视觉-语言双流BERT模型之VilBERT学习笔记
继 2018 年谷歌推出BERT 模型获得巨大成功之后,业界把BERT的思想迁移到视觉、视频任务中的例子越来越多,出现了很多融合的BERT模型。其中,ViLBERT模型是为视觉-语言任务训练非任务专用的视觉语言表征的BERT融合模型。最近,在做文本-视频语义相关性匹配,调研、学习了这篇文章,记录下来学习的笔记,方便后面回顾,温故而知新。
论文作者:Jiasen Lu, Dhruv Batra, Devi Parikh, Stefan Lee(佐治亚理工学院、俄勒冈州立大学、Facebook AI Research)
论文地址:https://www.aminer.cn/pub/5db9297647c8f766461f745b/
论文代码:https://github.com/jiasenlu/vilbert_beta
一、摘要
ViLBERT(Vision-and-Language BERT)模型可以学习视觉内容和文本内容的与特定任务无关的联合表征。ViLBERT在将BERT由单一的文本模态扩展为多模态双流模型。文本流和视觉流通过注意力Transformer层进行交互。首先,在Conceptual Captions数据集进行Pre-train,然后再迁移到视觉问答,视觉常识推理,指示表达(referring expressions)和基于字幕的图像检索这四个视觉-语言任务。在下游任务中使用ViLBERT时,只需要对基础架构进行略微修改即可。论文的实验表明,在4个下游任务中,对比面向各个任务的特定模型,ViLBERT的效果都更优异。
二、Introduction
近年来,通过图像、视频等生成文本的研究已有了很多丰硕的成果,这些方法和任务可归结为“vision-and-language”。虽然这些任务都需要将自然语言和视觉特征结合,但是“vision-and-language”任务还没有一个统一的基础来提升这种结合能力。“vision-and-language”现在通常的做法是先分别pretrain语言和视觉模型,然后针对特征任务进行基础知识的学习。通过这种方法学到的基础知识并不可靠,如果数据量不足或者是有bias的,那么模型的泛化能力会很差。
pretrain 然后transfer的学习方案在视觉和nlp任务中都被广泛运用,对于“vision-and-language”,在运用这种学习方案的同时,将视觉和文本之间的关系考虑进去也同等重要。比如,视觉模型对狗的品种分类,其视觉特征是100%可靠的,但是下游的“vision-and-language”任务无法将之与”小猎犬”或”牧羊人”这样的近似短语进行关联时,再怎么完美的特征,其作用也是近乎于无。因此,这边论文提出一种通用的可以学习到此类联系,并在vision-and-language任务中运用视觉基础模型。即,ViLBERT是面向视觉基础的pretrain。
为了学到vision-language的联合表示,ViLBERT参考了近年来在self-supervised learning方面取得的成果,如 ELMo、BERT、GPT等,通过类似的方法来学习视觉基础知识。文中选用C,onceptual Captions数据集,有330万张图像,每张图像带有弱关联的描述标题。VilBERT的主要创新点在于提出一种双流机制,即分别面向视觉和语言的流,双流在Transformer层交互。这种结构在多模态下能分别对不同的模态进行处理,并提供模态之间的交互。在Conceptual Captions数据集上进行pretrain时的训练目标有两个:(1)给定输入,预测被遮蔽的字和图像区域的语义;(2)预测图像和文本是否语义匹配。在预训练之后将模型四个4个vision-and-language 任务:(1)视觉问答;(2)视觉常识推理;(3)指示表达;(4)基于字幕的图像检索,并且都取得了stat-of-the-art的结果。ViLBERT在各个任务上都提升了2~10个百分点的精度。此外,ViLBERT针对这些任务的修改很简单,所以该模型可以作为跨多个视觉和语言任务的视觉基础。
三、Method
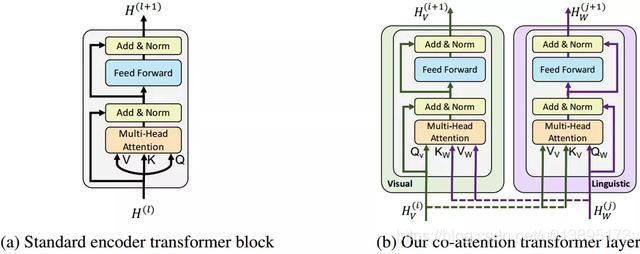
ViLBERT与BERT的对比见于Figure 1。ViLBERT修改BERT中query条件下的key-value注意力机制,将其发展成一个多模态共注意transformer模块。在多头注意力中交换的key-value对,该结构使得vision-attended语言特征能够融入入视觉表征(反之亦然)。
3.1 BERT
BERT的模型架构是基于Vaswani et al. (2017) 中描述的原始实现multi-layer bidirectional Transformer编码器。BERT 利用了 Transformer 的 encoder 部分。Transformer 是一种注意力机制,可以学习文本中单词之间的上下文关系。Transformer 的 encoder 读取全部文本序列,而不是从左到右或从右到左地按顺序读取,使得模型能够基于单词的两侧学习,相当于是一个双向的功能。
3.1.1 BERT输入
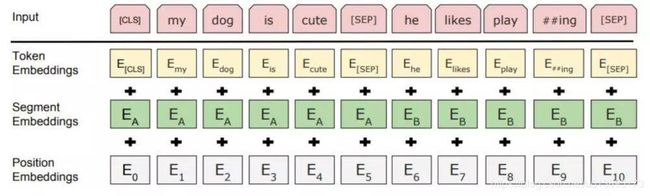
如图2所示,BERT输入由三部分组成,
位置嵌入(Position Embeddings):BERT学习并使用位置嵌入来表达句子中单词的位置。这些是为了克服Transformer的限制而添加的,Transformer与RNN不同,它不能捕获“序列”或“顺序”信息
段嵌入(Segment Embeddings):BERT还可以将句子对作为任务的输入(可用于问答)。这就是为什么它学习第一和第二句话的独特嵌入,以帮助模型区分它们。在图2的例子中,所有标记为EA的标记都属于句子A(对于EB也是一样)
目标词嵌入(Token Embeddings):这些是从WordPiece词汇表中对特定词汇学习到的嵌入
3.1.2 BERT预训练任务
屏蔽语言
训练一个双向的语言模型,将句子中某些词替换成“[MASK]”,这是表示被屏蔽的单词,然后通过句子序列来预测被屏蔽的词。为了防止模型过于关注一个特定的位置或被掩盖的标记,研究人员随机掩盖了15%的单词。掩码字并不总是被掩码令牌[掩码]替换,因为[掩码]令牌在调优期间不会出现因此,研究人员采用了以下方法:
80%的情况下,单词被替换成带面具的令牌[面具]
10%的情况下,这些单词被随机替换
有10%的时间单词是保持不变的
下一句预测
模型接收成对的句子作为输入,并且预测其中第二个句子是否在原始文档中也是后续句子。在训练期间,50% 的输入对在原始文档中是前后关系,另外 50% 中是从语料库中随机组成的,并且是与第一句断开的。
3.2 ViLBERT:联合图像和文本表征的BERT拓展
ViLBERT学习的是静态图像及其对应描述文本的联合表征,分别对两种模态进行建模,然后通过一组attention-based的interaction将它们merge在一起。对每种模态都可使用不同深度的网络,并支持不同深度的跨模态交互。ViLBERT的模型如Figure 3所示。该模型由分别作用于图像块和文本段的2个平行BERT模型组成。每个流都是由一系列的transformer blocks和注意力transformer层组成。其attention层是用以两个模态之间特征融合。需要注意的是,流之间的信息交换是被限制于特定层的,所以,文本流在与视觉特征进行交流之前有更多的处理。这也符合我们的直觉,所选择的视觉特征已经相对高级,与句子中的单词相比,视觉特征需要有限的上下文聚合。

3.2.1 共注意力Transformer层
本文引入的共注意力transformer层如Figure 1b所示。给定vision和language特征,图像模态的keys和values输入到文本模态的attention 单元(反之亦然),attention单元为每一个模态基于另一种模态产生attention-pooled特征,在vision流中表现为基于图像条件的语言attention,在语言流中即语言条件下的vision attention。与BERT一样,attention特征与初始化输出residual 相加。
3.2.2 图像representation
基于一个pretrain的object-detection网络生成图像rpn及其视觉特征。与单词不同,图像的区域是无须的,这篇论文使用一个5-dim的vector对区域进行位置编码,5个元素分别为normal后的bounding boxes的左上角和右下角的坐标以及图像区域的覆盖占比,然后用一个映射将之与视觉特征维数匹配并sum。使用一个特定的图像token作为图像序列的开始,并用它的输出表征整个图像。
3.2.3 预训练任务

训练ViLBERT时采用了2个预训练的任务:
(1)遮蔽多模态建模
与标准BERT一样,对词和图像rpn输入大约15%进行mask,通过余下的输入序列对mask掉的元素进行预测。对图像进行mask时,0.9的概率是直接遮挡,另外0.1的概率保持不变。文本的mask与bert的一致。vilbert并不直接预测被mask的图像区域特征值,而是预测对应区域在语义类别上的分布,使用pretrain的object-detection模型的输出作为ground-truth,以最小化这两个分布的KL散度为目标。
(2)预测多模态对齐
如图4-b所示,其目标是预测图像-文本对是否匹配对齐,即本文是否正确的描述了图像。以图像特征序列的起始IMG token和文本序列的起始CLS token的输出作为视觉和语言输入的整体表征。借用vision-and-language模型中另一种常见结构,将IMG token的输出和CLS token的输出进行element-wise product作为最终的总体表征。再利用一个线性层预测图像和文本是否匹配。
四、Experiment
4.1 pretrain
pretrain在Conceptual Captions数据集上进行,用BERT_base模型对ViLBERT中的语言流进行初始化。使用基于Visual Genome数据集预训练的Faster R-CNN模型抽取图像区域特征。选用类别探测概率高于自信度阈值的区域,并保持10~36个的高分值的bounding boxe。视觉流中的Transformer和共注意力transformer blocks的隐含层大小为1024,注意力头为8个。
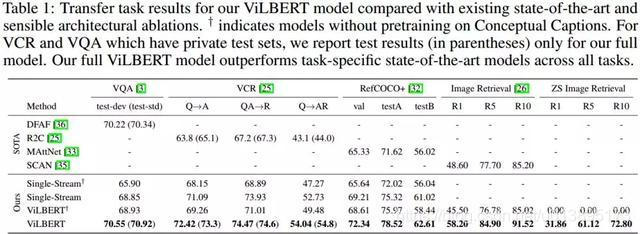
4.2 Vision-and-Language迁移任务
对预训练ViLBERT用4个Vision-and-Language任务和一个诊断任务评测。下游任务的微调策略其实很简单,只需增加一层分类器。这些任务具体分别是:
(1)视觉问答(VQA),使用VQA 2.0数据集;
(2)视觉常识推理(VCR),使用Visual Commonsense Reasoning (VCR)数据集;
(3)指示表达(referring expressions),所谓的指示表达是对给定的自然语言指代找到对应的图像区域。本文使用的是RefCOCO+数据集;
(4)基于字幕的图像检索,使用Flickr30k数据集;
(5)零样本的基于字幕的图像检索。上述任务都是由特定下游数据集微调,在零样本任务中,直接将预训练的ViLBERT应用于Flickr30k数据集中的多模态对齐预测。
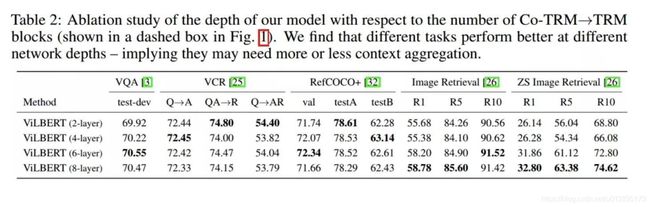
4.3 实验结果