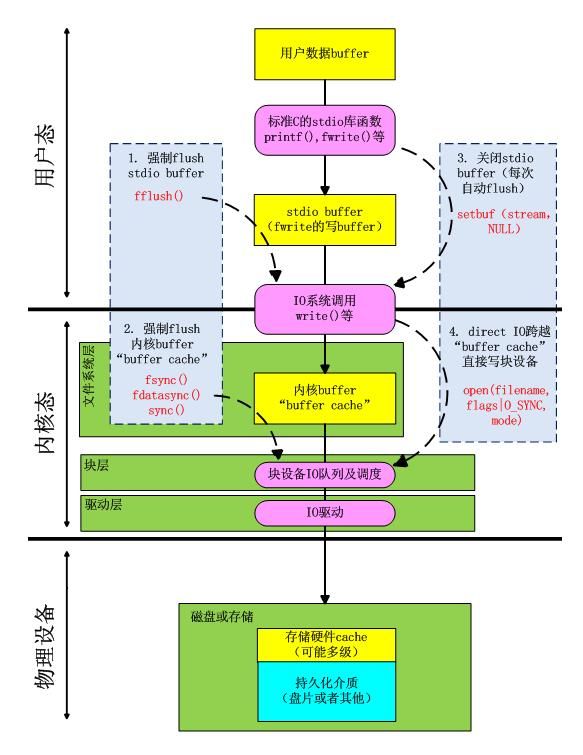
linux IO流程中各级缓存
1 “buffer cache” (指内存)
要理解”buffer cache”这个东西,需要澄清一下概念:
一般情况下,进程在io的时候,要依赖于内核中的一个buffer模块来和外存发生数据交换行为。另一个角度来说,数据从应用进程自己的buffer流动到外存,中间要先拷贝到内核的buffer中,然后再由内核决定什么时候把这些载有数据的内核buffer写出到外存。
“buffer cache”仅仅被内核用于常规文件(磁盘文件)的I/O操作。
内核中的buffer模块,就是今天的主题—-“buffer cache”(buffer,cache的功能兼备)
一般情况下,Read,write系统调用并不直接访问磁盘。这两个系统调用仅仅是在用户空间和内核空间的buffer之间传递目标数据。举个例子,下面的write系统调用仅仅是把3个字节从用户空间拷贝到内核空间的buffer之后就直接返回了
write(fd,”abc”,3);
在以后的某个时间点上,内核把装着“abc”三个字节的buffer写入(flush)磁盘……
如果另外的进程在这个过程中想要读刚才被打开写的那个文件怎么办?答案是:内核会从刚才的buffer提供要读取的数据,而不是从磁盘读。
介绍完“写出”,该介绍“读入”了。
当前系统上第一次读一个文件时,Read系统调用触发内核以block为单位从磁盘读取文件数据,并把数据blocks存入内核buffer,然后read不断地从这个buffer取需要的数据,直到buffer中的数据全部被读完,接下来,内核从磁盘按顺序把当前文件后面的blocks再读入内核buffer,然后read重复之前的动作…
一般的文件访问,都是这种不断的顺序读取的行为,为了加速应用程序读磁盘,unix的设计者们为这种普遍的顺序读取行为,设计了这样的机制—-预读,来保证进程在想读后续数据的时候,这些后续数据已经的由内核预先从磁盘读好并且放在buffer里了。这么做的原因是磁盘的io访问比内存的io访问要慢很多,指数级的差别。
read,write从语义和概念上来说,本来是必须要直接和磁盘交互的,调用时间非常长,应用每次在使用这两个系统的时候,从表象上来说都是被卡住。而有了这些buffer,这些系统调用就直接和buffer交互就可以了,大幅的加速了应用执行。
Linux内核并没有规定”buffer cache”的尺寸上线,原则上来说,除了系统正常运行所必需和用户进程自身所必需的之外的内存都可以被”buffer cache”使用。而系统和用户进程需要申请更多的内存的时候,”buffer cache”的内存释放行为会被触发,一些长久未被读取,以及被写过的脏页就会被释放和写入磁盘,腾出内存,以便被需要的行为方使用。
现在大体上你们已经知道了吧,”buffer cache”有五个flush的触发点:
1.pdflush(内核线程)定期flush;
2.系统和其他进程需要内存的时候触发它flush;
3.用户手工sync,外部命令触发它flush;
4.proc内核接口触发flush,”echo 3 >/proc/sys/vm/drop_caches;
5.应用程序内部控制flush。
这个”buffer cache”从概念上的理解就是这些了,实际上,更准确的说,linux从2.4开始就不再维护独立的”buffer cache”模块了,而是把它的功能并入了”page cache”这个内存管理的子系统了,”buffer cache”现在已经是一个unix系统族的普遍的历史概念了
2“应用层buffer” (C库buffer和用户应用程序的buffer)
回想一下我之前介绍的《IO之内核buffer”buffer cache”》,既然write()能把需要写文件的数据推送到一个内核buffer来偷工减料欺骗应用层(为了加速I/O),说“我已经写完文件并返回了”。那应用层的标准C库的fwrite()按道理也可以为了加速,在真正调用write()之前,把数据放到(FILE*)stream->buffer中,等到多次调用fwrite(),直至(FILE*)stream->buffer中积攒的数据量达到(FILE*)stream->bufferlen这么多的时候,一次性的把这些数据全部送入write()接口,写入内核,这是多么美妙啊。。。
实际上,标准C库就是这么做的!
把fwrite()的linux实现再细致一下
过程其实仍然很粗糙,为了突出buffer的重点,计算stream->buffer是否满,拷贝多少,填充多少这样的细节和主题无关的东西我略去了
size_t fwrite(const void* buffer, size_t size, size_t count, FILE* stream){
…
if( stream->buffer满 ){
write(stream->fd,stream->buffer,stream->bufferlen);
} else{
拷贝buffer内容至stream->buffer
}
…
return count;
//过程很粗糙,为了突出buffer的重点,计算stream->buffer是否满,拷贝多少,填充多少这样的细节和主题无关的东西我略去了
}
fwrite()在windows平台的实现也基本上是这样的,也有buffer。
值得一说的是,fread()也有一个读cache来完成预读。
setvbuf()和setbuf()都是控制这个标准C库的buffer的。
还有fflush()是C库用于flush数据的函数。
以上三个函数,如果大家有兴趣,可以去看看linux上对应的man文档。
重点是要知道不仅系统的内核有buffer,应用层的C库同样也有buffer。这些buffer的唯一作用就是为了加速应用,不让应用老是卡在和磁盘交互上。
说个题外话,实际上对于磁盘、RAID卡、盘阵这样的外存介质而言,他们各自在硬件上也都有一层前端的buffer,有时也叫cache,用来缓冲读写加速。cache越多,价格越贵,性能越好。大型存储设备一般拥有多层cache,用的是昂贵的SSD。
需要分享的一点经验是,不管是标准C库的buffer也好,内核的”buffer cache”也罢,我们终究对它们的控制力度是有限的。我们在做服务器程序的时候,如果业务上涉及太大的I/O量,需要做服务整体加速的时候,我们一般自己在业务层做一层自己的”buffer”,把业务数据buffer住,攒成以文件系统或者磁盘的block块单位的大块数据,然后集中写,然后集中写又有集中写的策略。。。
再引申一点内容,做高性能大流量的大站的架构,其中最重要几个架构角色之一就是cache。前端CDN、后端memcache、redis、mysql内部cache等等,都是cache的应用场景,可以说”buffer cache”在服务器领域从软件实现到硬件加速再到架构,真的是无处不在。
3、raid卡和磁盘缓存
建立阵列的时候(raid5),关于RAID卡缓存的默认选项是:
读取策略:自适应
写策略:回写
磁盘高速缓存策略:禁用
属性解释:
读取策略:一般要启用,采用预读取策略,可提高“随机读取”性能。第二次读取相同数据时可以命中缓存。
写策略:一般要启用“回写”,操作的是RAID卡上的缓存。写入数据时先写入到缓存就算写入成功了,然后RAID卡控制器再把多个写IO合并为一个写IO一次性写入磁盘,提高“随机写入”的性能。因为RAID卡带电池,机房停电时,电池可给缓存供电72小时。缓存中的数据不会丢失。另外,如果没有给缓存接电池,默认“写缓存”是不被启用的(除非强行设定为“没有电池也启用写缓存”)
磁盘高速缓存策略: 操作的是磁盘自带的高速缓存。 做RAID时,一般要禁用,防止机房停电时磁盘自带缓存中的数据丢失。磁盘可不带电池。