Redis 技术总结
Redis 技术总结
1. Redis简介
- Redis是完全开源免费的, 是一个高性能 (NOSQL)的key-value数据库,Redis是一个开源的使用ANSI C语言编写的可持久换的菲关系型数据库
- 特点:
- 性能极高,存储在数据内存中
- 丰富的数据类型: string,Hash,List,Set
- 原子性: Redis的所有操作都随便原子性的,单个操作是原子性,多个操作也支持事务
- 高速读写,Redis 使用自己实现的分离器,代码量很短,没有lock,因此效率很高
1.1 NoSQL
- 泛指菲关系型数据库,他可以作为关系型数据库的良好补充
- 适合超大规模和高并发的数据带来的难题
- 特点:
- 高可用性 ( 数据之间没有联系 )
- 大规模数据处理效率很高
- 数据类型是多样的 ( 不需要事先设计表结构 )
2. 数据类型
常用命令
- redis 中命令不区分大小写
# 取出值
get key
# 设置值
set key value
# 删除
del key
# 返回所有 key
keys *
# 判断key是否存在
exists key
# 设置key的存活时间(秒)
expire key second
# 查看key值剩余时间
ttl key
# 查看当前key的类型
type key
# 删除库中所有数据
flushdb
# 对数据进行自增/自减,如果不存在,先创建,在自增
incr key/decr key
# 对数据进行指定步进自增/自减
incrby key/decrby key count
五种基本数据类型
string (字符串)
- 建议设置参数
- 表名:主键:字段 value
# 不存在设置成功,存在返回0,分布式锁的解决方案
setnx key valuekey
# 设置key/value,并设置存活时间
setex key time value
# 取出value并截取值(start 开始长度,end 结束长度)
getrange key start end
# 设置指定位置的字符串(替换操作)
setrange key index value
# 返回存储的string长度
strlen key
# 批量存储
mset key1 value1 key2 value2......
# 批量读取
mget key1 key2
# 如果存在值,则返回旧值,然后赋值新值/如果不存在,返回null,然后赋值新值
getset k1 v1
List (列表)
- 栈结构(默认头部插入)
# 插入元素
lpush key value
# 尾部插入元素
rpush key value
# 取出指定位置元素
lindex key index
# 取出指定区间数据(0,-1取出全部)
lrange key start end
# 删除元素
lpop key
# 尾部删除
rpop key
# 移除指定元素 count(移除几个)
lrem key count value
# 返回list的长度
llen key
# 截取list中的元素
ltrim key start end
# 给列表指定位置设置元素,如果元素下标不存在,则报错
lset key index value
# 移除列表的最后一个元素,并将它添加到新的列表,如果新列表不存在,则创建
rpoplpush 列表1 列表2
# 判断列表是否存在
exists key
# 向列表的指定元素前/后插入元素
linsert key before/after value1 value2
Set (集合)
- 元素不能重复
# 添加元素
sadd key value
# 查看指定set的所有值
smembers key
# 判断是否在set集合中
sismember key
# 获取set集合中的元素个数
scard key
# 移除指定元素
srem key value
# 随机抽取指定个数的元素
srandmember key count
# 随机移除元素
spop key
# 将集合中的指定元素添加到新的集合
smove key1 key2 value
# 数学集合操作
-- 差集: sdiff key1 key2
-- 交集: sinter key1 key2
-- 并集: sunion key1 key2
Hash (哈希)
- Map集合,key-value,value是一个map集合
- 数据结构: key filed value
# 存储数据
hset key field value
# 获取数据
hget key field
# 批量存储
hmset key field1 value1 field2 value2 ...
# 批量取出
hmget key field1 field2 ...
# 删除指定字段
hdel key filed
# 获取所有数据
hgetall key
# 取出所有field
hkeys key
# 取出所有value
hvals key
# 查看集合长度
hlen key
# 判断指定field是否存在
hexists key field
# 自增/自减,指定步进
hincrby/hdecrby key field count
# 添加指定数据,不存在则添加
hsetnx key field value
Zset (有序集合)
- 在set的基础上,增加了一个值, key score vlaue
# 添加数据
zadd key score value
# 添加多个数据
zadd key score1 value1 score2 value2
# 获取指定区间中的数据
# 默认从小到大
zrange key start end
# 从大到小
zrevrange key start end
# 排序查询
# 升序
zrangebyscore key -inf +inf
# 升序,并显示所有数据
zrangebyscore key -inf +inf withscores
# 升序,并显示所有数据,规定最大值/最小值
zrangebyscore key count/-inf count/+inf withscores
# 删除指定元素
zrem key value
# 获取集合中的个数
zcard key
# 获取指定区间中的成员数量
zcount key
总结
set和zset add/一般不取值/rem/card
string/hash set/get/del/len
list push/pop/rem/len
三种特殊数据类型
geospatial 地理位置
# 添加地理位置
# 两极的数据无法添加,一般使用java一次性录入所有数据
geoadd key 经度 纬度 vlaue
# 获取地理位置
geopos key value1 value2
# 获取两地之间的距离
-m 表示单位为米。
-km 表示单位为千米。
-mi 表示单位为英里。
-ft 表示单位为英尺。
geodist key value1 value2 m
# 根据给定经纬度为中心,来进行查询
-WITHDIST: 在返回位置元素的同时, 将位置元素与中心之间的距离也一并返回。
-WITHCOORD: 将位置元素的经度和维度也一并返回。
-asc: 从近到远
-desc: 从远到近
georadius key 经度 纬度 距离 距离单位 参数 排序
# 查询指定元素周围的元素
GEORADIUSBYMEMBER key value 距离 距离单位
# geo的底层是封装的zset
# 查看所有value
zrange key start end
# 删除指定元素
zrem key value
Hyperloglog
- 基数: 不重复的元素,可以接受误差
- 常用于网站的页面访问统计
- 优点: 固定的内存: 12kb
# 创建一组元素
pfadd key v1 v2 v3 v4
# 统计指定key中的基数
pfcount key
# 合并两组数据(key)
pfmrge 目标key key1 key2
Bitmap
- 位运算
- 统计用户信息,活跃,不活跃,登录,未登录
- 只能存储两个状态: 0 和 1
# 存储数据
setbit key value(0/1)
# 取出数据
setbit key
# 计数
bitcount key -默认计数全部
bitcount key start end
3. Redis 事务
- 简介:
- Redis单条命令保证原子性,但是事务不保证原子性!!!
- 本质: 一组命令的集合,依次执行
- 特定: 一次性, 顺序性, 排他性,执行一列中的命令
- 将一个列中的命令序列化,按照顺序的串行化执行
- 执行过程不会被其他命令插入,但是不能回滚事务
- Redis单条命令保证原子性,但是事务不保证原子性!!!
# 标记一个事务的开启
MULTI
-------------书写命令-------------
# 执行所有事务块内的命令
EXEC
# 取消事务,放弃执行事务块内的所有命令
DISCARD
# 异常:
- 编译时异常: 所有命令都不会执行(队列会被放弃)
- 执行报错: 出错的命令报错,其他的命令正常执行
乐观锁
- CAS实现机制: watch
# redis监视
# 开启监视/加锁
watch key
# 开始事务
multi
-----执行命令---------
# 提交事务
exec
# 如果其他线程修改了数据,事务提交失败
# 释放锁,只有释放了锁,才能重新加上锁
unwatch
4. Spring Boot 整合 Redis
-
导入jar包
org.springframework.boot spring-boot-starter-data-redis -
导入yml文件
spring: redis: host: 127.0.0.1 port: 6379 -
注入
@Resource private StringRedisTemplate stringRedisTemplate; @Resource private RedisTemplate redisTemplate;
5. Redis 持久化
-
RDB (默认开启):
- 快照方式持久化,在指定的时间隔内将内存中的数据集写入磁盘
- 数据恢复: 将文件放到启动的根目录下
- 优点:
- 适合大规模的数据恢复,对数据的完整性和一致性要求不高
- 缺点:
- 但是可能会导致最后一次快照的数据丢失
- 实现原理:
- fock 一个子进程,子进程把所有的数据都写入一个临时文件(.rdb),等到持久化完成后,就用这个临时文件替换上一个持久化的文件,在这期间主进程不进行任何IO操作,保证了效率
- 快照方式持久化,在指定的时间隔内将内存中的数据集写入磁盘
-
AOF (默认不开启):
-
将每一个收到的写命令都追加到文件中,恢复文件就是将文件中的命令全部执行一遍
- 本质上就是在无限追加命令,当一个文件的大小超过规定到的大小时,就会fock一个新的线程来进行追加操作
-
优点:
- 保证了数据的完整性
-
缺点:
- 影响系统的性能,消耗大量的磁盘空间,修复数据的速度很慢
-
数据修复:
redis-check-aof --fix # 本质上是删除出错的命令 -
策略:
- 每次修改同步
- 每次秒钟同步
- 从不同步
-
6. Redis 发布订阅
-
Redis 发布订阅(pub/sub)是一种消息通信模式: 发送者(pub)发送消息,订阅者(sub)接收消息
-
Redis客户端可以定义任意数量的频道
- 发布者、订阅者、频道
# 订阅一个或多个符合给定模式的频道(订阅者) psubscribe pattern ... # 将消息发送到指定的频道(发布者) publish channel message # 查看订阅与发布系统状态 pubsub subcommand argument ... # 订阅给定的一个或多个频道信息 subscribe channel ... # 退订指定的频道 unsubscribe channel ... # 退订所有给定模式的频道 subscribe channel ... -
原理解释:
- redis - serve 中维护了一个字点,字典的键就是一个个频道,而键对应的值就是一个链表,链表中保存了所有订阅了这个频道的客户端。
- subcribe 命令就是将客户端添加到对应频道的链表中
7. Redis 主从复制
-
将一台Redis服务器的数据,复制到其他Redis服务器,前者称为主节点(master、leader),后者称为从节点(slave、follwer;数据的复制都是单向的只能从主节点到从节点,Master以写为主,Slave以读为主
-
作用:
- 数据冗余:实现了数据的热备份,是持久化之外的一种数据冗余方式
- 故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复,实际上是一种服务的冗余
- 负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供服务
- 高可用:除了上述作用以外,主从复制还是哨兵模式和集群能够实施热部署的基础,因此可以说主从复制是Redis高可用的存储内存
-
配置 Redis 集群:
-
集群方式:一主多从、层层链路
-
修改配置文件(redis.conf):
- 端口
- pidfile 名称
- log 文件名称
- dump.rdb 名称
-
Redis 每个服务都默认自己是主节点,所以只需要配置从节点
-
命令配置的都只是暂时的,真实的环境下应该是修改配置文件
# 查看当前服务信息 127.0.0.1:6379> info replication # Replication role:master # 默认主节点 connected_slaves:0 # 连接从节点的个数 master_repl_offset:0 repl_backlog_active:0 repl_backlog_size:1048576 repl_backlog_first_byte_offset:0 repl_backlog_histlen:0 # 把当前服务指向一个主机(配置丛集) slaveof ip port # 把当前节点变为主节点 slaveof no one -
-
复制数据原理:
- Slave 启动成功连接到 master 后会发送一个 sync 同步命令,Master 接到命令,启动后台的存盘进程,同时收集所有接收到的用于修改的命令,在后台进程执行完毕后,Master 将传送整个数据文件到 salve,并完成一次完全同步
- 全量复制:
- 当 Salve 服务接受到数据库的文件后,就会将其加载到内存中
- 增量复制:
- Master 继续将新的所有收集到的修改命令一次传给 Savle,完成同步
哨兵模式
-
是一个独立的进程,会单独运行,原理是哨兵模式通过发送命令,等待 Redis 服务器响应,从而监控多个 Redis 实例
- 通过发送命令,让Redis服务器返回监控其运行状态,包括主服务器和从服务器。
- 当哨兵监测到master宕机,会自动将slave切换成master,然后通过发布订阅模式通知其他的从服务器,修改配置文件,让它们切换主机。
-
通常是用个哨兵来搭建集群,以防止哨兵进程出现问题
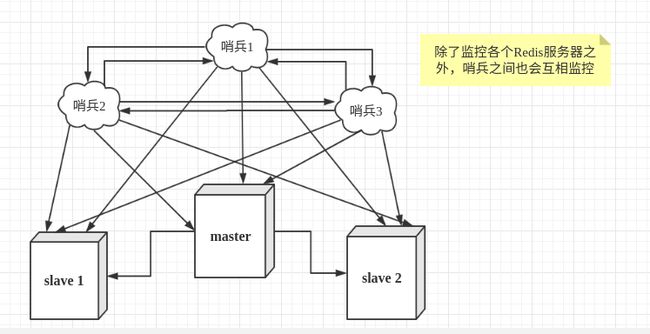
-
故障切换的过程:
-
假设主服务器宕机,哨兵1先检测到这个结果,系统并不会马上进行failover过程,仅仅是哨兵1主观的认为主服务器不可用,这个现象成为主观下线。当后面的哨兵也检测到主服务器不可用,并且数量达到一定值时,那么哨兵之间就会进行一次投票,投票的结果由一个哨兵发起,进行failover操作。切换成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机,这个过程称为客观下线。这样对于客户端而言,一切都是透明的。
-
修改配置文件: sentinel.conf
# 禁止保护模式 protected-mode no # 配置端口(默认端口)如果配置多个哨兵需要修改 port 26379 # 配置监听的主服务器,这里sentinel monitor代表监控,mymaster代表服务器的名称,可以自定义,192.168.11.128代表监控的主服务器,6379代表端口,2代表只有两个或两个以上的哨兵认为主服务器不可用的时候,才会进行failover操作。 sentinel monitor mymaster 192.168.11.128 6379 2 # sentinel author-pass定义服务的密码,mymaster是服务名称,123456是Redis服务器密码 # sentinel auth-pass -
启动哨兵:
# 启动哨兵进程 ./redis-sentinel ../sentinel.conf
-
8. 高并发下缓存可能引起的问题
缓存穿透
-
key 对应的数据并存在,导致每次都需要去数据库中查找,对数据库造成了压力,严重可能造成服务瘫痪
# 解决方案: - 最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被 这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。 - 如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。
缓存击穿
-
key 对应数据存在,但是失效了,导致大量请求去数据库中进行查询,造成数据库的压力
-
对某一个热点数据的大量查询,设置热点数据永不失效
# 出现场景: - key值可能会在某些事件被大量访问,是一些非常热点的数据 # 解决方案: - 使用互斥锁 (mutex key) - 在缓存失效的时候,不是立刻重新进行缓存,而是先setnx 一个值,判断当前线程是否在操作redis,然后再重新进行缓存,并删除刚刚设置的setnx, - 注意: 需要对setnx的值设置失效时间,防止del失败,下一次key值失效时,无法进行处理 @Test public void test() { ValueOperations<String, String> opsForValue = stringRedisTemplate.opsForValue(); String key = opsForValue.get("key"); // key未获取到,可能是key值 不存在/失效 的原因,需要做缓存穿透/击穿的策略 if (key == null) { // 互斥锁,找出当前是哪一个线程在操作缓存 if (opsForValue.setIfAbsent("key_temp", "temp", 15, TimeUnit.SECONDS)) { String temp = "查询到的数据"; // 防止缓存穿透 if (temp == null){ // 给当前缓存设置一个空值 opsForValue.set("key",""); } // 从数据库中读取数据并写入缓存 opsForValue.set("key", temp); // 删除临时的key,并且在设置的时候给key设置一个过期时间,防止删除失败造成的下一次缓存击穿策略失效 stringRedisTemplate.delete("key_temp"); } else { // 说明已经有线程在操作缓存了,休息一会,重新调用 sleep(50); opsForValue.get("key"); } } }
缓存雪崩
- 缓存服务器重启或key值大面积同一时间失效,造成大量线程同时访问数据库,引起宕机
- 解决方案:
- Redis 高可用:
- 既然 Redis 有可能挂掉,那就搭建服务集群(异地多活)
- 限流降级:
- 在缓存失效后,通过加锁或者列队来控制线程的数量,比如么某个 Key 只允许一个线程查询数据的写缓存,其他线程等待
- 数据预热:
- 数据加热的含义就是正式部署之前,先把可能加载到的数据线访问一遍,这个大量的数据就会加载到缓存中,设置不同的过期时间(随机),让缓存实现时间分布均匀
- Redis 高可用: