文章阅读:F-PointNet +代码复现
Brief
这是笔者看3D检测的第二篇文章,第一篇是18年CVPR的VoxelNet,这一篇同样是18年的CVPR,第一作者就是PointNet和Pointnet++的作者,这一篇算是后续作品。二三作者也是大佬,分别是Wei Liu(SSD,DSSD),Hao Su。
个人总结本文的亮点有:
- 原始数据输入,保留了原始特征和点云不变性特征(在voxel中存在的问题)。
- 坐标转换和对其思想的使用,对本文的效果起了绝对性的作用。
但是依旧没有解决的问题是:
- 一个很好的为了学习到更好的3D几何特性的几何变换关系。
- 阶段性导致了效果的不整体
- F-PointNet假设一个frustum中只存在一个instance,这对一些密集区域的segmentation是不利的。
- 受到串行结构的影响,F-PointNet中3d box estimation的结果严重依赖于2d detection,并且RGB信息对整个结构是至关重要的。然而,图像受到光照以及前后遮挡的影响,会导致2d detector出现漏检的情况。
- 有的结构可能只能在3D中才能被看到,一些小的被遮挡住的。
个人思考
参考知乎的回答
- 1.F-PointNet也同时利用了RGB图像与点云,但不同的是F-PointNet没有对两类信息分别处理(并行)并进行fusion,而是使用了2d-driven 3d object detection(串行)的方式。
这么做的好处在于:(1)舍弃了global fusion,提高了检测效率;并且通过2D detector和3D Instance Segmentation PointNet对3D proposal实现了逐维(2D-3D)的精准定位,大大缩短了对点云的搜索时间。
(2)相比于在BEV(Bird’s Eye view)中进行3D detection,F-PointNet直接处理raw point cloud,没有任何维度的信息损失,使用PointNet能够学习更全面的空间几何信息,特别是在小物体的检测上有很好的表现。
(3)利用成熟的2D detector对proposal进行分类(one-hot class vector,打标签),起到了一定的指导作用,能够大大降低PointNet对三维空间物体的学习难度。
Abstruct
- 我们输入的是RGB-D,处理的是indor和outdoor场景。
- 之前的算法都是采用的voxel,这会模糊掉原始数据的本质特征和3D数据的不变性
这里引入的
invariances of 3D data这个特性,在文章Pointnet 中有提及,含义是点云具有无序性,点云是一个集合,对数据的顺序是不敏感的。而一般的voxel方式强行给点加入了坐标信息。
- 不仅仅单独使用3D候选框,也结合成熟的2D检测方法和先进的3D方法对物体进行定位,达到高的recall,即使是对小的物体。
- 由于该方法直接学习原始数据,我们可以存在很大干扰并且稀疏的点云中精确的定位3D-BBOX,在KITTI的RGEB-D数据中,我们是sota的结果。
Introduction
提出了一个悬而未解的问题:如何表达3D点云和采用何种结构。
how to represent point cloud and what deep net architectures to use for 3D object detection remains an open problem.
目前的处理方法:
- voxel和mv:模糊了原始数据的本质特性和旋转不变性。
- 直接处理点云的,比如PointNet和PointNet++,但是不能确定这个方法能不能处理instance-level的问题。(果然作者不得指出前面自己的文章的问题,哈哈哈)
那么如何提出精准的候选框:
- 滑动窗口的方式(17ICRA)(加入paperlist)
- 3D RPN的方式。
基于3D搜索的方式会导致计算复杂度大大增加。因此作者就顺理成章的引入了自己的贡献: - 作者通过降维的方式降低数据搜索空间。如下图所示,首先通过2D的CNN选出一个候选框生成视锥,然后通过RGB-D数据得到的点云数据中来得到3D BOX。最后使用两个Pointnet的变形来进行回归。
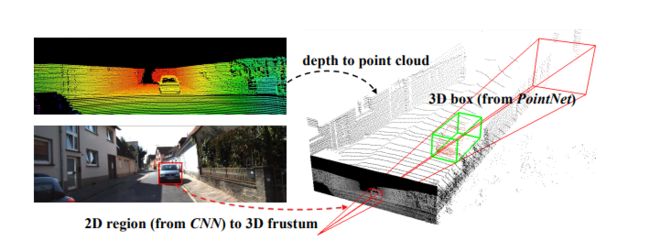
- 和以前直接只使用2DRGB数据不一样的是,我们的方法是以3D数据为中心的。在我们的结构中,第一,一个变换关系成功的应用在了3D坐标上,将点云对齐成一系列更受约束和规范的帧。这个对齐将数据中的姿态变换排除在外,从而使3D几何图案更加明显,从而使3D学习者的工作更轻松。第二,学习3D数据可以更加挖掘到几何和拓扑结构。因此,我们相信一些特征结构,比如planarity,repetition和symmetry能够自然的最挖挖掘到。
- 本文的贡献:
- We propose a novel framework for RGB-D data based3D object detection called Frustum PointNets.
- We show how we can train 3D object detectors under our framework and achieve state-of-the-art performance on standard 3D object detection benchmarks。
- We provide extensive quantitative evaluations to validate our design choices as well as rich qualitative results for understanding the strengths and limitations of our method
2 Related work
2.1 3D Object Detection from RGB-D Data
Front view image based methods:
- (1)采用单目RGB图像和形状先验或 occlusion patterns 来推断3D边界框。
这里的 occlusion patterns 是个什么意思,这里稍微查看了一下参考文献39的内容。大致的意思就是先通过遮挡住自己不想要的图像部分,提取目标(车辆)的部分进行3D CAD建模。
- (2)深度数据应用为2D数据,并采用CNN进行卷积,我们与之不同的是,我们把深度数据应用为point。
Bird’s eye view based methods
- MV3D (后面接触),直接采用lidar数据鸟视图,训练出来一个PRN对3Dbbox 进行提出。但是该方法对小物体,例如行人和自行车。同时不能在垂直方向上适用于很多物体。
3D based methods
- 手工特征+SVM+slide window。
- 手工特征+3DCNN (Vote3Deep_ICRA17)+slide_window
- 3D 体素CNN等等等
上诉方法的很大 问题点在于:
Computation cost for those method is usually quite high due to the expensive cost of 3D convolutions
and large 3D search space.
- ICCV2017上的一篇(2d-driven 3d object detection in rgb-d images)和该文章的想法类似。就是通过一种降维的方式去降低计算复杂度。同时提高数据特性。但是,它是用的手工特征,这在逼格上就差一大截了。
2.2 Deep Learning on Point Clouds
吹一下自己的工作,pointnet ,并且表示这是第一篇采用pointnet做检测的文章。
3. Problem Definition
RGB-D相机的depteh数据是以点云的形式储存的,同时会存在着3D点到2D RGB相机的转换矩阵,因此视锥就可以从2D区域再加上一个转化得到。每个对象由一个class和一个amode 3D bbox决定。amode box会框出这么一个物体范围,尽管物体可能出现遮盖或者被裁剪。一个Box由7个维度表示: [ c x , c y , c z , h , w , l , θ ] [c_x,c_y,c_z,h,w,l,\theta] [cx,cy,cz,h,w,l,θ]表示。
4. 3D Detection with Frustum PointNets
我们的方法包括三个部分:
- frustum proposal
- 3D instance segmentation
- 3D amodal bounding box estimation
plpline如下图所示:

大致的流程是:(1)我们首先利用2D CNN detector来提出2D区域并对其内容进行分类。(2)将2D转化到3D 视锥proposals(3)假设视锥中含有的点的个数是 n × 3 n \times 3 n×3,经过一个实例分割网络得到 m × 3 m \times 3 m×3的点,也就是 amodal 3D.(4)再采用一个T-NET对Amodal 3D Box进行预测,使其和标准的3D Box质心大致在一个位置上。
4.1 Frustum Proposal
- 采用2D成熟的检测技术对RGB图像进行备选区域提出和分类。
第一步,根据2D box 和转化关系我们可以得到视锥。第二步,收集在这个视锥下的所有点,根据视锥可以有很多不同的朝向,这会导致在点云的palcement上有很大的变化。第三步,我们将它们朝向中心视图旋转来归一化视锥,这会使得视锥的中心轴和相机平面正交。这个旋转可以增强我们这个方法的旋转不变性。这一部分操作叫做a frustum proposal generation。下图(a),(b)表示。

- 具体的2D detection我们采用的是基于FPN的架构,细节会在补充材料描述
4.2. 3D Instance Segmentation
一些可以考虑的通过2D iMage获取3D location的方法:
- 直接对3Dbbox回归:由于遮盖物和 background clutter的存在,导致了这个直接法存在困难。如下:

上图左图是一个人的2D候选框,右图是llidar数据中的鸟视图,我们看到有很多的建筑物的点自行车的点。这导致我们对这个行人做box回归有很大的问题。
作者考虑到一个先验知识物体在3D场景中是自然分离的,这比在2Dimage上做分割可是要简单一些,因为2D上并不是邻近的物体可能在像素上也是很接近的。所以作者采取了做实例分割的方式。类似于Mask-R-CNN对候选区域中的像素点的二分类,我们的方法是基于PointNet的分割网络,在视锥中进行分割。
进一步说,作者预测的是残差(大家不都这样的嘛),并且在3D mask coordinates 中预测的3D bbox的中心。上上个图的图©表示。
3D Instance Segmentation PointNet.
上面说的方法采用的是基于pointnet的方法;就是在一整个视锥的点云中分出需要的那个对象。这里我们的一个视锥中只有一个需要的对象,对每一个点进行分类,要么是object要么是无关的。我们的segmentation PointNet 就是学习分类属于object和occlusion and clutter。
同样我们使用来自2D分割上的先验知识,假设这个是一个行人分割,我们会告诉3D这是一个行人,它再根据几何形状去分割这些点云。特别地,我们采用one-hot编码的方式编码分类的类别。
经过分割,感兴趣的点会被提取出来,也就是文章所说的"masking";下面我们也同样的标准化坐标,这样同样是为了提高算法对旋转的不变性。 在我们的实现中,我们通过按质心减去XYZ值,将点云转换为局部坐标 。上上图表示了©.请注意,我们故意不对点云进行缩放,因为部分点云的边界球大小可能会受到viewpoint的极大影响,并且点云的实际大小有助于框大小估计。
作者说出来一个很关键的点,旋转对齐对点云的学习非常重要,文章上述了两种坐标旋转都是很重要的,其重要程度可以表现在如下:

文章上述的两个转换分被对应着:frustum rot和 mask centralize。(可以借鉴)
4.3. Amodal 3D Box Estimation
输入为3D mask coordinate,这个模块预测3DBBOX的旋转,使用的是基于pointnet的回归网络。
4.3.1 Learning-based 3D Alignment by T-Net
尽管已经根据中心点对齐了分割后物体点,我们依然发现最原始的mask的坐标帧(c表示)依旧和amodel centre远远不一样。因此,我们建议使用轻量级回归PointNet(T-Net)来估计整个物体的真实中心,然后变换坐标,使预测的中心成为原点。
T-Net的结构和训练方式和pointnet一样的,可以理解为一个STN;和STN不一样在于这个T-Net有一个直接的监督,而STN没有。我们明确监督我们的翻译网络,以预测从masking坐标原点到真实物体中心的中心残差。
4.3.2Amodal 3D Box Estimation PointNet
box回归预测amode bbox(即使是部分,也要框出全部来),网络结构和pointnet很相似,但是输出是3D bbox的参数。我们采用预测“residual”的方式对中心坐标进行预测。这个box残差的预测来自之前 T-Net和masked points’ centroid的残差组合。作者定义了 N S NS NS个size的模板和 N H NH NH个angel bins。最后要预测所用category不同size的参数,也就是 3 × N S 3\times NS 3×NS个残差对 h , l , w ; h,l,w; h,l,w; N H NH NH个朝向角度对 θ \theta θ;最后网络的输出是:
3 + 4 × N S + 2 × N H 3 + 4 × NS + 2 × NH 3+4×NS+2×NH个参数。
稍微理解一下含义。
4.4 Training with Multi-task Losses
上述的3个网络:
- 3D instance segmentation PointNet
- T-Net
- amodal box estimation PointNet
我们同时优化,采用多任务组合的网络损失函数。
L multi-task = L seg + λ ( L c 1 − r e g + L c 2 − r e g + L h − c l s + L h − r e g + L s − c l s + L s − r e g + γ L corner ) \begin{aligned} L_{\text {multi-task}}=& L_{\text {seg}}+\lambda\left(L_{c 1-r e g}+L_{c 2-r e g}+L_{h-c l s}+\right.\\ &\left.L_{h-r e g}+L_{s-c l s}+L_{s-r e g}+\gamma L_{\text {corner}}\right) \end{aligned} Lmulti-task=Lseg+λ(Lc1−reg+Lc2−reg+Lh−cls+Lh−reg+Ls−cls+Ls−reg+γLcorner)
Corner Loss for Joint Optimization of Box Parameters
虽然我们的3D边界框参数化非常紧凑且完整,但学习并未针对最终3D box精度进行优化 - 中心,大小和朝向都有单独的损失项。想象一下中心和大小准确预测但航向角度偏离的情况 - 具有地面实况框的3D IoU将由角度误差支配。理想情况下,所有三个术语(中心,大小,朝向)应联合优化,以实现最佳3D bbox估计(在IoU度量下)。
因此作者提出了一下新的损失项 c o r n e r − l o s s corner -loss corner−loss:
L corner = ∑ i = 1 N S ∑ j = 1 N H δ i j min { ∑ k = 1 8 ∥ P k i j − P k ∗ ∥ , ∑ i = 1 8 ∥ P k i j − P k ∗ ∗ ∥ } L_{\text {corner}}=\sum_{i=1}^{N S} \sum_{j=1}^{N H} \delta_{i j} \min \left\{\sum_{k=1}^{8}\left\|P_{k}^{i j}-P_{k}^{*}\right\|, \sum_{i=1}^{8}\left\|P_{k}^{i j}-P_{k}^{* *}\right\|\right\} Lcorner=i=1∑NSj=1∑NHδijmin{k=1∑8∥∥∥Pkij−Pk∗∥∥∥,i=1∑8∥∥∥Pkij−Pk∗∗∥∥∥}
corner -loss是预测框和地面实况框的八个角之间的距离之和。 由于角位置由中心,大小和方向共同决定,corner -loss能够使这些参数的多任务训练正规化。
我们在预先会定义 N S × N H NS ×NH NS×NH个anchors,其中 N S NS NS表示size,而 N H NH NH表示的是角度
这里的 P k i j P_k^{ij} Pkij含义表示为:
- i i i:第 i i i个size
- j j j:第 j j j个朝向
- k k k:第 k k k个cornor
为避免翻转航向估算造成大的损失,我们进一步说明
计算从翻转的地面实况框到角落的距离( P k ∗ ∗ P^{ **}_ k Pk∗∗),并使用原始和翻转的最小值。
δ i j \delta_{ij} δij:如下,也就是一个用于attention机制的意思。
δ i j \delta_{ij} δij , which is one for the ground truth size/heading class and zero else wise, is a two-dimensional mask used toselect the distance term we care about
代码复现
这里是 code
代码复现主要两点内容:
- 代码怎么跑起来
- 代码重要点解读