IO写流程分析
IO写流程分析
IO 写流程图示: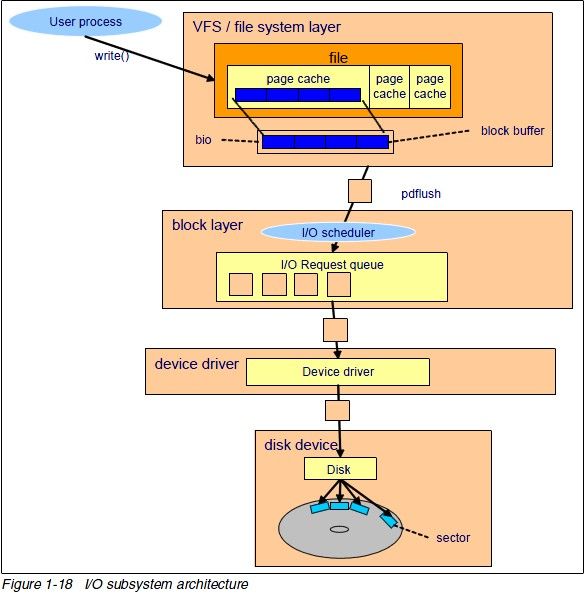
系统调用
read系统调用的处理分为用户空间和内核空间处理两部分。其中,用户空间处理只是通过0x80中断陷入内核,接着调用其中断服务例程,即sys_read以进入内核处理流程。
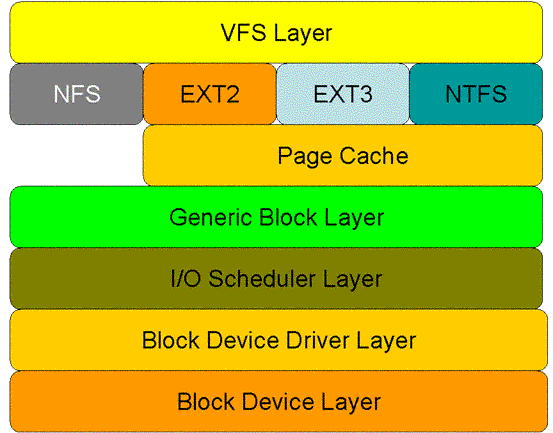
对于read系统调用在内核的处理,如上图所述,经过了VFS、具体文件系统,如ext2、页高速缓冲存层、通用块层、IO调度层、设备驱动层、和设备层。其中,VFS主要是用来屏蔽下层具体文件系统操作的差异,对上提供一个统一接口,正是因为有了这个层次,所以可以把设备抽象成文件。具体文件系统,则定义了自己的块大小、操作集合等。引入cache层的目的,是为了提高IO效率。它缓存了磁盘上的部分数据,当请求到达时,如果在cache中存在该数据且是最新的,则直接将其传递给用户程序,免除了对底层磁盘的操作。通用块层的主要工作是,接收上层发出的磁盘请求,并最终发出IO请求(BIO)。IO调度层则试图根据设置好的调度算法对通用块层的bio请求合并和排序,回调驱动层提供的请求处理函数,以处理具体的IO请求。驱动层的驱动程序对应具体的物理设备,它从上层取出IO请求,并根据该IO请求中指定的信息,通过向具体块设备的设备控制器发送命令的方式,来操纵设备传输数据。设备层都是具体的物理设备。
VFS层:
内核函数sys_read是read系统调用在该层的入口点。它根据文件fd指定的索引,从当前进程描述符中取出相应的file对象,并调用vfs_read执行文件读取操作。vfs_read会调用与具体文件相关的read函数执行读取操作,file->f_op.read。然后,VFS将控制权交给了ext2文件系统。(ext2在此作为示例,进行解析)
pdflush
在linux操作系统中,写操作是异步的,即写操作返回的时候数据并没有真正写到磁盘上,而是先写到了系统cache里,随后由pdflush内核线程将系统中的脏页写到磁盘上,在下面几种情况下,
系统会唤醒pdflush回写脏页:
- 定时方式:
定时机制定时唤醒pdflush内核线程,周期为/proc/sys/vm/dirty_writeback_centisecs ,单位
是(1/100)秒,每次周期性唤醒的pdflush线程并不是回写所有的脏页,而是只回写变脏时间超过
/proc/sys/vm/dirty_expire_centisecs(单位也是1/100秒)。
注意:变脏的时间是以文件的inode节点变脏的时间为基准的,也就是说如果某个inode节点是10秒前变脏的,
pdflush就认为这个inode对应的所有脏页的变脏时间都是10秒前,即使可能部分页面真正变脏的时间不到10秒,
细节可以查看内核函数wb_kupdate()。 - 内存不足的时候:
这时并不将所有的dirty页写到磁盘,而是每次写大概1024个页面,直到空闲页面满足需求为止。 - 写操作时发现脏页超过一定比例:
当脏页占系统内存的比例超过 /proc/sys/vm/dirty_background_ratio 的时候,write系统调用会唤醒
pdflush回写dirty page,直到脏页比例低于/proc/sys/vm/dirty_background_ratio,但write系统调
用不会被阻塞,立即返回。当脏页占系统内存的比例超过/proc/sys/vm/dirty_ratio的时候, write系
统调用会被被阻塞,主动回写dirty page,直到脏页比例低于/proc/sys/vm/dirty_ratio,这一点在
2.4内核中是没有的。 - 用户调用sync系统调用:
这是系统会唤醒pdflush直到所有的脏页都已经写到磁盘为止。
IO Scheduler
每个块设备或者块设备的分区,都对应有自身的请求队列(request_queue),而每个请求队列都可以选择一个I/O调度器来协调所递交的request。I/O调度器的基本目的是将请求按照它们对应在块设备上的扇区号进行排列,以减少磁头的移动,提高效率。每个设备的请求队列里的请求将按顺序被响应。实际上,除了这个队列,每个调度器自身都维护有不同数量的队列,用来对递交上来的request进行处理,而排在队列最前面的request将适时被移动到请求队列中等待响应。
内核中实现的IO调度器主要有四种–Noop,Deadline,CFG, Anticipatory。
1. Noop算法
Noop调度算法是内核中最简单的IO调度算法。Noop调度算法也叫作电梯调度算法,它将IO请求放入到一个FIFO队列中,然后逐个执行这些IO请求,当然对于一些在磁盘上连续的IO请求,Noop算法会适当做一些合并。这个调度算法特别适合那些不希望调度器重新组织IO请求顺序的应用。
这种调度算法在以下场景中优势比较明显:
1)在IO调度器下方有更加智能的IO调度设备。如果您的Block Device Drivers是Raid,或者SAN,NAS等存储设备,这些设备会更好地组织IO请求,不用IO调度器去做额外的调度工作;
2)上层的应用程序比IO调度器更懂底层设备。或者说上层应用程序到达IO调度器的IO请求已经是它经过精心优化的,那么IO调度器就不需要画蛇添足,只需要按序执行上层传达下来的IO请求即可。
3)对于一些非旋转磁头氏的存储设备,使用Noop的效果更好。因为对于旋转磁头式的磁盘来说,IO调度器的请求重组要花费一定的CPU时间,但是对于SSD磁盘来说,这些重组IO请求的CPU时间可以节省下来,因为SSD提供了更智能的请求调度算法,不需要内核去画蛇添足。这篇文章提及了SSD中使用Noop效果会更好。
2. Deadline算法
Deadline算法的核心在于保证每个IO请求在一定的时间内一定要被服务到,以此来避免某个请求饥饿。
Deadline算法中引入了四个队列,这四个队列可以分为两类,每一类都由读和写两类队列组成,一类队列用来对请求按起始扇区序号进行排序,通过红黑树来组织,称为sort_list;另一类对请求按它们的生成时间进行排序,由链表来组织,称为fifo_list。每当确定了一个传输方向(读或写),那么将会从相应的sort_list中将一批连续请求dispatch到requst_queue的请求队列里,具体的数目由fifo_batch来确定。只有下面三种情况才会导致一次批量传输的结束:
1)对应的sort_list中已经没有请求了
2)下一个请求的扇区不满足递增的要求
3)上一个请求已经是批量传输的最后一个请求了。
所有的请求在生成时都会被赋上一个期限值(根据jiffies),并按期限值排序在fifo_list中,读请求的期限时长默认为为500ms,写请求的期限时长默认为5s,可以看出内核对读请求是十分偏心的,其实不仅如此,在deadline调度器中,还定义了一个starved和writes_starved,writes_starved默认为2,可以理解为写请求的饥饿线,内核总是优先处理读请求,starved表明当前处理的读请求批数,只有starved超过了writes_starved后,才会去考虑写请求。因此,假如一个写请求的期限已经超过,该请求也不一定会被立刻响应,因为读请求的batch还没处理完,即使处理完,也必须等到starved超过writes_starved才有机会被响应。为什么内核会偏袒读请求?这是从整体性能上进行考虑的。读请求和应用程序的关系是同步的,因为应用程序要等待读取的内容完毕,才能进行下一步工作,因此读请求会阻塞进程,而写请求则不一样,应用程序发出写请求后,内存的内容何时写入块设备对程序的影响并不大,所以调度器会优先处理读请求。
默认情况下,读请求的超时时间是500ms,写请求的超时时间是5s。
这篇文章说在一些多线程应用下,Deadline算法比CFQ算法好。这篇文章说在一些数据库应用下,Deadline算法比CFQ算法。
3. Anticipatory算法
Anticipatory算法的核心是局部性原理,它期望一个进程昨晚一次IO请求后还会继续在此处做IO请求。在IO操作中,有一种现象叫“假空闲”(Deceptive idleness),它的意思是一个进程在刚刚做完一波读操作后,看似是空闲了,不读了,但是实际上它是在处理这些数据,处理完这些数据之后,它还会接着读,这个时候如果IO调度器去处理另外一个进程的请求,那么当原来的假空闲进程的下一个请求来的时候,磁头又得seek到刚才的位置,这样大大增加了寻道时间和磁头旋转时间。所以,Anticipatory算法会在一个读请求做完后,再等待一定时间t(通常是6ms),如果6ms内,这个进程上还有读请求过来,那么我继续服务,否则,处理下一个进程的读写请求。
在一些场景下,Antocipatory算法会有非常有效的性能提升。这篇文章有说,这篇文章也有一份评测。
值得一提的是,Anticipatory算法从Linux 2.6.33版本后,就被移除了,因为CFQ通过配置也能达到Anticipatory算的效果。
4. CFQ算法
CFQ(Completely Fair Queuing)算法,顾名思义,绝对公平算法。它试图为竞争块设备使用权的所有进程分配一个请求队列和一个时间片,在调度器分配给进程的时间片内,进程可以将其读写请求发送给底层块设备,当进程的时间片消耗完,进程的请求队列将被挂起,等待调度。 每个进程的时间片和每个进程的队列长度取决于进程的IO优先级,每个进程都会有一个IO优先级,CFQ调度器将会将其作为考虑的因素之一,来确定该进程的请求队列何时可以获取块设备的使用权。IO优先级从高到低可以分为三大类:RT(real time),BE(best try),IDLE(idle),其中RT和BE又可以再划分为8个子优先级。实际上,我们已经知道CFQ调度器的公平是针对于进程而言的,而只有同步请求(read或syn write)才是针对进程而存在的,他们会放入进程自身的请求队列,而所有同优先级的异步请求,无论来自于哪个进程,都会被放入公共的队列,异步请求的队列总共有8(RT)+8(BE)+1(IDLE)=17个。
从Linux 2.6.18起,CFQ作为默认的IO调度算法。
对于通用的服务器来说,CFQ是较好的选择。
对于使用哪种调度算法来说,还是要根据具体的业务场景去做足benchmark来选择,不能仅靠别的文字来决定。
5. 更改IO调度算法
在RHEL5/OEL5以及之后的版本中(比如RHEL6和RHEL7),可以针对每块磁盘制定I/O Scheduler,修改完毕立刻生效,比如:
$ cat /sys/block/sda1/queue/scheduler
[noop] anticipatory d#dline cfq
#修改为cfq
$ echo 'cfq'>/sys/block/sda1/queue/scheduler
#立刻生效
$ cat /sys/block/sda1/queue/scheduler
noop anticipatory deadline [cfq]
6. 一些磁盘相关的内核参数
/sys/block/sda/queue/nr_requests 磁盘队列长度。默认只有 128 个队列,可以提高到 512 个.会更加占用内存,但能更加多的合并读写操作,速度变慢,但能读写更加多的量
/sys/block/sda/queue/iosched/antic_expire 等待时间 。读取附近产生的新请时等待多长时间
/sys/block/sda/queue/read_ahead_kb
这个参数对顺序读非常有用,意思是,一次提前读多少内容,无论实际需要多少.默认一次读 128kb 远小于要读的,设置大些对读大文件非常有用,可以有效的减少读 seek 的次数,这个参数可以使用 blockdev –setra 来设置,setra 设置的是多少个扇区,所以实际的字节是除以2,比如设置 512 ,实际是读 256 个字节.
/proc/sys/vm/dirty_ratio
这个参数控制文件系统的文件系统写缓冲区的大小,单位是百分比,表示系统内存的百分比,表示当写缓冲使用到系统内存多少的时候,开始向磁盘写出数 据.增大之会使用更多系统内存用于磁盘写缓冲,也可以极大提高系统的写性能.但是,当你需要持续、恒定的写入场合时,应该降低其数值,一般启动上缺省是 10.下面是增大的方法: echo ’40’>
/proc/sys/vm/dirty_background_ratio
这个参数控制文件系统的pdflush进程,在何时刷新磁盘.单位是百分比,表示系统内存的百分比,意思是当写缓冲使用到系统内存多少的时候, pdflush开始向磁盘写出数据.增大之会使用更多系统内存用于磁盘写缓冲,也可以极大提高系统的写性能.但是,当你需要持续、恒定的写入场合时,应该降低其数值,一般启动上缺省是 5.下面是增大的方法: echo ’20’ >
/proc/sys/vm/dirty_writeback_centisecs
这个参数控制内核的脏数据刷新进程pdflush的运行间隔.单位是 1/100 秒.缺省数值是500,也就是 5 秒.如果你的系统是持续地写入动作,那么实际上还是降低这个数值比较好,这样可以把尖峰的写操作削平成多次写操作.设置方法如下: echo ‘200’ > /proc/sys/vm/dirty_writeback_centisecs 如果你的系统是短期地尖峰式的写操作,并且写入数据不大(几十M/次)且内存有比较多富裕,那么应该增大此数值: echo ‘1000’ > /proc/sys/vm/dirty_writeback_centisecs
/proc/sys/vm/dirty_expire_centisecs
这个参数声明Linux内核写缓冲区里面的数据多“旧”了之后,pdflush进程就开始考虑写到磁盘中去.单位是 1/100秒.缺省是 30000,也就是 30 秒的数据就算旧了,将会刷新磁盘.对于特别重载的写操作来说,这个值适当缩小也是好的,但也不能缩小太多,因为缩小太多也会导致IO提高太快.建议设置为 1500,也就是15秒算旧. echo ‘1500’ > /proc/sys/vm/dirty_expire_centisecs 当然,如果你的系统内存比较大,并且写入模式是间歇式的,并且每次写入的数据不大(比如几十M),那么这个值还是大些的好.
IO性能分析命令
近期要在公司内部做个Linux IO方面的培训, 整理下手头的资料给大家分享下
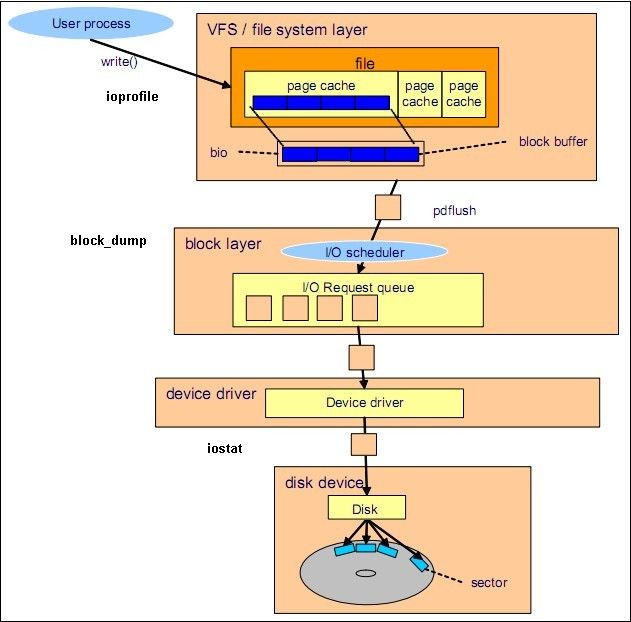
各种IO监视工具在Linux IO 体系结构中的位置
源自 Linux Performance and Tuning Guidelines.pdf
1 系统级IO监控
iostat
iostat -xdm 1 # 个人习惯

%util 代表磁盘繁忙程度。100% 表示磁盘繁忙, 0%表示磁盘空闲。但是注意,磁盘繁忙不代表磁盘(带宽)利用率高
argrq-sz 提交给驱动层的IO请求大小,一般不小于4K,不大于max(readahead_kb, max_sectors_kb)
可用于判断当前的IO模式,一般情况下,尤其是磁盘繁忙时, 越大代表顺序,越小代表随机
svctm 一次IO请求的服务时间,对于单块盘,完全随机读时,基本在7ms左右,既寻道+旋转延迟时间
注: 各统计量之间关系
=======================================
%util = ( r/s + w/s) * svctm / 1000 # 队列长度 = 到达率 * 平均服务时间
avgrq-sz = ( rMB/s + wMB/s) * 2048 / (r/s + w/s) # 2048 为 1M / 512
=======================================
总结:
iostat 统计的是通用块层经过合并(rrqm/s, wrqm/s)后,直接向设备提交的IO数据,可以反映系统整体的IO状况,但是有以下2个缺点:
1 距离业务层比较遥远,跟代码中的write,read不对应(由于系统预读 + pagecache + IO调度算法等因素, 也很难对应)
2 是系统级,没办法精确到进程,比如只能告诉你现在磁盘很忙,但是没办法告诉你是谁在忙,在忙什么?
2 进程级IO监控
iotop 和 pidstat (仅rhel6u系列)
iotop 顾名思义, io版的top
pidstat 顾名思义, 统计进程(pid)的stat,进程的stat自然包括进程的IO状况
这两个命令,都可以按进程统计IO状况,因此可以回答你以下二个问题
-
- 当前系统哪些进程在占用IO,百分比是多少?
- 占用IO的进程是在读?还是在写?读写量是多少?
pidstat 参数很多,仅给出几个个人习惯
pidstat -d 1 #只显示IO
![]()
pidstat -u -r -d -t 1 # -d IO 信息,
# -r 缺页及内存信息
# -u CPU使用率
# -t 以线程为统计单位
# 1 1秒统计一次
iotop, 很简单,直接敲命令
block_dump, iodump
iotop 和 pidstat 用着很爽,但两者都依赖于/proc/pid/io文件导出的统计信息, 这个对于老一些的内核是没有的,比如rhel5u2
因此只好用以上2个穷人版命令来替代:
echo 1 > /proc/sys/vm/block_dump # 开启block_dump,此时会把io信息输入到dmesg中
# 源码: submit_bio@ll_rw_blk.c:3213
watch -n 1 “dmesg -c | grep -oP “\w+\d+\d+: (WRITE|READ)” | sort | uniq -c”
# 不停的dmesg -c
echo 0 > /proc/sys/vm/block_dump # 不用时关闭
也可以使用现成的脚本 iodump, 具体参见 http://code.google.com/p/maatkit/source/browse/trunk/util/iodump?r=5389
iotop.stp
systemtap脚本,一看就知道是iotop命令的穷人复制版,需要安装Systemtap, 默认每隔5秒输出一次信息
stap iotop.stp # examples/io/iotop.stp
总结
进程级IO监控 ,
- 可以回答系统级IO监控不能回答的2个问题
- 距离业务层相对较近(例如,可以统计进程的读写量)
但是也没有办法跟业务层的read,write联系在一起,同时颗粒度较粗,没有办法告诉你,当前进程读写了哪些文件? 耗时? 大小 ?
3 业务级IO监控
ioprofile
ioprofile 命令本质上是 lsof + strace, 具体下载可见 http://code.google.com/p/maatkit/
ioprofile 可以回答你以下三个问题:
1 当前进程某时间内,在业务层面读写了哪些文件(read, write)?
2 读写次数是多少?(read, write的调用次数)
3 读写数据量多少?(read, write的byte数)
假设某个行为会触发程序一次IO动作,例如: “一个页面点击,导致后台读取A,B,C文件”
============================================
./io_event # 假设模拟一次IO行为,读取A文件一次, B文件500次, C文件500次
ioprofile -p pidof io_event -c count # 读写次数

ioprofile -p pidof io_event -c times # 读写耗时

ioprofile -p `pidof io_event` -c sizes # 读写大小

注: ioprofile 仅支持多线程程序,对单线程程序不支持. 对于单线程程序的IO业务级分析,strace足以。
总结:
ioprofile本质上是strace,因此可以看到read,write的调用轨迹,可以做业务层的io分析(mmap方式无能为力)
4 文件级IO监控
文件级IO监控可以配合/补充"业务级和进程级"IO分析
文件级IO分析,主要针对单个文件, 回答当前哪些进程正在对某个文件进行读写操作.
1 lsof 或者 ls /proc/pid/fd
2 inodewatch.stp
lsof 告诉你 当前文件由哪些进程打开
lsof …/io # io目录 当前由 bash 和 lsof 两个进程打开

lsof 命令 只能回答静态的信息, 并且"打开" 并不一定"读取", 对于 cat ,echo这样的命令, 打开和读取都是瞬间的,lsof很难捕捉
可以用 inodewatch.stp 来弥补
stap inodewatch.stp major minor inode # 主设备号, 辅设备号, 文件inode节点号
stap inodewatch.stp 0xfd 0x00 523170 # 主设备号, 辅设备号, inode号,可以通过 stat 命令获得
5 IO模拟器
iotest.py # 见附录
开发人员可以 利用 ioprofile (或者 strace) 做详细分析系统的IO路径,然后在程序层面做相应的优化。
但是一般情况下调整程序,代价比较大,尤其是当不确定修改方案到底能不能有效时,最好有某种模拟途径以快速验证。
以为我们的业务为例,发现某次查询时,系统的IO访问模式如下:
访问了A文件一次
访问了B文件500次, 每次16字节, 平均间隔 502K
访问了C文件500次, 每次200字节, 平均间隔 4M
这里 B,C文件是交错访问的, 既
1 先访问B,读16字节,
2 再访问C,读200字节,
3 回到B,跳502K后再读16字节,
4 回到C,跳4M后,再读200字节
5 重复500次
strace 文件如下:
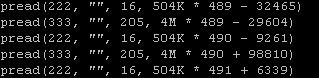
一个简单朴素的想法, 将B,C交错读,改成先批量读B , 再批量读C,因此调整strace 文件如下:
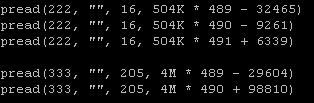
将调整后的strace文件, 作为输入交给 iotest.py, iotest.py 按照 strace 文件中的访问模式, 模拟相应的IO
iotest.py -s io.strace -f fmap
fmap 为映射文件,将strace中的222,333等fd,映射到实际的文件中
===========================
111 = /opt/work/io/A.data
222 = /opt/work/io/B.data
333 = /opt/work/io/C.data
6 磁盘碎片整理
一句话: 只要磁盘容量不常年保持80%以上,基本上不用担心碎片问题。
如果实在担心,可以用 defrag 脚本
7 其他IO相关命令
blockdev 系列
=======================================
blockdev --getbsz /dev/sdc1 # 查看sdc1盘的块大小
block blockdev --getra /dev/sdc1 # 查看sdc1盘的预读(readahead_kb)大小
blockdev --setra 256 /dev/sdc1 # 设置sdc1盘的预读(readahead_kb)大小,低版的内核通过/sys设置,有时会失败,不如blockdev靠谱
=======================================
IO写流程分析二
在Linux 开发中,有几个关系到性能的东西,技术人员非常关注:进程,CPU,MEM,网络IO,磁盘IO。本篇文件打算详细全面,深入浅出。剖析文件IO的细节。从多个角度探索如何提高IO性能。本文尽量用通俗易懂的视角去阐述。不copy内核代码。
阐述之前,要先有个大视角,让我们站在万米高空,鸟瞰我们的文件IO,它们设计是分层的,分层有2个好处,一是架构清晰,二是解耦。让我们看一下下面这张图。
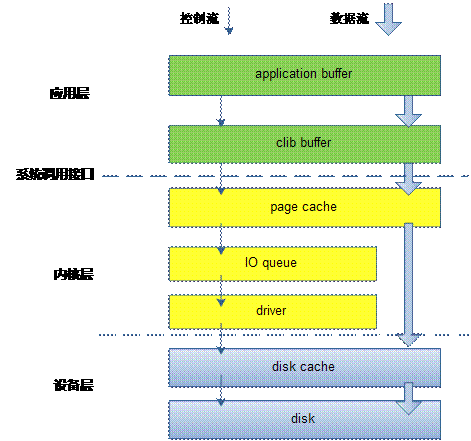
图一
穿越各层写文件方式
程序的最终目的是要把数据写到磁盘上, 但是系统从通用性和性能角度,尽量提供一个折中的方案来保证这些。让我们来看一个最常用的写文件典型example,也是路径最长的IO。
{
char *buf = malloc(MAX_BUF_SIZE);
strncpy(buf, src, , MAX_BUF_SIZE);
fwrite(buf, MAX_BUF_SIZE, 1, fp);
fclose(fp);
}
这里malloc的buf对于图层中的application buffer,即应用程序的buffer;调用fwrite后,把数据从application buffer 拷贝到了 CLib buffer,即C库标准IObuffer。fwrite返回后,数据还在CLib buffer,如果这时候进程core掉。这些数据会丢失。没有写到磁盘介质上。当调用fclose的时候,fclose调用会把这些数据刷新到磁盘介质上。除了fclose方法外,还有一个主动刷新操作fflush 函数,不过fflush函数只是把数据从CLib buffer 拷贝到page cache 中,并没有刷新到磁盘上,从page cache刷新到磁盘上可以通过调用fsync函数完成。
从上面类子看到,一个常用的fwrite函数过程,基本上历经千辛万苦,数据经过多次copy,才到达目的地。有人心生疑问,这样会提高性能吗,反而会降低性能吧。这个问题先放一放。
有人说,我不想通过fwrite+fflush这样组合,我想直接写到page cache。这就是我们常见的文件IO调用read/write函数。这些函数基本上是一个函数对应着一个系统调用,如sys_read/sys_write. 调用write函数,是直接通过系统调用把数据从应用层拷贝到内核层,从application buffer 拷贝到 page cache 中。
系统调用,write会触发用户态/内核态切换?是的。那有没有办法避免这些消耗。这时候该mmap出场了,mmap把page cache 地址空间映射到用户空间,应用程序像操作应用层内存一样,写文件。省去了系统调用开销。
那如果继续刨根问底,如果想绕过page cache,直接把数据送到磁盘设备上怎么办。通过open文件带上O_DIRECT参数,这是write该文件。就是直接写到设备上。
如果继续较劲,直接写扇区有没有办法。这就是所谓的RAW设备写,绕开了文件系统,直接写扇区,想fdsik,dd,cpio之类的工具就是这一类操作。
IO调用链
列举了上述各种穿透各种cache 层写操作,可以看到系统提供的接口相当丰富,满足你各种写要求。下面通过讲解图一,了解一下文件IO的调用链。
fwrite是系统提供的最上层接口,也是最常用的接口。它在用户进程空间开辟一个buffer,将多次小数据量相邻写操作先缓存起来,合并,最终调用write函数一次性写入(或者将大块数据分解多次write调用)。
Write函数通过调用系统调用接口,将数据从应用层copy到内核层,所以write 会触发内核态 / 用户态切换。当数据到达page cache后,内核并不会立即把数据往下传递。而是返回用户空间。数据什么时候写入硬盘,有内核IO调度决定,所以write 是一个异步调用。这一点和read不同,read调用是先检查page cache里面是否有数据,如果有,就取出来返回用户,如果没有,就同步传递下去并等待有数据,再返回用户,所以read是一个同步过程。当然你也可以把write的异步过程改成同步过程,就是在open文件的时候带上O_SYNC标记。
数据到了page cache后,内核有pdflush线程在不停的检测脏页,判断是否要写回到磁盘中。把需要写回的页提交到IO队列——即IO调度队列。又IO调度队列调度策略调度何时写回。
提到IO调度队列,不得不提一下磁盘结构。这里要讲一下,磁头和电梯一样,尽量走到头再回来,避免来回抢占是跑,磁盘也是单向旋转,不会反复逆时针顺时针转的。从网上copy一个图下来,具体这里就不介绍。

IO队列有2个主要任务。一是合并相邻扇区的,而是排序。合并相信很容易理解,排序就是尽量按照磁盘选择方向和磁头前进方向排序。因为磁头寻道时间是和昂贵的。
这里IO队列和我们常用的分析工具IOStat关系密切。IOStat中rrqm/s wrqm/s表示读写合并个数。avgqu-sz表示平均队列长度。
内核中有多种IO调度算法。当硬盘是SSD时候,没有什么磁道磁头,人家是随机读写的,加上这些调度算法反而画蛇添足。OK,刚好有个调度算法叫noop调度算法,就是什么都不错(合并是做了)。刚好可以用来配置SSD硬盘的系统。
从IO队列出来后,就到了驱动层(当然内核中有更多的细分层,这里忽略掉),驱动层通过DMA,将数据写入磁盘cache。
至于磁盘cache时候写入磁盘介质,那是磁盘控制器自己的事情。如果想要睡个安慰觉,确认要写到磁盘介质上。就调用fsync函数吧。可以确定写到磁盘上了。
一致性和安全性
谈完调用细节,再将一下一致性问题和安全问题。既然数据没有到到磁盘介质前,可能处在不同的物理内存cache中,那么如果出现进程死机,内核死,掉电这样事件发生。数据会丢失吗。
当进程死机后:只有数据还处在application cache或CLib cache时候,数据会丢失。数据到了page cache。进程core掉,即使数据还没有到硬盘。数据也不会丢失。
当内核core掉后,只要数据没有到达disk cache,数据都会丢失。
掉电情况呢,哈哈,这时候神也救不了你,哭吧。
那么一致性呢,如果两个进程或线程同时写,会写乱吗?或A进程写,B进程读,会写脏吗?
文章写到这里,写得太长了,就举出各种各样的例子。讲一下大概判断原则吧。fwrite操作的buffer是在进程私有空间,两个线程读写,肯定需要锁保护的。如果进程,各有各的地址空间。是否要加锁,看应用场景。
write操作如果写大小小于PIPE_BUF(一般是4096),是原子操作,能保证两个进程“AAA”,“BBB”写操作,不会出现“ABAABB”这样的数据交错。O_APPEND 标志能保证每次重新计算pos,写到文件尾的原子性。
数据到了内核层后,内核会加锁,会保证一致性的。
性能问题
性能从系统层面和设备层面去分析;磁盘的物理特性从根本上决定了性能。IO的调度策略,系统调用也是致命杀手。
磁盘的寻道时间是相当的慢,平均寻道时间大概是在10ms,也就是是每秒只能100-200次寻道。
磁盘转速也是影响性能的关键,目前最快15000rpm,大概就每秒500转,满打满算,就让磁头不寻道,设想所有的数据连续存放在一个柱面上。大家可以算一下每秒最多可以读多少数据。当然这个是理论值。一般情况下,盘片转太快,磁头感应跟不上,所以需要转几圈才能完全读出磁道内容。
另外设备接口总线传输率是实际速率的上限。
另外有些等密度磁盘,磁盘外围磁道扇区多,线速度快,如果频繁操作的数据放在外围扇区,也能提高性能。
利用多磁盘并发操作,也不失为提高性能的手段。
这里给个业界经验值:机械硬盘顺序写~30MB,顺序读取速率一般~50MB好的可以达到100多M, SSD读达到~400MB,SSD写性能和机械硬盘差不多。
Ps:
O_DIRECT 和 RAW 设备最根本的区别是O_DIRECT是基于文件系统的,也就是在应用层来看,其操作对象是文件句柄,内核和文件层来看,其操作是基于 inode 和数据块,这些概念都是和 **ext2/3 的文件系统相关,写到磁盘上最终是 ext3 **文件。而 RAW 设备写是没有文件系统概念,操作的是扇区号,操作对象是扇区,写出来的东西不一定是 ext3 文件(如果按照 ext3 规则写就是 ext3 文件)。 一般基于 O_DIRECT 来设计优化自己的文件模块,是不满系统的 cache 和调度策略,自己在应用层实现这些,来制定自己特有的业务特色文件读写。但是写出来的东西是ext3文件,该磁盘卸下来,mount 到其他任何 linux 系统上,都可以查看。 而基于 RAW 设备的设计系统,一般是不满现有 ext3 的诸多缺陷,设计自己的文件系统。自己设计文件布局和索引方式。举个极端例子:把整个磁盘做一个文件来写,不要索引。这样没有 inode 限制,没有文件大小限制,磁盘有多大,文件就能多大。这样的磁盘卸下来,mount 到其他 linux 系统上,是无法识别其数据的。 两者都要通过驱动层读写;在系统引导启动,还处于实模式的时候,可以通过 bios 接口读写 raw 设备。