BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
引言
Google在2018年发出来的论文,原文地址:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT实际上是一个语言编码器,或者说做的是representaion方面的工作,主要作用是将输入的句子或者段落转化为相应的语义特征。
作者提到当前的很多工作都限制了pre-train的潜力,传统语言模型是简单的left-to-right结构,这种形式其实损失右侧上下文信息;或者由两个单向模型叠加,也不能很好的利用上下文。另一个,单纯的语言模型也不能很好的解决某些需要判断句子间关系的任务。
因此,论文使用了以下的模型结构:
1、基于transformer的基本网络结构
2、利用Mask LM实现双向模型预训练
3、利用Next Sentence Prediction实现句子间关系预训练
模型在11项NLP任务上都取得了SOTA的结果,其中包括NER,阅读理解等。
Transfer Learning
目前的深度学习任务中,已经形成了两段式的形式,即训练语义表示,再基于语义表示构建下游任务。其中关于下游任务使用预训练的表达存在两种形式,即:feature-based和fine-tuning。
Feature-based Approaches
Feature-based的形式即是把预训练出来的语义特征当成下游任务的特征,典型的如word2vec或者ELMO,在下游任务中,预训练的特征保持不变。
Fine-tuning Approaches
另一种形式即是在预训练语言模型的基础上,添加task special的层,比如增加一个softmax用于分类判断。
利用标记语料进行再次训练,在这个过程中所有参数都是可训练的。
模型
基础结构是Multi-layer bidirectional Transformer encoder,即是Attention is all you need论文中提出的结构,使用attention代替RNN等传统特征抽取器,在浅层就能够抽取到全局特征。
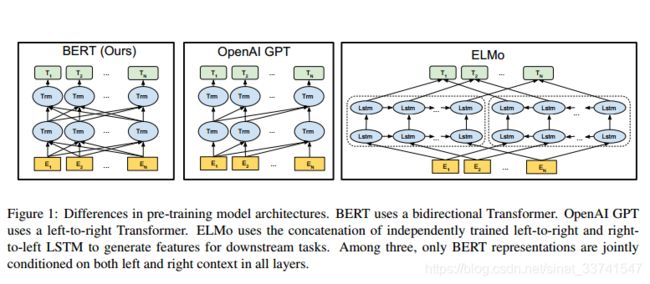
上图左侧即为BERT模型,对比中间的GPT模型,一个显著的区别是GPT是left-to-right的形式,而BERT抛弃了传统语言模型的训练方式,直接获取上下文的信息。
相比ELMo模型,这里实现的双向虽然也在一定程度上获取到全局信息,但这种上下文信息实际是左文加右文,同时LSTM在特征抽取上的能力相比transformer也较弱。
Google提供了两个不同大小的模型,参数如下:
- B E R T B A S E BERT_{BASE} BERTBASE: L=12, H=768, A=12, Total Parameters=110M
- B E R T L A R G E BERT_{LARGE} BERTLARGE: L=24, H=1024, A=16, Total
Parameters=340M
其中L为transformer block,H为hidden size,A为self-attention heads。
Input Representation
模型的输入由三部分组成,具体如下:
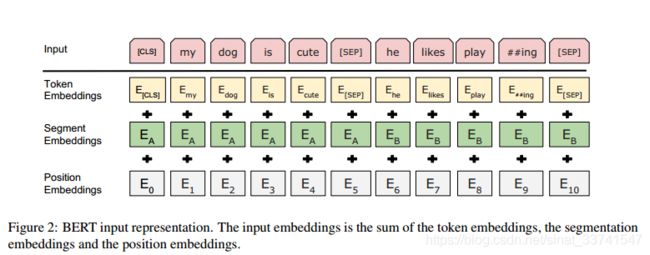
其中,Token embedding表示当前词的embedding;Segment Embedding表示当前词所在句子的index embedding;
Position Embedding 表示当前词所在位置的index embedding。
在每个句子的开头都会添加一个[CLS]表示作为模型的起始标识,同时也是下游比如分类任务使用的特定向量,在非分类任务中,这个向量可以被忽视。
假如输入为句子对,在句子对之间使用[SEP]表示分隔,在内部处理中将为每个句子分别生成句向量。
这里的position embedding与原始transformer不同的是使用了可训练的向量而不是手工设置的固定向量。
Pre-training Tasks
在BERT中,作者创新的设计了两种任务用于训练语言模型,其中一种借鉴于完形填空任务,另一种则是根据当前句子预测下一句,类似skip thought。
Masked LM
完形填空任务,即遮住句子中的某些单词,让模型去预测遮住的单词的是什么。从这个任务也可以看到,相比于传统的语言模型,这个任务会要求模型去记住更多关于上下文的信息。
在训练过程中,作者随机遮住了句子中15%的词,在词的输出增加softmax输出一个字典大小的分类概率用以预测。
但是这种做法存在问题,在下游任务中[MASK]标识是不存在的,那么这样会导致下游任务与预训练不匹配。
因此,对于15%要用[MASK]标示替代的词,用以下方法处理:
(1)80%的概率用masked token来代替。
(2)10%的概率用随机的一个词来替换。
(3)10%的概率保持这个词不变。
基于上述方式,模型无法知道明确的知道哪个词已经被随机替换掉,所以这样会强迫模型记住所有词的上下文表达,同时因为只是15%*10%的概率随机替换,这样看起来不会损害语言模型的整体信息。
另一个问题是,相对于传统的语言模型,完形填空任务只需要预测句子的15%,所以在收敛速度上会相对较慢,但鉴于其结果这种开销是可以接受的。
Next Sentence Prediction
在很多下游任务中,模型需要关注句子间的关系,但在传统语言模型是不会直接去建模相关信息的,因此这里加入一个新任务,判断输入的句子对是否拥有上下文关系。
在输入数据中,随机选取50%的句子对,将text a对应的下文text b替换为其他不相关句子,如下:

基于上述数据集训练一个分类模型,最后得到了97%~98%的正确率,后续在其他任务上的fine-tuning结果也证明了设计这个预训练任务能够获得不错的提高。
Pre-training
预训练采用上述设计的两个任务,语料来源于BooksCorpus (800M words)和English Wikipedia (2,500M words),这里提到为了获取长时序距离上的信息,使用文档级别的语料会比使用句子级别的语料要好,具体参数如下:
256个句子作为一个batch,每个句子最多512个token,即128,000 tokens/batch
迭代40个epochs, 总共迭代100万步,训练样本超过33亿
Adam学习率, β_1 = 0.9,β_2 = 0.999
L2正则,衰减参数为0.01
学习率前10000步保持固定值,之后线性衰减
Drop out设置为0.1
激活函数用GELU代替RELU
损失为MLM和NSP的各自平均损失之和
Bert base版本用了16个TPU,Bert large版本用了64个TPU,都训练了4天。
Fine-tuning
微调部分相对来说就简单了,对于句子级别的下游任务,只需要取第一个token即[CLS]的输出表示,后接一个softmax即可;对于字级别的下游任务,需要设计特定的方式,比如将最后一层token的每个输出都取出来,再分别加上softmax即可完成序列标注任务,如下:

在微调中,大部分参数与预训练过程都可以保持一致,除了batch size,learning rate,epoch。drop out的大小继续设置为0.1,作者给出一个参数选择范围:
Batch size: 16, 32
Learning rate (Adam): 5e-5, 3e-5, 2e-5
Number of epochs: 3, 4
在超参的选择上,小数据量的任务相比大数据量的任务更加敏感,但fine-tuning过程相对较快,可以考虑在上述范围内寻找最佳结果。
结果
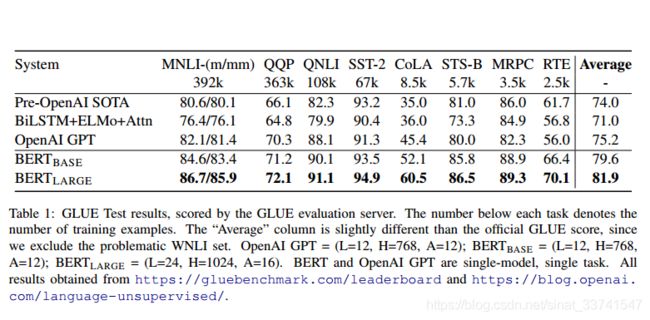
分类数据集
问答数据集

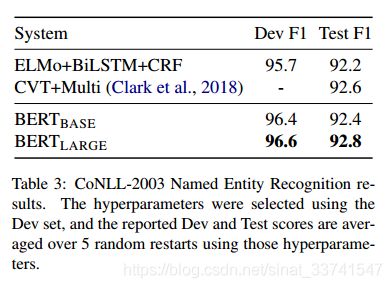
命名实体识别
常识推理

Ablation Study
Ablation study就是为了研究模型中所提出的一些结构是否有效而设计的实验。比如你提出了某某结构,但是要想确定这个结构是否有利于最终的效果,那就要将去掉该结构的网络与加上该结构的网络所得到的结果进行对比,这就是ablation study。
说白了,ablation study就是一个模型简化测试,看看取消掉模块后性能有没有影响。根据奥卡姆剃刀法则,简单和复杂的方法能够达到一样的效果,那么简单的方法更好更可靠。
Effect of Pre-training Tasks

NO NSP: 用masked语言模型,没用next sentence prediction
LTR&NO NSP: 用从左到右(LTR)语言模型,没有masked语言模型,没用next sentence prediction
+BiLSTM: 加入双向LSTM模型
可以看到, B E R T B A S E BERT_{BASE} BERTBASE模型表现相当不错。
Effect of Model Size
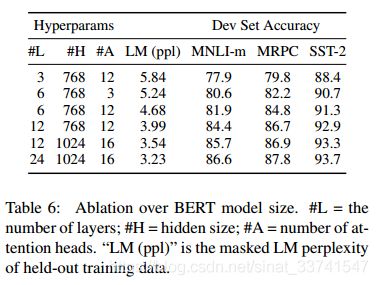
众所周知,在大规模数据集上,模型越大所带来的结果会更好,但这里也证明了在小数据集上这种结论也是成立的,而原因就是模型已经被有效的预训练了。
Effect of Number of Training Steps
Question: Does BERT really need such a large amount of pre-training (128,000 words/batch * 1,000,000 steps) to achieve high fine-tuning accuracy?
Answer: Yes, BERTBASE achieves almost 1.0% additional accuracy on MNLI when trained on 1M steps compared to 500k steps.
预训练1M步的模型相比预训练500K步的模型,拥有更好的效果。
Question: Does MLM pre-training converge slower than LTR pre-training, since only 15% of words are predicted in each batch rather than every word?
Answer: The MLM model does converge slightly slower than the LTR model. However, in terms of absolute accuracy the MLM model begins to outperform the LTR model almost immediately

相比传统语言LTR语言模型,BERT模型在收敛速度上更慢,但相对的,在正确率上很快就远远超过了LTR模型。
Feature-based Approach with BERT
最后作者提供了一个使用BERT作为feature的实验对比,具体如下:

结论
BERT这篇文章是近年的各种工作的集大成者,工程性很强。对于这个模型,它的优点更多的是巧妙地设计了任务用以训练无监督地语言模型,同时也证明了大规模的无监督训练对有监督任务是很有帮助的。
忽然想起,深度学习就是表示学习。后续的很多任务应该都会基于这种两段式的结构开发。
还有一个,money is all you need,笑。
引用
1、BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
2、Attention Is All You Need
3、Deep contextualized word representations
4、Improving Language Understanding by Generative PreTraining