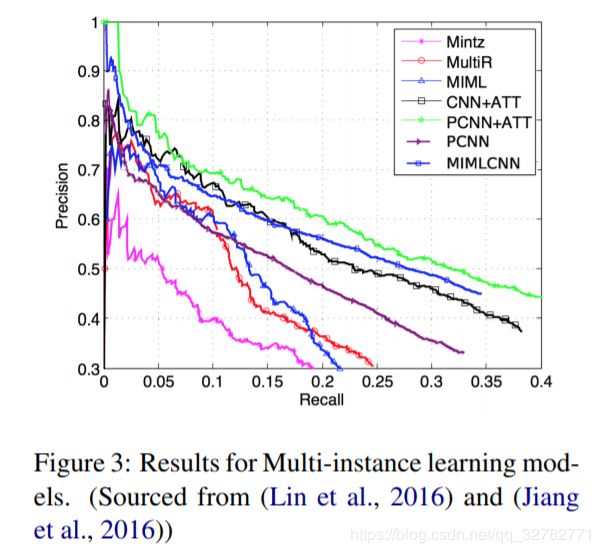
图三总结了各个多示例学习模型在远程监督数据集的实验结果。三个非深度学习模型:Mintz、MultiR、MIML。可以看到所有深度学习模型都要优于非深度学习模型。
。
七、Concluding Remarks
自从Mintz et al.(2009)提出远程监督,将关系抽取建模为多示例学习问题已经被广泛采用。使用这种机制还为深度学习模型提供了足够的数据,以便在多实例设置中进行训练,以适应数据中的标记噪声。有工作尝试通过选择性注意力机制和跨文档最大池化等机制来处理噪声和远程监督假设,提高了实验结果。一些最近的工作也尝试利用关系之间的交互,通过利用关系路径和关系类关系来提高实验结果。然而,这些改进仅适用于模型的训练和推理方法。就深度学习方面而言,用于编码句子的CNN架构的PCNN在所有这些工作中是相同的。很少用RNN/LSTM来建模句子。RNN和LSTM很适合处理NLP任务。即便对CNN和RNN目前没有很好地区分,到底哪个结构比较好。使用LSTM来编码句子和关系是未来的一个工作。