建立数据挖掘的用户画像
基于用户的画像
前言
根据用户历史信息与用户的人口属性标签(包括性别、年龄、学历)通过机器学习、数据挖掘技术建立模型预测用户标签,制定用户的画像,便于前期调研,需求分析,后期营销等,故为用户制定相应的画像是一项非常有意义的工作

导入先关库
import datetime
import pandas as pd
import numpy as np
import pyecharts
import seaborn as sns
import re
import gc
import matplotlib.pyplot as plt
import warnings
import jieba
import lightgbm as lgb
import xgboost as xgb
from pyecharts.charts import WordCloud
from jieba import analyse # 从 jieba 中导入关键词分析模
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import MultinomialNB
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import cross_val_score
from sklearn.metrics import mean_absolute_error, roc_auc_score, precision_score
warnings.filterwarnings('always')
warnings.filterwarnings('ignore')
sns.set(style="darkgrid")
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示
%matplotlib inline
train_path = "user_tag_query.TRAIN.csv"
train = pd.read_csv(train_path)
数据探索
train.sample(2)
| Unnamed: 0 | age | Gender | Education | QueryList | |
|---|---|---|---|---|---|
| 843 | 8852 | 5 | 1 | 0 | 湖水月色空前打一国家\t今天双色球开奖结果\t降魔伏妖\t伏妖降魔能制宜打一肖\t徐霞客属什... |
| 499 | 99465 | 2 | 2 | 4 | u盘\t沉香by红夜\t悲观主义者有哪些表现\t杨洋icon微博\t美术欣赏\t好看的小说推... |
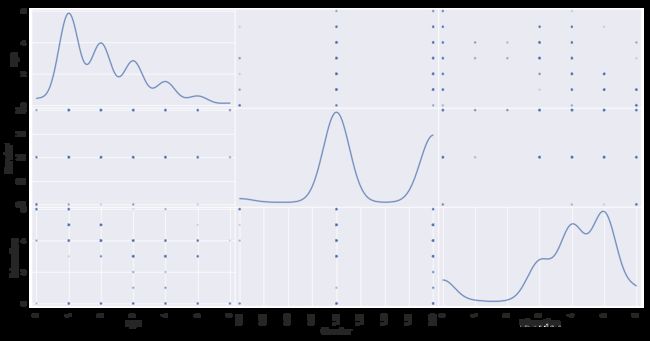
pd.plotting.scatter_matrix(
train[["age", "Gender", "Education"]], alpha=0.3, figsize=(16, 8), diagonal='kde');
age_list = pd.Series({0: "未知年龄",
1: "0-18岁",
2: "19-23岁",
3: "24-30岁",
4: "31-40岁",
5: "41-50岁",
6: "51+岁"})
pie_data = pd.concat([train["age"].value_counts(), age_list], axis=1)
pie_list = []
for i in pie_data.iloc[:, 0].get_values():
pie_list.append(int(i))
from pyecharts import options as opts
from pyecharts.charts import Page, Pie
def pie_base() -> Pie:
c = (
Pie()
.add("", [list(z) for z in zip(pie_data.iloc[:, 1], pie_list)])
.set_global_opts(title_opts=opts.TitleOpts(title="用户年龄段数"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
.render_notebook()
)
return c
pie_base()

数据清洗
train_clean = train.copy()
def stopwordslist(filepath):
stopwords = [line.strip() for line in open(filepath, 'r', encoding='gbk').readlines()]
return stopwords
# 对句子进行分词
def seg_sentence(sentence, path):
sentence_seged = jieba.cut(sentence.strip())
stopwords = stopwordslist(path) # 这里加载停用词的路径
outstr = ''
for word in sentence_seged:
if word not in stopwords:
if word != '\t':
outstr += word
outstr += " "
return outstr
去除停止词
在文本相关的任务中,大多需要先对样本进行分词、去停用词等预置处理。通过对训练数据进行细致的分析,结合人们进行日常检索的先验知识,发现“空格”、“标点”及很多停用词均有助于判别用户的基本属性。
train_clean["QueryList"] = train_clean["QueryList"].apply(lambda x: seg_sentence(x, "stopword.txt"))
from jieba import analyse
def wordcloud_diamond(words, title) -> WordCloud:
c = (
WordCloud()
.add("", words, word_size_range=[20, 100])
# .set_global_opts(title_opts=opts.TitleOpts(title=title))
.render_notebook()
)
return c
def extract(data):
keyWords = jieba.analyse.extract_tags(sentence=data, # 要分词的任意一篇中文文章
topK=100, # 选取200 个关键词
withWeight=True # 显示每一个分词所占的权重
)
return keyWords
分词
提取关键信息,过滤掉了文档频率低于5的词,才能达到最好的预测效果
wc = train_clean["QueryList"].apply(lambda x: extract(x)) #分词,提取关键词
个人词云
print("ID 10 的个人画像")
wordcloud_diamond(wc.iloc[10], "用户画像")
ID 10 的个人画像

print("ID 68 的个人画像")
wordcloud_diamond(wc.iloc[68], "用户画像")
ID 68 的个人画像

数据转换和特征处理
def transform(x):
a = np.array(x).T
b = pd.DataFrame(data=a, columns=a[0]).drop(0)
b.index = [x.index]
return b
a = wc.apply(lambda x: transform(x))
queryData = pd.DataFrame({})
for i in a:
queryData = pd.concat([queryData, i.T], axis=1)
del a
queryData = queryData.T.astype(float)
indexs = queryData.count()[queryData.count() > 5].index #筛选出现频率超过5次的特征
X = queryData[indexs].fillna(0)
del indexs, queryData
开始建模
交叉验证
from sklearn.model_selection import KFold
n_fold = 4
folds = KFold(n_splits=n_fold,shuffle=True)
print(folds)
KFold(n_splits=4, random_state=None, shuffle=True)
y1, y2, y3 = train_clean["age"], train_clean["Gender"], train_clean["Education"]
def kf_class(X, y, model):
clf_dict = {}
for fold_n, (train_index, valid_index) in enumerate(folds.split(X)):
print(fold_n)
X_train, X_valid = X.iloc[train_index], X.iloc[valid_index]
y_train, y_valid = y.iloc[train_index], y.iloc[valid_index]
model.fit(X_train, y_train)
print('finish train')
print('Train accuracy: {}'.format(model.score(X_train, y_train)))
print('Test accuracy: {}'.format(model.score(X_valid, y_valid)))
clf_dict[fold_n] = model
del X_train, y_train
del X_valid, y_valid
gc.collect()
return clf_dict
LGB模型
lgb_clf = kf_class(X, y2, lgb.LGBMClassifier())
0
finish train
Train accuracy: 0.7466666666666667
Test accuracy: 0.56
1
finish train
Train accuracy: 0.72
Test accuracy: 0.6
2
finish train
Train accuracy: 0.7333333333333333
Test accuracy: 0.84
3
finish train
Train accuracy: 0.7466666666666667
Test accuracy: 0.6
feature_importance_df = pd.DataFrame(
[X.columns.values, lgb_clf[0].feature_importances_], index=["Feature", "importance"]).T
feature_importance_df["importance"] = feature_importance_df["importance"].astype(float)
特征筛选
from pyecharts.charts import Bar
from pyecharts import options as opts
cols = feature_importance_df.sort_values(by="importance", ascending=False)[: 15]
bar = Bar()
bar.add_xaxis(cols["Feature"].values.tolist())
bar.add_yaxis("top 15 feature", [int(i) for i in cols["importance"].values])
bar.set_global_opts(title_opts=opts.TitleOpts(title="特征重要性"))
bar.render_notebook()
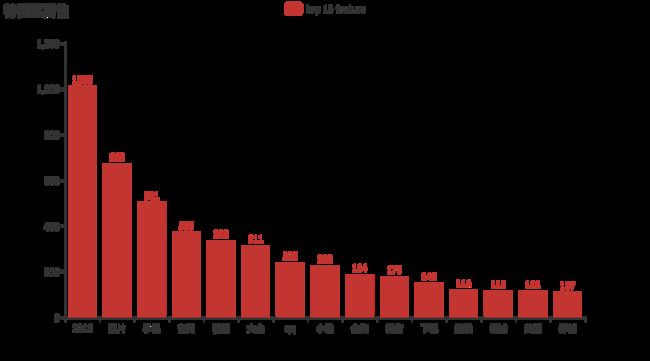
筛选强特征后再建模
features = feature_importance_df[feature_importance_df["importance"] > 3]["Feature"].values
rf_clf = kf_class(X[features], y2, RandomForestClassifier(
min_samples_leaf=2,
min_samples_split=3,
n_estimators=25))
0
finish train
Train accuracy: 0.9453333333333334
Test accuracy: 0.692
1
finish train
Train accuracy: 0.9453333333333334
Test accuracy: 0.72
2
finish train
Train accuracy: 0.944
Test accuracy: 0.732
3
finish train
Train accuracy: 0.9413333333333334
Test accuracy: 0.704
time: 2.48 s
最后简易模型训练集准确率在94%+,测试集准确率在70%+
在特征处理上仍有加强空间
总结
- 用户群主要集中在30岁以下,研究所本科学历
- 特征处理时,使用了jieba提取关键词,高频词,可在已有数据外训练词典和词向量,加强特征
- 建模时尝试了多种模型,最终选用了LGB模型来筛选强特征,然在再二次建模,后续可以使用交叉
验证的4个模型在融合,得到更强的模型,整体流程如下
