Wide & Deep Learning for Recommender Systems
该文章也是RS很经典的一篇论文,由Google发表,应用于Play Store的Wide&Deep模型。
推荐系统,与搜索排序问题类似,一个挑战是同时实现 记忆 memorization 和 泛化 generalization
Memorization 记忆,可以大致定义为:学习物品或特征的频繁共现,并利用历史数据中的相关性
利用稀疏特征上的 叉乘变换 cross-product transformation 可以有效的实现记忆
Generalization 泛化: 基于相关的传递性,并探索过去很少发生的新特征组合
可以通过使用 粗粒度的特性 less granular features 来添加
基于嵌入的模型 Embedding-based models ,如因子分解机 factorization machines FM、深度神经网络 DNN, 通过学习特征对的低维密集向量,将其推广到之前未见过的特征对
Wide&Deep 模型,联合训练一个线性模型 linear model 部分和一个神经网络 neural network 部分

Google APP 推荐系统概览
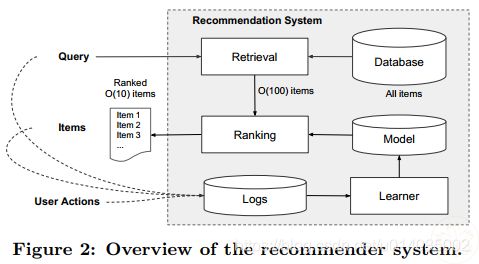
当一个用户访问APP商店时,生成一个包含各种用户和上下文特征的查询推荐系统返回一个app列表,也叫印象 impressions
因为数据量很大,第一步是检索系统 Retrieval 首先返回一个与查询 Query 最佳匹配的短列表,检索系统通常结合机器学习模型和人工定义的规则
在减少候选池 candidate pool 后,排名系统 ranking system 将根据其分数对所有的项目进行排名
得分通常是 P(y|x),给定特征x,用户进行标签y的概率
Wide & Deep 模型
Wide部分
![]()
![]()
特征集合包括原始输入特征和转换的特征,一个最重要的转换 叉乘转换 cross-product transformation

![]()
对于一个二维特性,只有当两个组成特征都是1时,叉乘转换的结果才是1,否则0
![]()
Deep部分
Deep部分是一个 前馈神经网络 feed-forward neural network
对分类特征,其元时输入通常是特征字符串 "language=en"。每个稀疏高维的分类特征首先被转换成一个低维密集实值向量,称为嵌入向量 embedding vector 。其维度通常是 O(10) ~ O(100)
嵌入向首先随机初始化,然后对其值进行训练,使最终的损失函数值最小。这些低维密集嵌入向量送入神经网络的前项通道中的隐藏层,每个隐层计算:
![]()
其中l为层数,f是激活函数,通常为 ReLU,a、b、w 分别是l层的激活函数、偏置项、模型权重
联合训练部分
将两个部分的输出概率 output log odds 的加权和 weighted sum 作为预测 prediction ,将其输入到一个共同的逻辑损失函数 logistics loss function 中进行联合训练 joint training
Joint training 和 ensemble 之间的区别:
ensemble中,单独的模型被单独训练并不互相了解,其预测只在推断的时候 inference time 结合,不是在训练的时候
Joint training中,联合训练在训练时同时考虑wide和deep部分以及他们的和的权重来优化所有参数
对于模型尺寸也存在影响:
ensemble中,由于训练是不相关的,每个单独模型的尺寸通常需要更大,具有更多的特征和转换来实现集成的准确性
对于联合训练来说,weed部分只需要通过少量的叉乘特征转换 cross-product feature transformation 来弥补deep部分的不足,而不是一个全尺寸的wide模型
联合训练模型使用mini-batch随机优化,同时将梯度反向传播到模型的wide和deep部分。使用带L1正则化的FTRL作为wide部分优化器,AdaGrad作为deep部分优化器
对一个逻辑回归问题,模型的预测:
![]()
![]()
系统实现
整个APP推荐流程由三个部分组成:数据生成,模型训练,模型服务

模型训练部分

wide部分包括用户安装的APP和有印象的APP的叉乘转换;deep部分,对每种特征学习一个32维的嵌入向量
将所有的嵌入与密集特征连接在一起,生成一个大约1200维的嵌入,该向量输入3层ReLU中,最后是一个逻辑输出单元
相关工作
[5] 通过将两个变量之间的相互作用分解为两个低维嵌入向量之间的点积,从而为线性模型增加了泛化 generalization
[7] 协同深度学习, 将内容信息的深度学习与评分矩阵的协同过滤结合
总结
记忆 memorization 和 泛化 generalization 对推荐系统都很重要。
Wide 线性模型能够通过 叉乘特征转换 cross-product feature transformation 有效记忆稀疏特征交互;
Deep DNN能够通过低维嵌入,将未见过的特征交互泛化。
Wide & Deep 模型结合了两者的优点。
参考文献
[5] S. Rendle. Factorization machines with libFM. ACM Trans. Intell. Syst. Technol., 3(3):57:1{57:22, May 2012.
[7] H. Wang, N. Wang, and D.-Y. Yeung. Collaborative deep learning for recommender systems. In Proc. KDD, pages 1235{1244, 2015.